
Improved Uptime for Stretched Cluster and 2 Node cluster
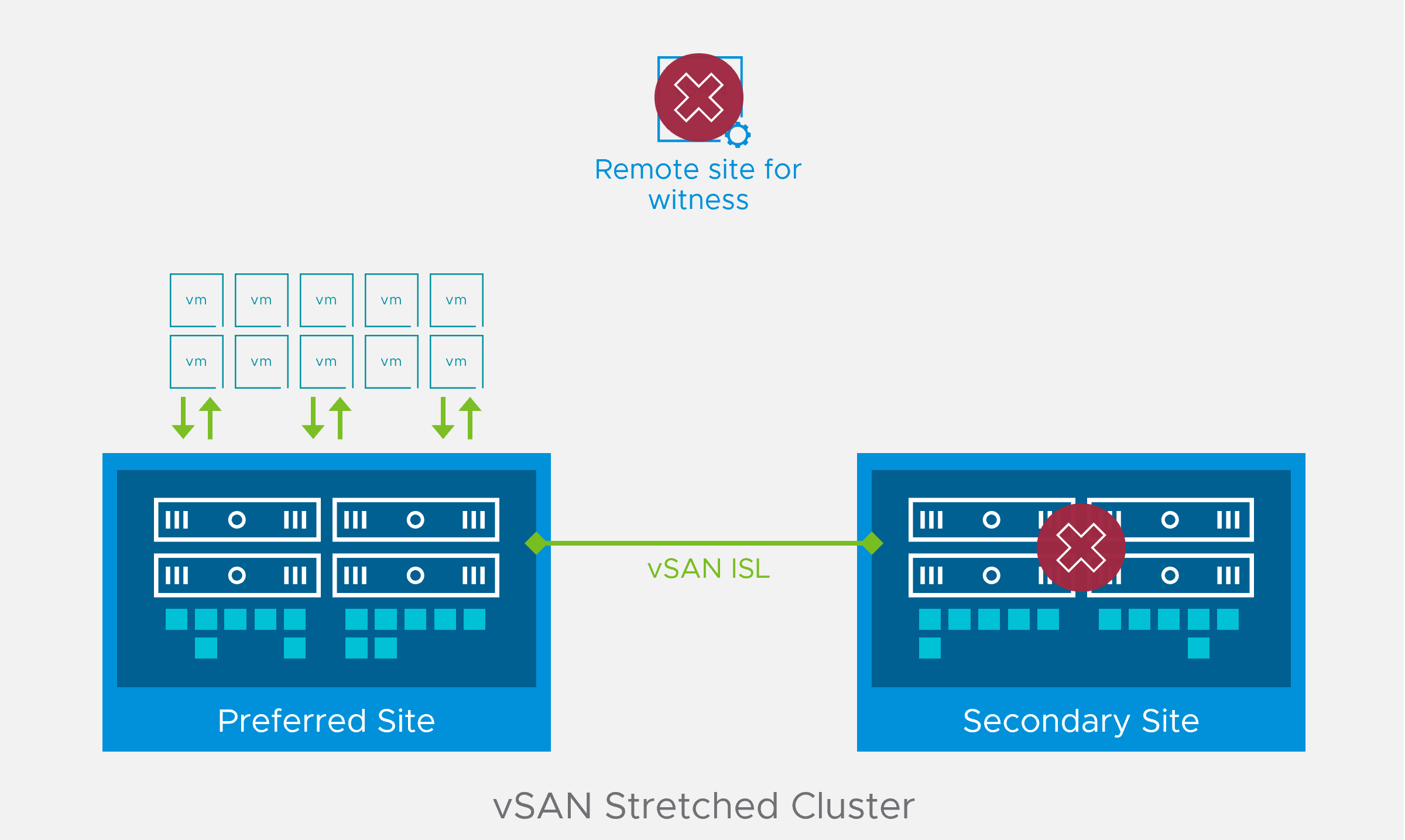
Often, administrators need to place an entire stretched cluster site in maintenance mode for upgrades or planned tests. An entire site might also go down due to unexpected reasons like power outages. During the time one of the sites is offline the VMs will be running on the surviving site of the stretched cluster or the 2 Node cluster, during this time the cluster becomes more vulnerable to any additional site failures. In vSAN 7 Update 3, if the cluster experiences a witness site fault after one of the sites has already been deemed unavailable, vSAN will continue maintaining data availability for the workloads running inside the stretched cluster or the 2 Node cluster.
The voting mechanism
This resilience enhancement has been achieved by modifying the voting mechanism in the cluster. These changes enable vSAN to assign most of the votes to the VM object replicas on the surviving site. These readjustments remove the dependency on the witness site. Thus, the remaining site objects can start forming a quorum after the first site has been deemed offline, including being offline in maintenance mode, and maintain resilience for the VMs running inside the stretched cluster even if the witness site goes down unexpectedly. It may take up to a couple of minutes to process all the work items and update the votes of all the objects before which we can tolerate the witness appliance failure. The original voting mechanism is restored once all the hosts are back to operational.
The graphic below showcases a possible voting mechanism for a single VMDK object. For simplicity, we’re going to take an example with an object that has a Site disaster tolerance =1 with RAID 1 applied. Note that these vote numbers are only a representation of the voting ratio. As a starting point, both sites’ components, on Site A and Site B, possess an equal number of votes, 1 vote per site. The witness site object originally gets the most votes – 3 votes. As described, the adjustments in the voting mechanism will be triggered by a planned or unplanned site failure. After the fault event, most of the votes will be assigned to the remaining site, in this example, 3 votes will be assigned to Site A. Now, the remaining site can form a quorum and maintain site resiliency for the VMs running inside the stretched cluster, even in case of an additional witness site failure.
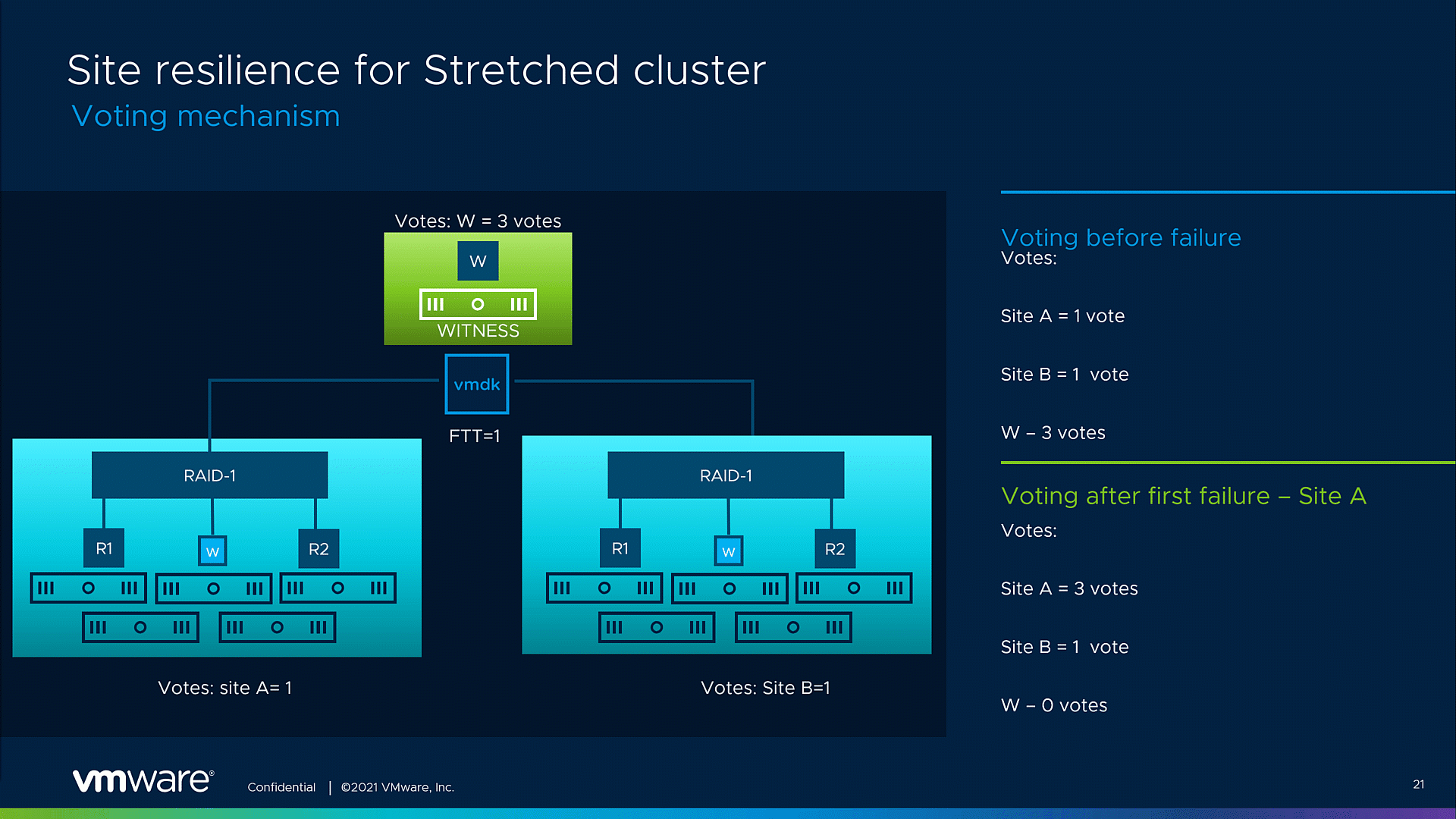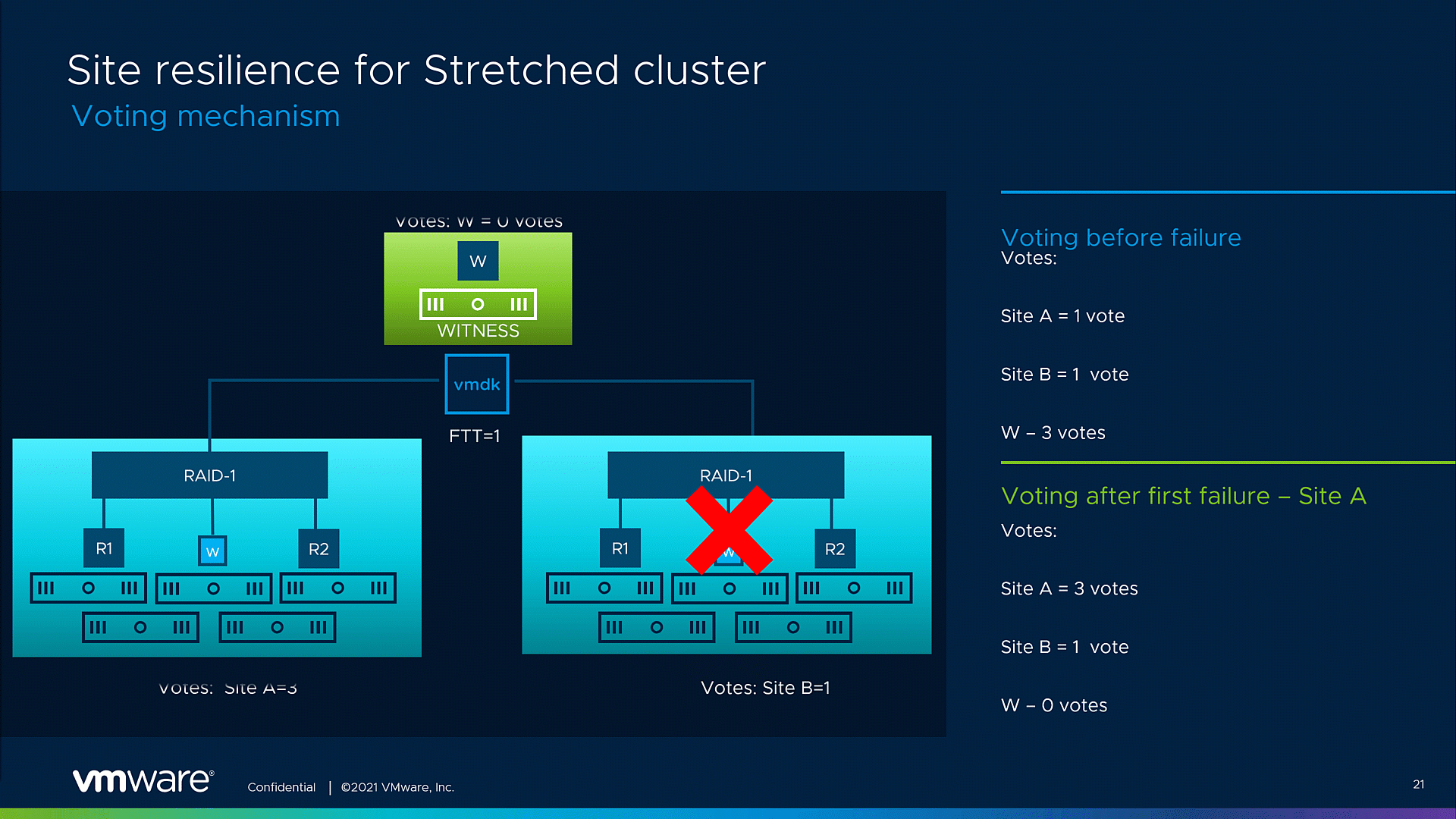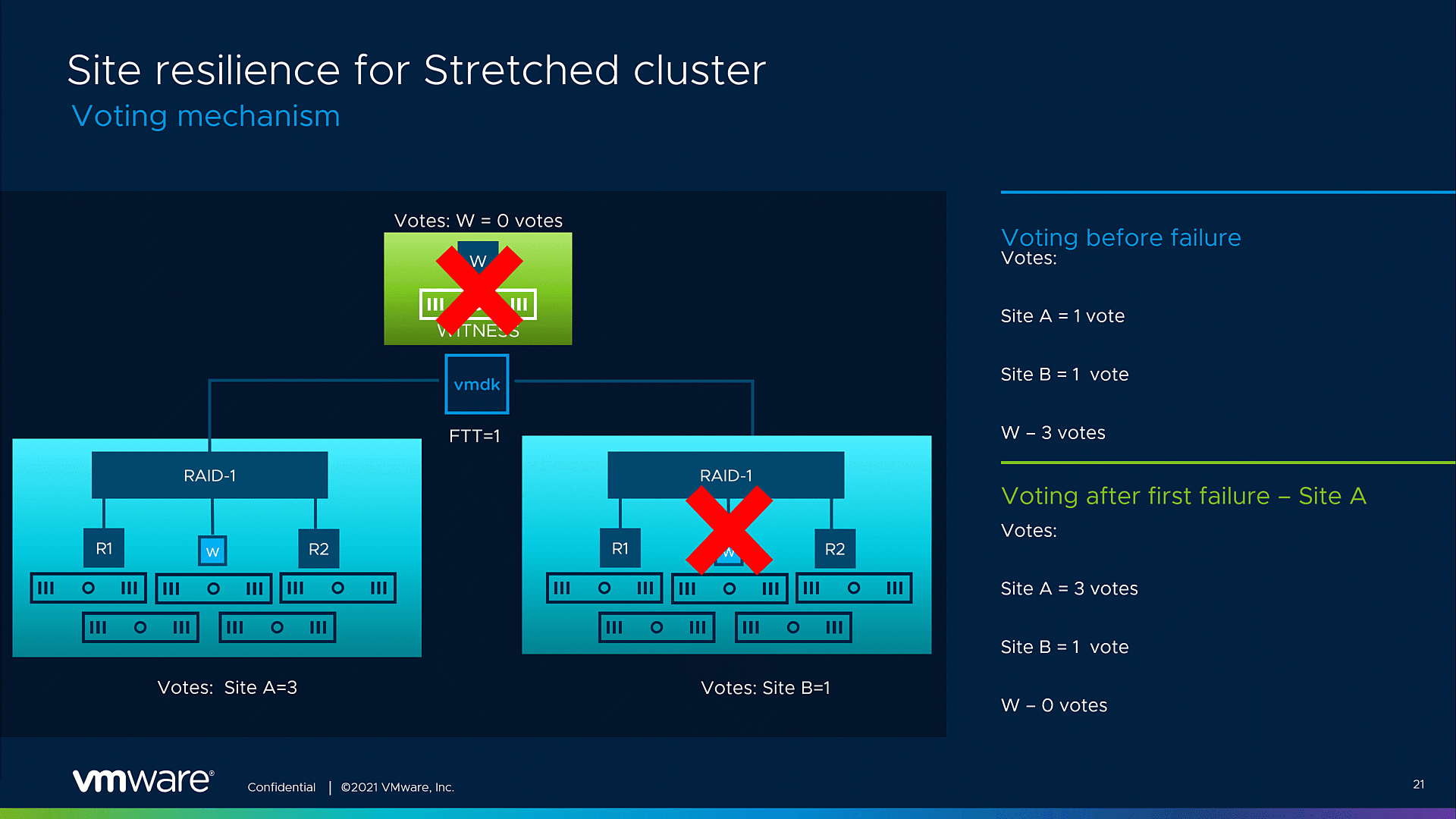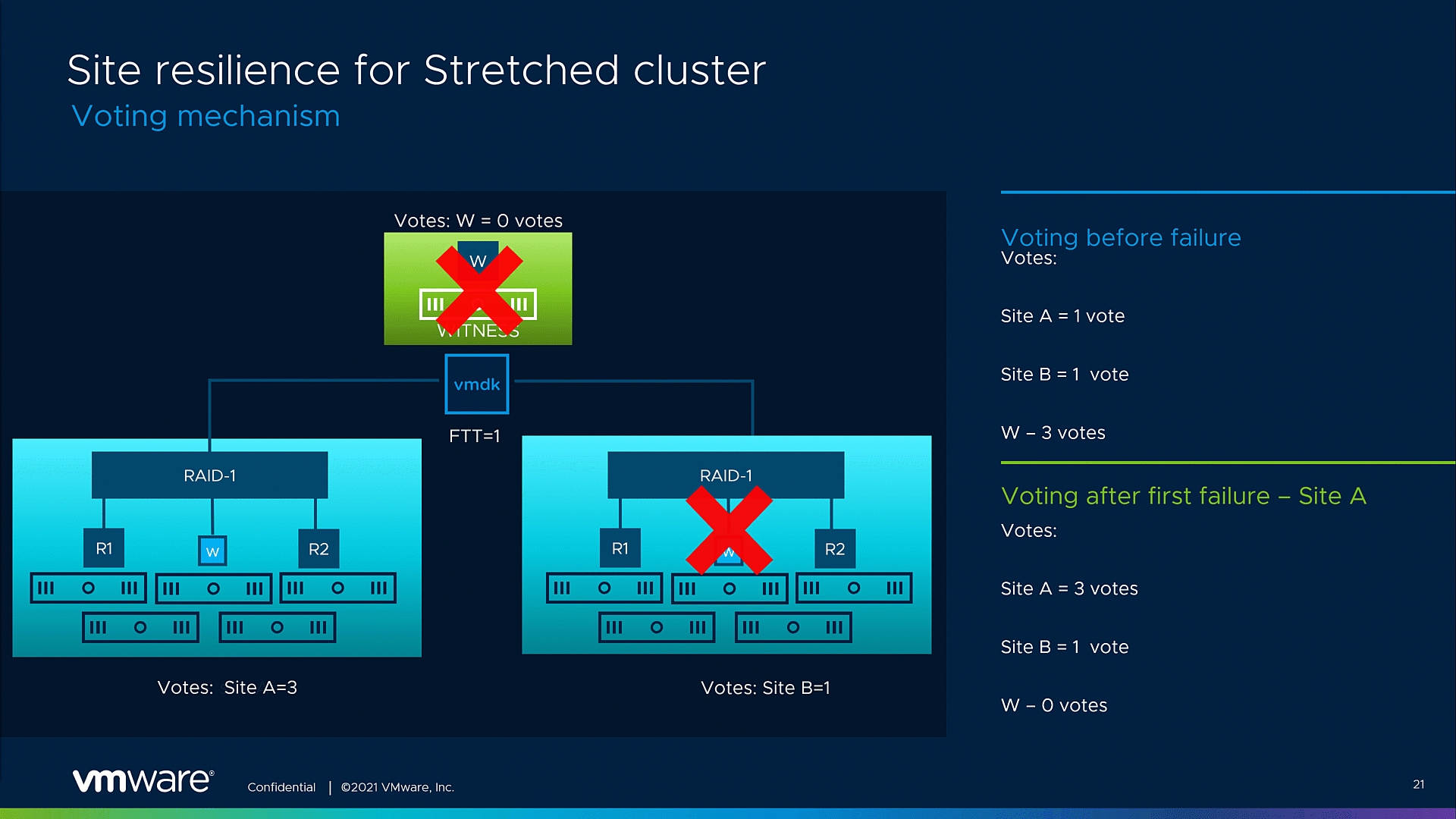
Fig.1. Improved resilience for stretched clsuter voting mechanism
Avoiding split-brain scenario
There’s one logical question that might arise here – “How do we avoid a split-brain scenario in this specific event?” vSAN resolves this potential vulnerability by allowing the witness site to record the information about the new vote’s layout. This awareness allows the witness site to reject any attempts for a sub-cluster creation with the originally failing Site B because it knows Site B does not have enough quorum to form a cluster with the witness site.
New object status has been introduced in the UI to indicate the changed condition of the VM objects after the fault event:
- Without Improved Site resiliency – the object status is shown as “Inaccessible”
- With Improved Site resiliency - the “Reduced availability with no rebuild - daily timer”
Keep in mind that this feature is not applicable for VM objects whose policy consists of no level of replication, meaning having a policy with PFTT = 0, and it is only applicable to stretched clusters and 2 Node clusters topologies. Furthermore, vSAN will only adjust the votes if the VM object has lost all its replicas, and there are no durability components available for this object replica. This adjustment can be performed only when the witness failure occurs after the first site has been pronounced as offline.
Summary
This new capability makes vSAN Stretched cluster and vSAN 2 Node cluster deployments even more resilient to failure events and maintains data availability when there is a planned or unplanned site outage followed by a planned or unplanned unavailability of the witness host.