
Machine Learning on vSphere — What Have We Done for You Lately? — What Will VMworld Do for You Next?
INTRODUCTION
This introduction was running longer than Herman Wouk's Winds of War, the pre-WWII novel setting up his WWII novel, War and Remembrance. The original introduction tried to lay a lot of AI/ML groundwork prior to discussing the vSphere offerings that support it. So I've rewritten it as a set of bullet point assertions. If you believe these assertions without lengthy (and compelling!) explanations, you might enjoy the remaining, lengthier blog body making the case for running your AI/ML applications (Artificial Intelligence/Machine Learning) on vSphere and setting up the case we will be making for vSphere at VMworld 2021. I'll point to some of the AI/ML catalog sessions there as we go along.
- AI/ML is important, big, and growing—in every industry. You will be assimilated.
- AI/ML applications cry out to be run with hardware acceleration (GPUs predominate the space today)
- You will be miserable unless you run these apps in a virtual environment, and most likely with Kubernetes, including VMware's offering, VMware vSphere with Tanzu (including TKG)
- They are modern apps. You'll need all the flexibility, agility, and orchestration you can get.
- You'll need to share the precious physical resources—GPUs are often underutilized, perhaps seeing only 15% utilization
This blog takes a survey of and describes the VMware vSphere support, features, and efforts to make ML work for you.
I have broken everything up into four categories:
— How to give your VM a GPU
— How to run your containers
— What else you need for AI/ML
— What the NVIDIA AI for Enterprise (NVAIE) partnership gives you
ACCELERATORS
Data center administrators appreciate vSphere, our virtualization suite, for many reasons. A short list includes, ease of provisioning individualized VMs to run applications, having applications share expensive resources, ease of cloning and backing up VMs, high-availability, and disaster recovery. Administrators want the same benefits for their ML apps.
For machine learning, vSphere's first, most critical job is to let you (your application) access hardware accelerators. ML applications crunch a tremendous amount of data, but in ways very amenable to parallel processing. Running on a regular CPU, the apps take hours or days to run. The NVIDIA GPUs are the most popular accelerators today.
When machines are virtualized, products like vSphere give OSes and applications the illusion that they own some underlying processor. But this is insufficient. The software also needs access to things such as keyboards, displays, network interfaces, storage and more. vSphere provides virtualization, the illusion of ownership, of these as well. The GPU needed for ML acceleration is a hardware device sitting on a PCIe bus and vSphere has a way to passthrough PCIe devices to any designated VM. For NVIDIA GPUs in particular, it has ways of sharing them with more than one VM at a time.
Plus, VMware's vSphere Bitfusion offers a distinct and separate virtualization approach where passing GPUs through to the VM is not needed. Bitfusion pools GPUs for remote, dynamic allocation and use by any machine with no hypervisor touch at all.
Let's take a look at these three methods.
1. Passthrough with DirectPath IO
DirectPath IO is the vSphere feature name for PCIe passthrough—passing devices to VMs. It assigns an actual physical device to one and only one VM when that VM powers up. That device is then unavailable to any other VM. The hypervisor has a very light touch on accesses through DirectPath IO, so little effect on performance can be expected. The VM needs to install the same device driver as a bare metal machine, and no device driver is required in ESXi (the hypervisor).
- Of note: vSphere 7 supports Dynamic DirectPath IO — Allows DRS (Distributed Resource Schedule) to do the initial placement of VMs onto particular host machines with passthrough devices, without requiring devices (e.g. GPUs) have matching PCIe addresses on each host.
- Of note: some PCIe device have virtual functions under SR-IOV, a capability to appear to the system as multiple devices, even while those parts (virtual functions) share the hardware. For example, a NIC card with only a single ethernet port, could appear on the PCIe side as separately addressable NICs. The hardware would schedule the ethernet frames from the different virtual functions onto the single ethernet cable. vSphere will allow you to pass virtual functions of SR-IOV GPUs through to different VMs. Be sure to find and install the host (hypervisor) drivers into ESXi that SR-IOV devices require.
2. vGPU and MIG
NVIDIA builds GPUs and provides drivers that allow GPUs to be partitioned and assigned to multiple VMs. They offer two general ways of partitioning. Current and legacy GPUs offer vGPU which divides GPU memory into partitions (50%, 25%, or 12.5% of memory) and then offers time-sliced access to the GPU cores. Equal Share and Fixed Share time-slicing options are available.
The Ampere family of GPUs offers models (e.g. A100 and A30) with a MIG mode. MIG partitions compute resources (cores) as well as memory. The smallest slicing on an 80 GB A100 is one-seventh of the compute cores with one-eighth of the memory (10 GB). A physical Ampere GPU can be configured for MIG mode, but defaults to a time-sliced mode.
- If time-slice mode is configured, vCenter users will be able to assign time-sliced vGPU profiles to the VMs on that host
- If MIG mode is configured, vCenter users will be able to assign MIG vGPU profiles to the VMs on that host
Both the time-sliced form and the MIG form (using spatial separation instead of time) of vGPU backing mechanisms require a device driver for ESXi, plus a separate vGPU device driver for the OS in the VM. This only introduces slightly more overhead than DirectPath IO, but in exchange you get GPU virtualization and support for vMotion.
As there are a number of configurations and combinations of partitions possible, we will not try to cover all aspects and details here. See these links for more on vGPU and MIG.
At VMworld look to session VI2222
- Of note: vSphere supports vMotion of VMs with vGPU. In this case, vMotion is limited to working on VMs with at most four vGPU profiles.
3. Bitfusion
VMware's vSphere Bitfusion takes a very different approach. Instead of actually connecting a VM to a device on the host's PCIe device, it sets up an environment wherein Bitfusion intercepts all the application calls to the GPUs. Bitfusion then diverts the calls along with the data they reference, sending them across the network to an entirely different VM that does have access to a GPU.
This target VM runs a Bitfusion server, usually on a different host, and accesses the GPU on behalf of the application. So Bitfusion is a client-server architecture. The Bitfusion clients first request GPUs (or slices of GPUS) from one of a set of remote Bitfusion servers; second, when the GPU allocation succeeds, the Bitfusion clients run the ML application in the Bitfusion interception environment—the application behaves as if it had local GPUs (the app does not have to be refactored or recompiled); third, Bitfusion detects application completion and frees the remote GPUs (or slices) making them available, again, to all Bitfusion clients.
It is important to emphasize the dynamic nature of the allocation here. Because the servers have permanent GPU assignments, clients can allocate and free GPUs without having to power up and power down. You can have a high ratio of clients to servers as they access GPUs on an as-needed basis. You can have more applications and clients than would fit on the hosts with GPUs.
Bitfusion works for training, for inference, in the data center, and at the edge.
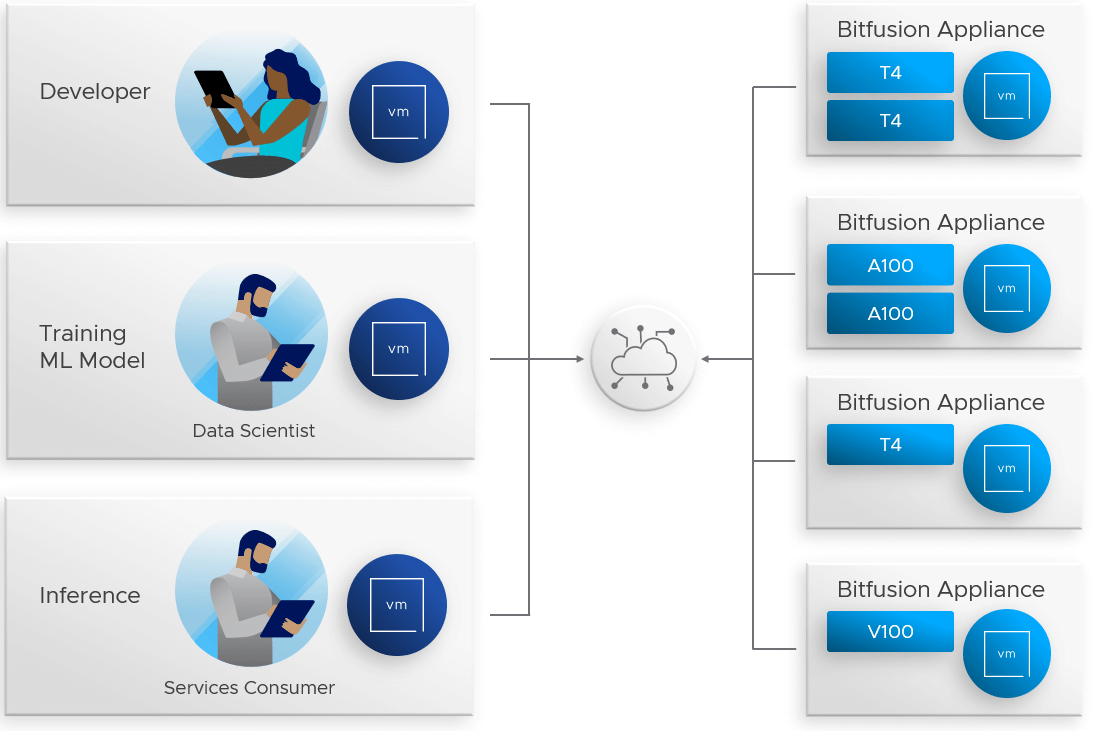
Bitfusion clients run ML applications locally on the left, using remote GPUs from Bitfusion appliances (servers) for acceleration on the right
At VMworld look to session VI1987 to see how Duke University uses Bitfusion to share GPUs among students, researchers, and "scavangers",
and to VMTN2801 on extending Bitfusion to "Any Arch, Any Edge, Any Cloud"
CONTAINERS, KUBERNETES, AND TKG
A web search on "modern app" turns up essays but not short definitions. Let's give it a stab with one long, open-ended sentence.
A modern app, instead of being one monolithic process (or even a few large processes), runs as lots of separate micro-services that are written to tolerate failure, to relaunch quickly, to scale by launching more instances, that can evolve (and develop & test) separately, that...and so on ad infinitum.
With so many pieces, you may want to run them in containers, so every piece gets the independence, the isolation, the environment, and the fast start time, it needs.
With so many containers—and with their coming and going in response to fluctuating demand, balance, and recovery from failure—with their intercommunication—with their different resource needs—you may want Kubernetes to orchestrate everything. ML, containers, and K8s (Kubernetes) have grown in parallel over the last several years and K8s is the preferred container orchestrator.
Containers are also a good way to wrap up services for easy distribution and deployment, whether within a company, or across the world. There are many freely available container images with various apps, libraries, and services. Going to the NGC (NVIDIA GPU Cloud) catalog may be a good place to start.
TKG stands for Tanzu Kubernetes Grid. TKG is VMware's upstream compliant distribution of K8s that is optimized for and integrated into vSphere 7. The TKG documentation states, "Tanzu Kubernetes Grid allows you to run Kubernetes with consistency and make it available to your developers as a utility, just like the electricity grid." It supports your modern apps with a multi-cluster paradigm, and with a uniform face whether you are running on-prem, in the cloud, or multi-cloud.
(See https://docs.vmware.com/en/VMware-Tanzu-Kubernetes-Grid/1.3/vmware-tanzu-kubernetes-grid-13/GUID-index.html)
Moving on to the more particular case, ML apps on TKG, applications needing GPU services, we recommend both:
1. Bitfusion for remote GPU access from containers (Bitfusion on Kubernetes blog part 1 and part 2). Since Bitfusion runs as application-level software, containers do not have to worry about GPU drivers nor about scheduling containers on hosts with GPUs. All they need is network access.
2. The VMware-NVIDIA cooperative effort, NVIDIA AI for Enterprise (NVAIE)—for container access to host GPUs or GPU partitions. See more below.
At VMworld look to session VI1624 using Bitfusion on Kubernetes
and to session VI2517 for Kubetnetes with Intel/Habana-Gaudi.
Still others are:
sessionMCL3037S Making AI Possible for Every Business
session APP2170 Tanzu and NBIDIA AI Deliver AI-Ready Enterprise Platform
session VI2458 a customer talk on AI Infrastructure with NVAIE with Tanzu
MCL2373 AI-Ready Enterprise Platform on vSphere with Tanzu
AI/ML POTPOURRI
GPUs in a virtualized environment are not all that is needed. AI/ML developers and users require other hardware and software.
VMware has done some analysis to help administrators new to AI/ML answer questions on sizing the equipment needed for their users. This certainly covers CPU, memory, storage, and networking resources. VMware takes a bottom-up approach to server sizing based on various representative ML applications in a paper here: https://core.vmware.com/resource/sizing-guidance-aiml-vmware. And NVIDIA takes a complementary top-down approach to rack sizing here: https://docs.nvidia.com/ai-enterprise/sizing-guide/sg-overview.html.
At VMworld look to session VI1501 to see NVIDIA discuss architecting the enterprise datacenter for AI.
Now let us look at software. VMware provides the virtual machines and container orchestration and management, as already discussed. But the software applications and stacks that directly perform the machine learning will come from third parties (such as an NVIDIA CUDA Deep Neural Network library) or from open source projects (such as TensorFlow framework). VMware does its own research and works with partners to ensure we are providing an environment where this software can run.
Nevertheless, let us take a look at some of the software on this stack to give you a feel for what is being used.
Applications: image classification, risk analysis, medical diagnosis and guidance, natural language processing (e.g. customer phone/email support), financial analysis, and on and on.
Datasets: images, x-rays, payment records, etc. in support of the various applications
Frameworks: libraries to make it easy to assemble applications. Includes functions to prepare & curate data, to employ models for training and inference, to evaluate model accuracy, etc. Examples are TensorFlow and PyTorch.
Models: various networks and statistical structures, holding weights and functions that can be adjusted gradually, until they perform intelligent tasks on incoming data. Examples are XGBoost, resnet 152, etc.
Meta software: By "meta" I simply mean the category of everything else, for software that isn't ML per se, but that runs it, improves it, deploys it, etc. This would include software that:
- Runs a server delivering ML to client requests
- Optimizes a model after it has been trained so it runs faster and uses less memory during inference
- Libraries of optimized GPU algorithms (you can argue this is more direct software than meta, but I list it here anyway)
- Drivers for GPUs and networking that accelerate the work
NVIDIA has done a great amount of work to create, to gather, and to package this kind of software, which we will read about in the next section, NVAIE.
NVAIE
NVIDIA and VMware have partnered to deliver an end-to-end enterprise platform optimized for AI/ML workloads called NVAIE. It stands for NVIDIA AI for Enterprise. This suite of components include:
- Application frameworks, libraries for multiple industries and uses.
- Software for services, deployment, and optimization
- Pre-packaged container images
- Drivers, and operators (GPU and NIC access for containers made easy)
Best of all, these are not stand-alone pieces. The main purpose of NVAIE is about certifying whole systems supporting the software suite listed above and seen in the diagram below.
NVIDIA components are certified and supported on VMware machines. VMware components are certified and supported for the NVIDIA software and GPUs. Everything runs together on VMware vSphere with NVIDIA-Certified Systems. You can read more about this here.

Block diagram of NVAIE components
The application frameworks and tools at the top end of this NVAIE diagram appeal to data scientists, making their job easier with NVIDIA’s support. The other layers of the architecture beneath that top layer appeal to the VMware vSphere Operations person. VMware Administrators use vSphere with Tanzu and the NVIDIA GPU and Network Operators to allow a machine learning user to provision their ML infrastructure quickly on-demand in a TKG cluster, while maintaining control over systems resources. This allows the data scientist to work faster and produce more models over time.
CONCLUSION
This blog began with some claims that made for a fast dive into the body of the text. So let us end with a claim as well:
VMware is working very hard in ways we haven't discussed to accommodate the explosive growth of AI/ML.
At VMworld, glimpse the future with session VI1297
But our purpose here was to survey how much is already here as vSphere features and how much we offer with our partners. You should have no trouble taking your first, "scary" steps into AI/ML knowing VMware has your back. You can run the application you want, in the virtualized environment you want, with the acceleration you require. And we have the team members who can help you go further.
At VMworld look to session VI1322 for a multifaceted talk and tutorial about AI/ML technology and infrastructure for it on vSphere.
Look to session UX2521 for an open discussion of AI/ML infrastructure — bring your questions!
Look to session VI2729 to meet the OCTO experts on GPU virtualization.
In fact, check out the Vision and Innovation track and its set of machine learning topics.