
Scalable, High-Performance Native Snapshots in the vSAN Express Storage Architecture

The snapshot architecture used in previous editions of vSAN can be thought of as an enhanced form of a redo-log based snapshot architecture that has been a part of vSphere for many years. While vSAN introduced the “vsanSparse” snapshots to alleviate some of the technical implications of traditional, redo-log based snapshots, these improvements had limits in meeting today’s requirements in performance, scalability, and use cases. It is not uncommon for today’s customers to want to use snapshots for not only backups, but retain them for longer periods of time to support automation workflows such as Continuous Integration/Continuous Delivery (CI/CD), Copy Data Management (CDM), and virtual desktop management using VMware Horizon.
A bit of snapshot history
VMFS Snapshots
While VMware snapshots re powerful and enable unique data protection and workflows, they also have carried operational risk. A VMware administrator who has stumbled upon a multi-TB snapshot, alarms for “consolidation needed”, or a large deep chain of snapshots on a critical database often has an immediate sense of dread.
VMFSsparse was the default for VMFS5 with disks under 2TB and the default for all disks prior to VMFS5. VMFSsparse is implemented on top of VMFS as a redo-log that starts empty, immediately after a VM snapshot is taken. The redo-log expands to the size of its base vmdk. Starting with VMFS5 for disks larger than 2TB, and for all VMFS6 VMDKs a VMFS SEsparse snapshots were introduced. Fundamentally SEsparse was an evolutionary improvement that allowed for greater space efficiency but had negligible impacts on snapshot merge performance, or performance with deep long running snapshot chains. Additional improvements in the past have also reduced impact and stun times over the years such as the mirror driver. Still, all of these improvements were incremental and did not change the advise to not keep snapshots open for more than 48 hours, or use deep snapshot chains on latency sensitive workloads.
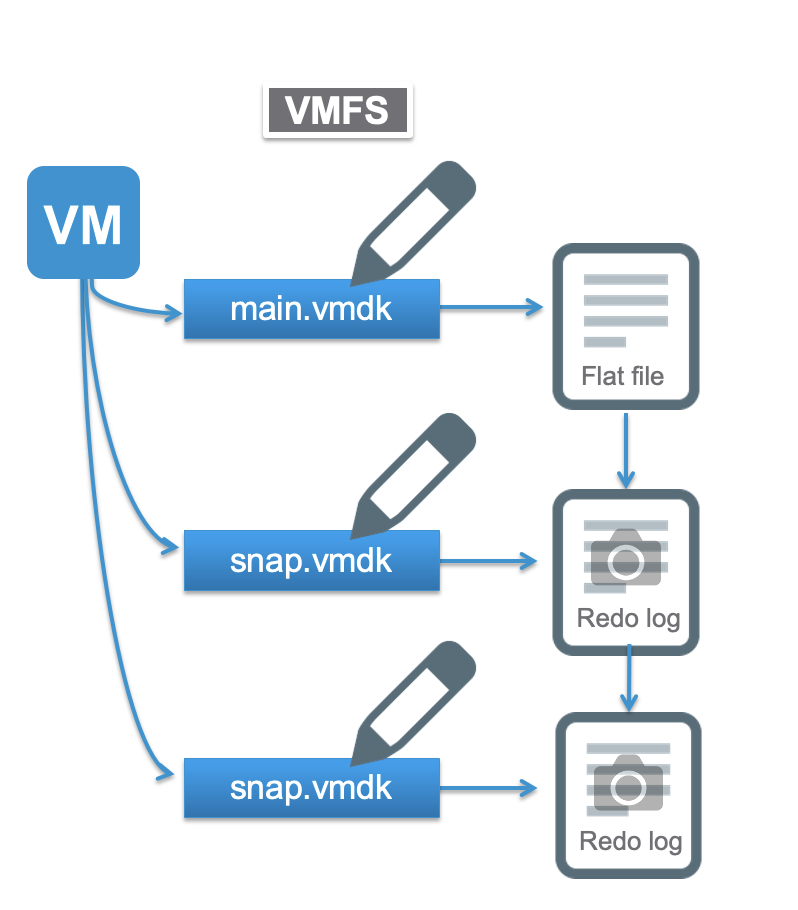
vSAN Snapshots
The snapshot architecture used in previous editions of vSAN can be thought of as an enhanced form of a redo-log based snapshot architecture that has been a part of vSphere for many years. vSAN 5.5 used VMFS snapshots, While vSAN 6 introduced the “vsanSparse” snapshots to alleviate some of the technical implications of traditional, redo-log based snapshots. Memory caches reduced read performance impacts but still stun times and long running snapshot merges remained an issue.
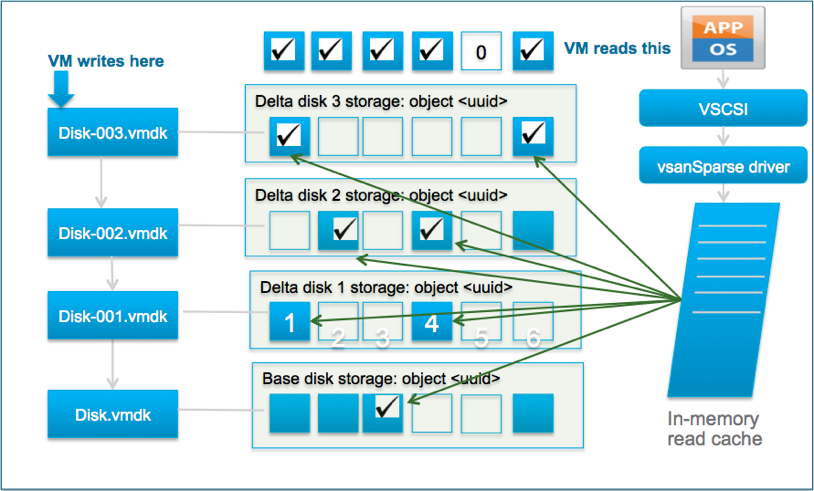
vSAN ESA Snapshots
With vSAN 8, when using the ESA, snapshots are achieved using an entirely different approach from past editions. Instead of using a traditional “chain” of a base disk and delta disks, the snapshot mechanism uses a highly efficient lookup table using a B-Tree. The log structured file system of the vSAN ESA allows for incoming writes to be written to new areas of storage with the appropriate metadata pointers providing the intelligence behind which data belongs to which snapshot. Snapshot deletion times were over 100x faster than previous versions of vSAN snpashots. The new architecture prevents any need of the computational and data movement effort found in a traditional snapshot deletion. Snapshot deletions, merges, or consolidations were one of the most resource intensive activities found in the traditional redo-log architecture, but also one of the most common activities due to how most snapshots are used. When a snapshot is deleted in vSAN 8 using the ESA, the snapshot delete action is largely just a metadata delete activity. It is immediately acknowledged after logically deleted, and at a later time (asynchronously), the metadata and data will be removed. The new architecture allows for nearly limitless snapshots. However, due to vSphere limitations at this time, the limit right now is set to 32 snapshots per object.
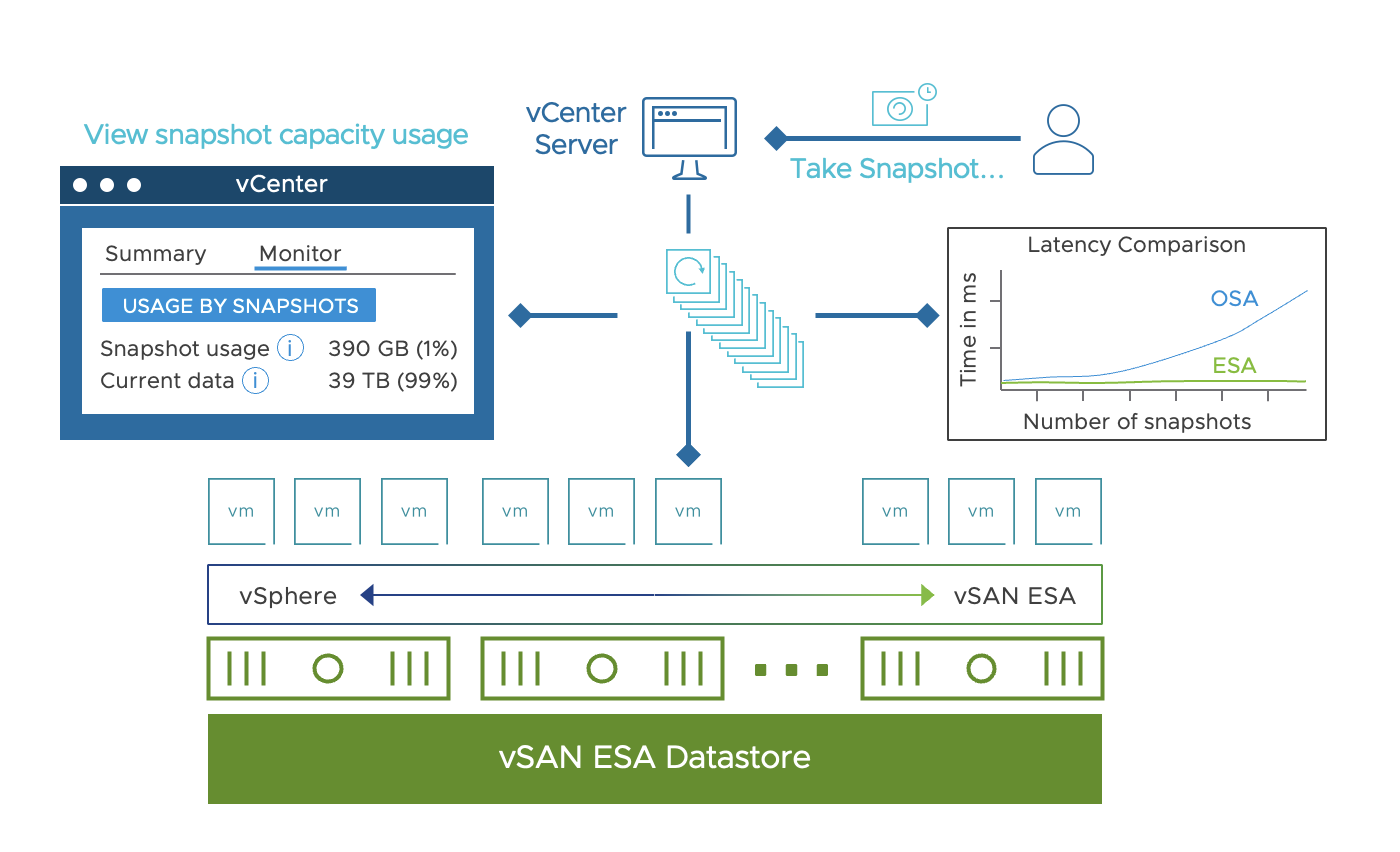
Data Protection
The most common use of snapshots is for data protection. Backup software using vSphere Storage APIs (Commonly called VADP) will leverage the new vSAN ESA Snapshots automatically as they functionally replace the old snapshots. While vSphere Replication will still use its own replication engine, customers will see a significant benefit when running SRM & vSphere Replication on clusters powered by the vSAN ESA. The is because the process of snapshot consolidations to a base disk are so much more efficient in the ESA when compared to the classic redo-log approach of vsanSparse. With the classic redo-log approach, a significant amount of changed data can accumulate in the child disks, making for an intrusive process when performing any sort of consolidation.
Conclusion
vSAN ESA is a powerful, flexible new architecture. The new high performance snapshots enable flexibility without compromising performance. While viewed as a relatively low level feature they should help accelerate new automation and data protection workflows. Combined with the new vSAN 8 ESA performance improvements, other low level improvements to vSphere 8 it is time to start planning vSAN 8 deployment today.