
Revisiting vSAN's Free Capacity Recommendations
Among the types of resources that administrators manage, storage may be the most challenging. The demand often increases beyond forecasted levels and addressing the matter with older architectures typically meant adding large capital costs and complexity. Space efficiency and storage reclamation techniques can potentially delay when capacity thresholds are met, but eventually, storage capacity concerns emerge.
vSAN takes a different approach to three-tier architectures in presenting and managing shared storage to hosts. It aggregates the capacity of discrete devices in the vSAN hosts in a cluster to provide storage capacity from a single datastore to the entire cluster. vSAN is responsible for ensuring proper levels of resilience of data across hosts and automatically heals itself in the event of communication or hardware error conditions. While it simplifies the design and management of storage, vSAN's architecture has special considerations for maintaining free space, which occasionally is the cause for confusion. This post attempts to clarify the reasons for vSAN's free space recommendations.
UPDATE: For vSAN 7 U1 and newer, improvements were made that reduces the amount of free space necessary for vSAN. See the post: Effective Capacity Management with vSAN 7 Update 1 for more information.
Free capacity with vSAN
Free space in vSAN serves two very important functions.
- It is used for transient activities. These transient activities use free space temporarily to move or create new copies of data as a result of storage policy changes, host evacuations, rebalancing, or repairs. When VMware documentation refers to "slack space" it is generally referring to the temporary space used for these tasks.
- It is used in the event of failures. Since each host contributes storage capacity resources, a host outage means that the data will eventually need to be placed somewhere else in the cluster. Cluster designs of any type should have enough resources to absorb at least one host failure. With traditional three-tier architectures, this applied to just compute and memory, but with vSAN, it also applies to storage capacity.
VMware provides a number of resources that all point to the same recommendation for capacity sizing guidelines, including the vSAN Design and Sizing Guide, VMware Docs, vSAN Operations Guide, the vSAN sizing tool, and numerous blog posts. These guidelines recommend that for slack space activities such as policy changes, rebalancing, repairs, etc. that approximately 25-30% of vSAN storage capacity for a cluster remains free. Let's explore why this is the case.
Capacity management with HCI - A different mindset
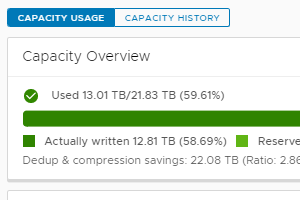
When it comes to capacity management in vSAN, "free space" is often thought of as a single value across the cluster: As a percentage or in gigabytes/terabytes. Since vSAN provides a single datastore per cluster, vSAN renders this capacity utilization nicely in the UI, giving a clear breakdown of free capacity, as shown in Figure 1.

Figure 1. Capacity consumption is rendered as a single value in the UI, but is the sum across devices
vSAN interprets free space at a much more discrete level: Hosts, explicit fault domains, disk groups, and even individual disks. It needs to do this because *where* the available free space resides matters. vSAN places redundant data using an "anti-affinity" approach. As shown in Figure 2, under initial placement decisions, failure conditions, enter-maintenance-mode tasks, storage policy changes, or data rebalancing, vSAN looks for a location to place the data that does not overlap with the other copy of data that provides resilience. Since storage capacity is comprised of these individual disks, some devices may not have the capacity to hold an object component in its entirety, which also influences vSAN's decision on where to place the data.
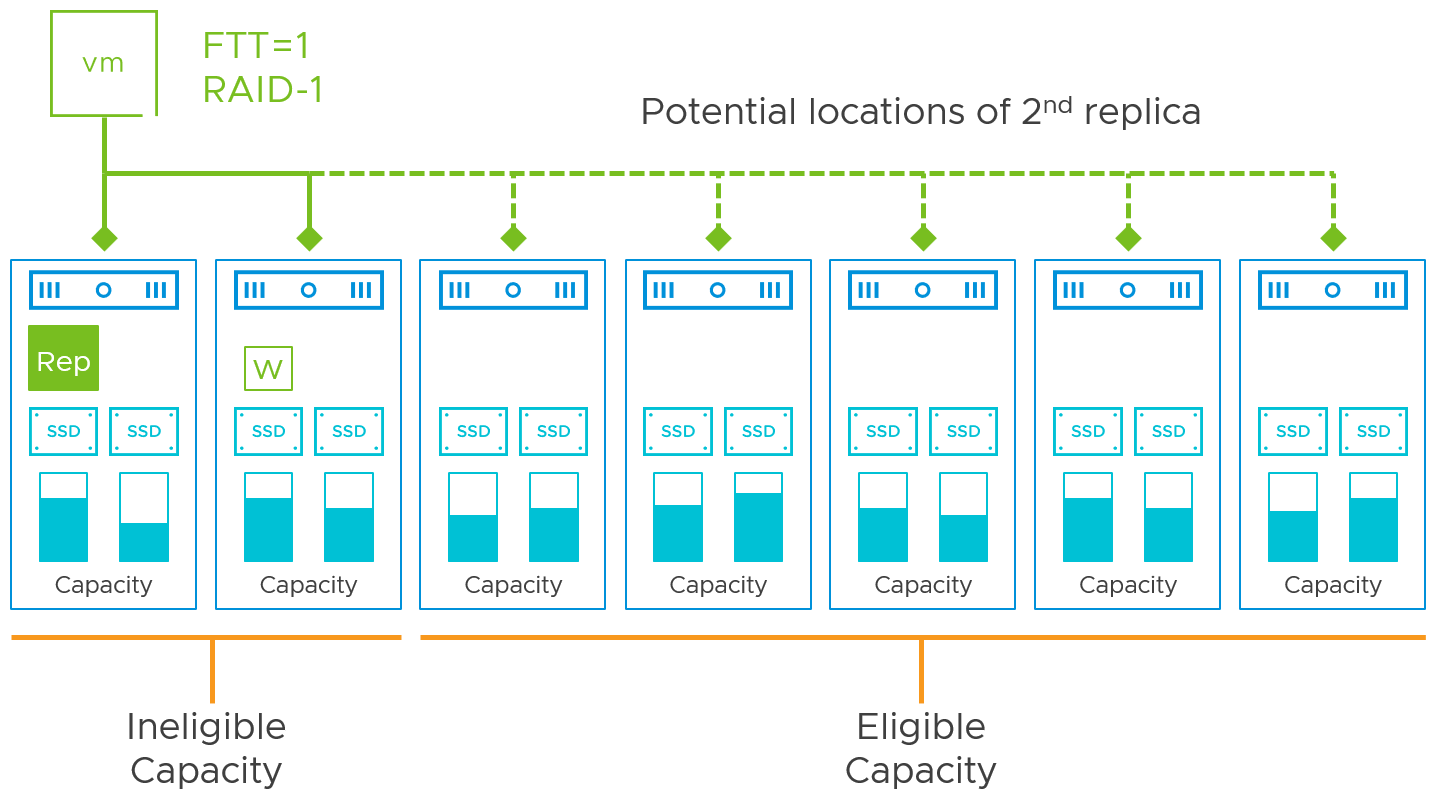
Figure 2. A simple example of how some free space is not available for some data
As you can see in the simple example above, while each host has storage devices with a percentage of capacity available, only certain hosts are eligible to house that data to comply with resilience settings.
Free capacity guidelines for large clusters versus small clusters
A standard vSAN cluster supports between 3 and 64 hosts. The guideline of approximately 25-30% of total capacity remain free applies to clusters of all sizes. This is an estimation of space necessary to perform transient activities, and in typical scenarios is also enough room for a single host rebuild to provide basic N+1 functionality.
With extremely small clusters, or clusters using explicit fault domains, each host (or fault domain) contributes to a larger proportion of capacity. In these cases, it may be prudent to run with slightly more free capacity to ensure there is enough space for transient activities and a host failure. Meeting needs for N+2 or greater may also affect the amount of free capacity necessary for host failure scenarios. For more details on cluster sizing decisions, see this section of the vSAN Cluster Design - Large Clusters versus Small Clusters document on StorageHub.
Comparing the guidance for vSAN to traditional storage
When describing the need for free space, new vSAN users more familiar with a traditional storage array will counter with a response that goes something like: "Why do I need to maintain this recommended level of free space when my array doesn't have this same requirement?" Remember that a distributed storage architecture is different. vSAN can absorb failures of one or more physical enclosures (hosts) and still provide availability of data. Losing an array enclosure in a three-tier architecture is a much more dramatic event. Unless the array is synchronously mirrored with another enclosure, it will mean the total unavailability of that data.
Since HCI uses the compute hosts to provide storage, operational discipline should ensure that a cluster has enough compute, memory, and storage capacity resources to absorb the loss of at least one host. Sometimes neglected in production three-tier environments, an N+1 or greater approach has always been a recommended practice for any cluster design and operation.
Interestingly enough, most storage arrays struggle when storage capacity conditions hit their own internal thresholds. The administrator may not have visibility to the cause of it. Garbage collection routines and data post-processing activities such as deduplication may be affected, resulting in potential degradation of performance or efficiency.
Actions for capacity management for the vSAN administrator
The good news is that vSAN manages data placement for you. It knows that data assigned a specific resilience setting through a storage policy should NOT overlap with the other copy of data in any way. vSAN is constantly monitoring the storage policy's "desired state" configuration of the data and will always adjust to ensure adherence.
One simple, but important task for the administrator remains: Ensure there is enough free space per VMware guidance. For all versions of vSAN up to and including vSAN 6.7 U3, 25-30% is the recommended estimate, and for simplicity is referring to the free space across the cluster. Note that alerting and automated functionality of vSAN is largely based on the conditions of the disks or disk groups, not the cluster.
Monitoring storage capacity consumption is easier than ever. vSAN provides the historical capacity utilization of a cluster in vCenter for easy trending and analysis. More information can be found in the vSAN Operations Guide under Observing Storage Capacity Consumption Over Time.
Can a vSAN cluster operate with less than the recommended free space? Yes, there is nothing preventing that from occurring. Does VMware endorse a practice of running with less than 25-30% free capacity on a vSAN cluster? No. The guidance provided reflects the existing behaviors and needs of vSAN to accomplish these transient data management activities and accommodate for absorbing a host failure.
Accommodating vSAN clusters nearing their capacity limits
Proper operational practices should be in place to prevent any critical capacity condition scenarios. Running near or at capacity limits is not a practice that promotes the availability of data and services, and is not advised under any architecture. Fortunately, vSAN's architecture works well for quickly adding additional capacity in smaller increments than storage arrays. There are two options available.
- Add capacity to existing hosts in a vSAN cluster (scale-up). Either add more capacity devices to existing disk groups across the hosts, or add new disk groups across the hosts. Ideally, capacity should be added across each host in the cluster to maintain uniformity.
- Add hosts to a vSAN cluster (scale-out). Once hosts are added, vSAN will take care of the rest, redistributing the data across the hosts in the cluster.
vSAN 6.7 U3 added several new features to handle capacity strained conditions, such as support for manually downloading and deleting VMDKs from a datastore, as well as powering off VMs. These were tasks that previously required the uses of vmkfstools, but now can be performed in the UI. vSAN 6.7 U3 also added new logic to manage large groups of policy changes under capacity strained conditions. This simplifies management in non-ideal conditions, but the ongoing objective should be to adhere to the recommendations of maintaining a sufficient amount of free capacity.
Summary
vSAN provides storage that is easier to design, operate, and optimize. This distributed approach to storage means that guidelines for the management of free space are different than traditional three-tier architectures. Remember that a key charter of IT is ensuring the availability of data and services. It makes sense that your design and operational practices support that goal. Following VMware's free capacity recommendations helps ensure the outcome desired.