
vSAN Enhanced Data Durability During Unplanned Events, vSAN 7 Update 2
Availability of data is one of the primary responsibilities of an enterprise class storage system, and a focal point for VMware’s efforts toward continual improvement. Therefore, with vSAN 7 Update 2 and VMC, we introduce the Enhanced data durability feature for unplanned failures in the cluster. vSAN 7 Update 2 goes the extra mile by creating a durability component for each data component that has become absent due to an unplanned failure in the cluster. This feature is the logical advancement of enhanced data durability for maintenance mode delivered with vSAN 7 U1. The new enhancement ensures that the latest written data is saved redundantly and, as an additional benefit, it reduces the time it takes for data to be resynchronized to a stale component on recovered nodes.
VMware vSAN advanced setting specifies the amount of time vSAN waits before rebuilding a disk object after a host is either in a failed state or in Maintenance Mode. By default, it is set to wait an hour to verify if a host failure is permanent or transient. During this time, another failure might occur and the VM object component might become temporarily absent due to a disk, a disk group, or a host down.
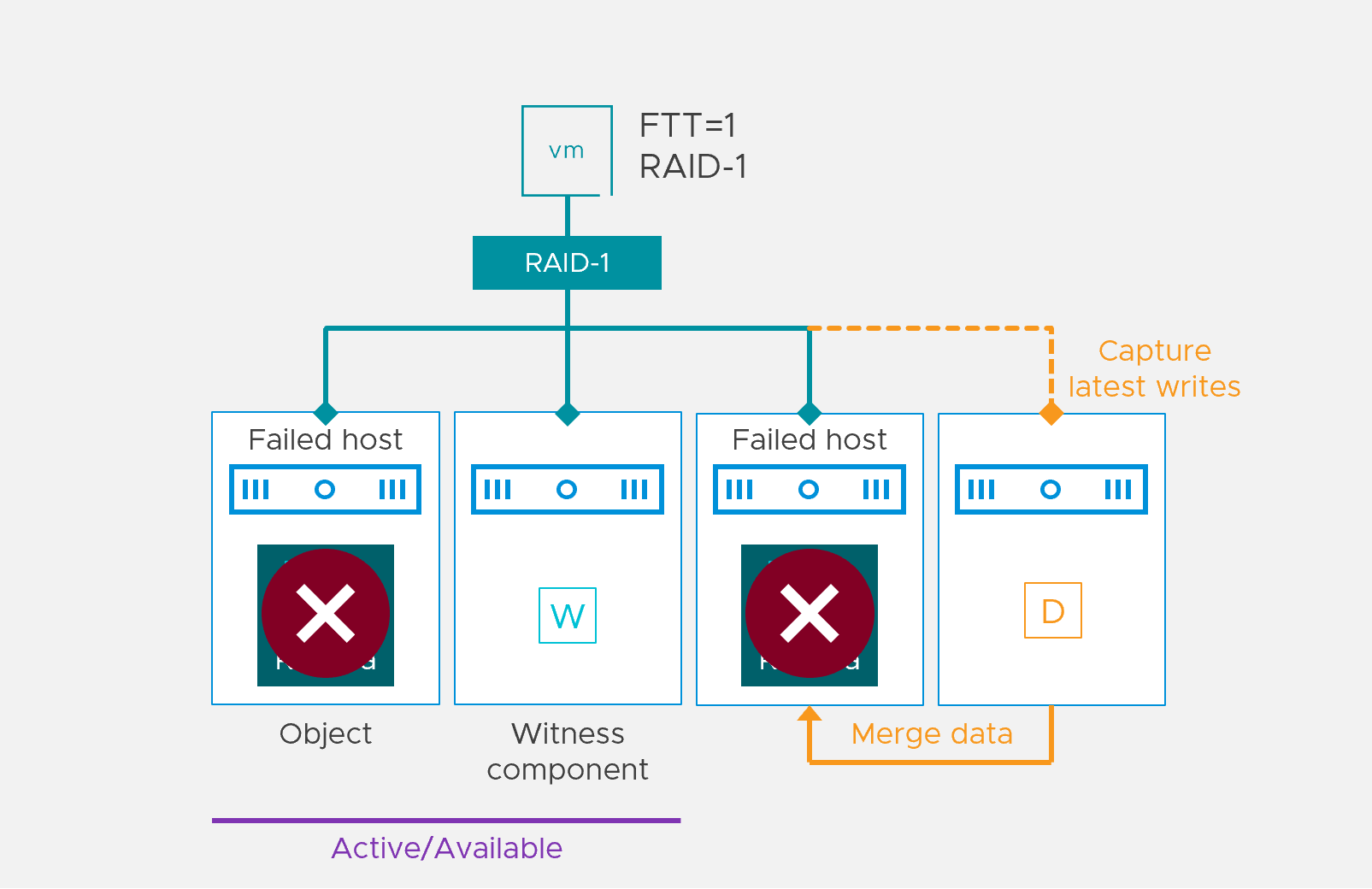
With vSAN 7 Update 2, every time an object component becomes absent due to an unexpected issue, an object-related durability component will be created to store the incremental writes. The component will remain active while vSAN waits to verify if a rebuilding process should be triggered, and in case of a permanent issue, it will stay active until the rebuild is done. More frequent checks for silent disk errors will also be introduced to inform vSAN of potential risk as fast as possible.
vSAN executes the entire process proactively and automatically, so no user intervention is needed. The steps are straightforward and easy to keep track of from the UI:
- A disk, a disk group, a host unplanned failure, or maintenance mode with status “No action” occurs.
- A component becomes absent and its status is also changed to “Absent” in the data disk placement section.
- vSAN becomes aware of the potential issue and creates a durability component on an additional host. At this moment the durability component creation is prioritized over other processes like resynchronizations or policy changes to ensure an immediate capturing of new writes.
- The durability component is inactive for a very short moment while it is resyncing from the surviving components copying only the data that occurred between the time when the failure occurred till the durability component creation ended.
- The durability component becomes active.
- New writes go to the durability component and to the available redundant components.
- If the durability component fails, the sibling mirror will take new writes and will create a new durability component. Thus, this process becomes a cycle. There’s no limitation on the number of durability component failures as long as there’s an active component to be resynced and reactivated from.
- The durability component will only be removed if 1) the parent RAID durability component was replaced and that resync finished or 2) the corresponding base component is active and not on an actively decommissioning host.
For more details, please look at the quick demo overview of the process:
This feature will also cover cases of transient failure of a node containing objects with FTT=2 or higher. It is important to note here that the durability component might not be created if there is not enough space is available, and the feature will only take care of components that went absent on a per-site level in a stretched cluster configuration. An unplanned durability component will not be created if there’s a planned one that already exists.
Summary
The Enhanced vSAN data durability helps achieve two very important goals. Firstly, it maintains higher data durability by immediately storing the incremental data writes on an additional location in case of a one host failure to ensure the latest data will persevere in case of an additional node failure. Secondly, as a result, the time needed for the original component to regain full levels of resilience is shorter because it is resynched using the newly created durability component.