
Leveraging HPC Slurm Cluster Resources in Machine Learning Operations (MLOps) Workflow with VMware Tanzu and DKube
AUDIENCE
This document is intended for virtualization architects, IT infrastructure administrators,
HPC systems administrators, and Data Scientists who intend to deploy DKube and run Kubeflow Machine Learning jobs on HPC Clusters.
EXECUTIVE SUMMARY
VMware provides a flexible and robust virtualization infrastructure that enables organizations to build, run, and manage AI/ML applications at scale, both on-premises and across multi-cloud.
VMware's platform offers a range of benefits, such as high performance comparable to bare-metal[4,5,6,7,8], scalability, security, and more which help improving resource utilization and reducing infrastructure complexity. Additionally, VMware's partnership with experienced MLOps Independent Software Vendors (ISVs) such as One Convergence (DKube.IO) further enhances the value proposition for customers. DKube is a comprehensive end-to-end AI/ML platform that enables data scientists and engineers to streamline the entire machine learning lifecycle, from data preparation to model deployment. By combining the power of VMware's platform with DKube's advanced capabilities, customers can accelerate their AI/ML initiatives, reduce costs, and improve their time-to-market.
This solution describes a general reference architecture for running DKube MLOps workflow on virtualized HPC Slurm cluster with Tanzu Kubernetes Grid Service. This reference architecture will cover topics such as Kubernetes requirements and cluster layout for DKube and Slurm as well as examples on running DKube jobs on HPC Clusters.
TECHNOLOGY OVERVIEW
- VMware vSphere
- VMware vSAN
- VMware Tanzu Kubernetes Grid Service (TKGs)
- HPC Slurm Cluster
- Dkube
- Singularity Container
VMware vSphere
VMware vSphere is a powerful virtualization platform that enables organizations to consolidate their server workloads and reduce their datacenter costs. With vSphere, organizations can deploy and manage virtual machines (VMs) and containers on a single platform, while providing high availability and disaster recovery features. In addition, vSphere provides centralized management capabilities for all an organization's IT infrastructure, including networking, storage, and security.
VMware vSAN
VMware vSAN is a key component of the vSphere platform, providing a highly available and scalable storage solution for virtualized environments. vSAN aggregates local storage devices into a shared pool of storage that can be provisioned and accessed by all VMs in a vSphere cluster. vSAN eliminates the need for a dedicated storage array, and provides key features such as deduplication, compression, and snapshotting. In addition to providing cost-effective storage for virtualized environments, vSAN also simplifies storage provisioning and management.
VMware Tanzu Kubernetes Grid Service (TKGs)
As a leading provider of cloud infrastructure, VMware enables organizations to run any application on-prem or cloud. With VMware Tanzu, it is easy for customers to run modern applications by offering a complete solution for developing, deploying, and managing them at scale. Tanzu Kubernetes Grid Service is a fully managed, scalable, and secure container orchestration service for running production workloads on vSphere environment.
HPC Slurm Cluster
Slurm is a powerful open-source tool that can help manage, schedule, and monitor computing resources. By using Slurm, you can easily allocate and deallocate resources, track usage, and manage user access. It is fault tolerant and scalable, suitable for Linux Compute clusters of various sizes.
DKube
DKube is a Kubeflow and MLFlow based enterprise grade end-to-end MLOps platform for developing, training, and deploying machine learning models in Kubernetes. It provides an easy-to-use interface that makes it simple to get started with deep learning on Kubernetes. DKube integrates with HPC clusters to provide an end-to-end data science and machine learning platform that enables users to train, test, and deploy models quickly and easily.
Singularity Container
Singularity is a container technology for portable, scalable, and reproducible science at extreme scales. Singularity makes it easy to run complex applications on HPC clusters in a way that is portable and reproducible. This makes it an ideal platform for High Performance Computing (HPC) applications and workflows.
SOLUTION CONFIGURATION
- Hardware resource
- Software resource
- Dkube Tanzu Kubernetes Cluster Setup
- Virtualized Slurm HPC Cluster Setup
Hardware Resources
This section describes the hardware configuration used in this Reference Architecture.
Table 1 Hardware Resources – Tanzu Environment
|
Property |
Specification |
|
Server Model |
5 x Dell PowerEdge R740 |
|
CPU |
2 x Intel(R) Xeon(R) Gold 5120 CPU @ 2.20GHz 14 Cores |
|
RAM |
192GB |
|
Network Resources |
2 x Intel(R) Ethernet Controller 10G X550 |
|
Storage Resources |
1 x Dell HBA330 disk controller 1 x Dell G14 400GB SSD as vSAN Cache Device 2 x Dell S4610 960GB SSDs as vSAN Capacity Devices |
Table 2 Hardware Resources – HPC Cluster Virtual Environment
|
Property |
Specification |
|
Server Model |
4 x Dell PowerEdge R740xd vSAN Ready Node |
|
CPU |
2 x Intel(R) Xeon(R) Gold 6248R CPU @ 3.00GHz 24 Cores |
|
RAM |
384 GB |
|
Network Resources |
2 x Mellanox ConnectX-4 LX 25GbE SFP as Management Network |
|
Storage Resources |
1 x Dell HBA330 disk controller 2 x Toshiba KPM5XMUG400G 400GB SSD as vSAN Cache Device 2 x WDC WUSTR1519ASS200 1.92TB SSDs as vSAN Capacity Devices |
Software Resources
This section provides a list of software and their respective version used in this Reference Architecture.
Table 3 Software Resources – Tanzu Environment
|
Software |
Version |
|
VMware vSphere |
7.0.3g |
|
VMware HAProxy Load Balancer |
0.2.0 |
|
Tanzu Supervisor Cluster |
v1.22.6+vmware.1-vsc0.0.17-20026652 |
|
Tanzu Kubernetes Release (TKr) |
Ubuntu 1.20.8+vmware.1-tkg.2 |
|
DKube |
3.8.1 |
|
Helm |
3.9.2 |
Table 4 Software Resources – HPC Cluster Environment
|
Software |
Version |
|
VMware vSphere |
7.0.2g |
|
Guest OS |
Rocky Linux 8 |
|
Slurm* |
20.11.9 |
|
MariaDB |
10.3 |
|
Munge |
0.5.13 |
|
Jason Web Token (JWT) Library |
1.12.0 |
DKube Tanzu Kubernetes Cluster Setup
This section introduces the Dkube setup.
Table 5 DKube Setup
|
DKube Setup |
|
|
Namespace |
dkube |
|
Cluster Name |
dkube-cluster |
|
Storage |
vSAN (used for VMs) and Dell Isilon (NFS – External Storage, used for DKube Slurm Integration) |
|
VM Classes* |
Control Plane
Worker Nodes
|
*Custom classes were created according to DKube requirements.
Virtualized Slurm HPC Cluster Setup
This section introduces the Slurm HPC Cluster setup.
Table 6 Slurm Setup
|
Slurm Setup |
|
|
Cluster Name |
dkube-hpc |
|
Compute |
Head Node
Compute
|
|
Storage |
NFS - Dell Isilon |
SOLUTION ARCHITECTURE AND NETWORK DESIGN
The Tanzu Kubernetes Grid Service (TKGs) cluster was provisioned on top of a vSphere/vSAN Cluster with five physical ESXi hosts. The DKube namespace (Cluster) consist of three control plane nodes, and four worker nodes, all CPU only nodes. It is possible to add GPU nodes to DKube cluster, however that was not intent for this architecture as we were evaluating the remote job submission capabilities of DKube and Slurm. DKube was installed via Helm, and multiple worker pods were deployed.
A virtualized HPC Slurm Cluster* was created on a different vSphere Cluster with multiple ESXi hosts. Five VMs were deployed, and Rocky Linux 8.6 Operating System was installed on them. One VM was dedicated for Slurm Head Node and four VMs were configured as Compute Nodes. Singularity was installed in all compute nodes as it is required by DKube to properly submit and run jobs on Slurm Cluster.
It is possible to run DKube Kubeflow Machine Learning remote jobs on Bare-Metal HPC Clusters*, however this solution was not evaluated.
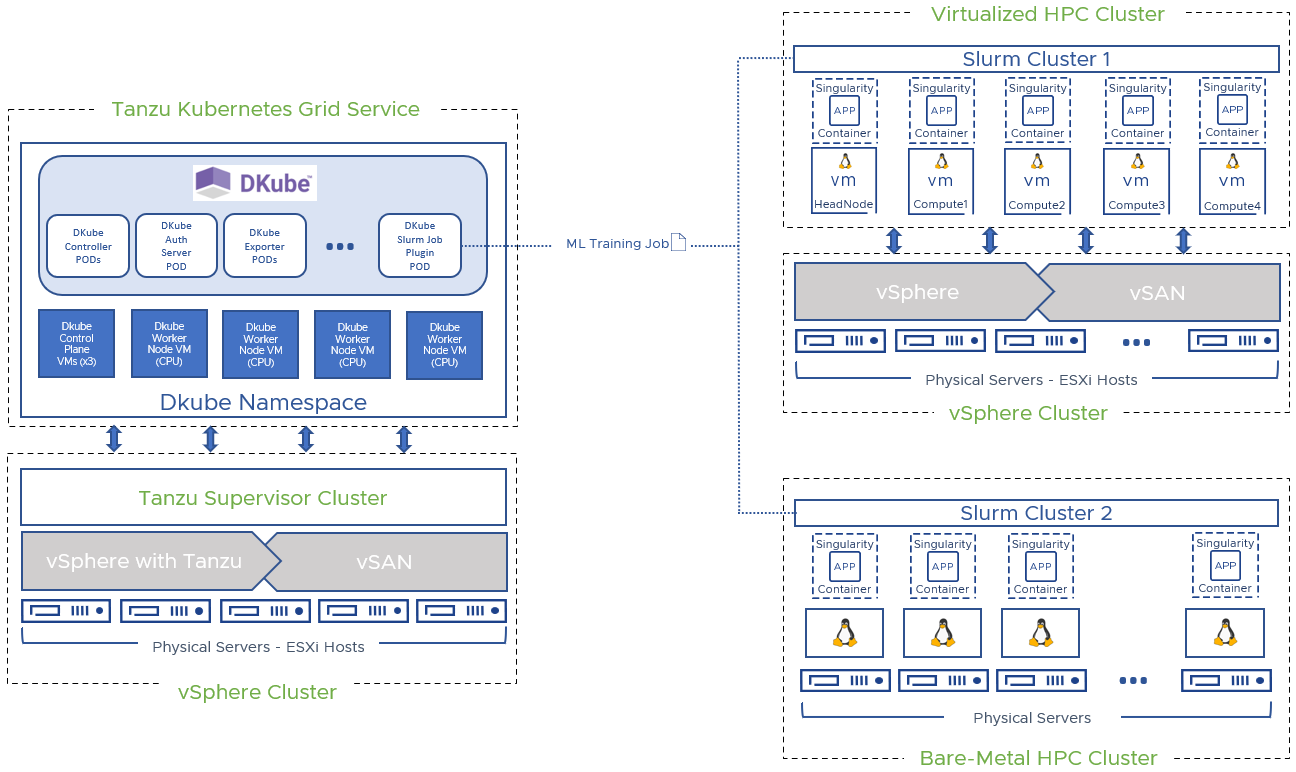
Figure 1 Solutions Architecture - vSphere with Tanzu environment (left), Virtualized HPC Cluster and Bare-Metal environments (right)
*DKube supports Slurm Cluster version 21.08.1 and below and it requires Jason Web Tokens (JWT) for authentication.
The Tanzu environment included one Intel 10GbE NIC used for vSphere management, VM Network, NFS Storage access, vMotion and other purposes. The second Intel 10GbE NIC was strictly dedicated to the workload network for Tanzu. VMware HAProxy Load Balancer was deployed to provide routing and load balancing traffic for the TKGs cluster.
In the virtualized HPC Cluster, two Mellanox 25Gbps were used for vSphere management, vMotion, vSAN, and NFS access. The Mellanox 100Gbps InfiniBand (IB) interconnect was dedicated for the HPC workload network specifically to meet the needs of HPC workloads.
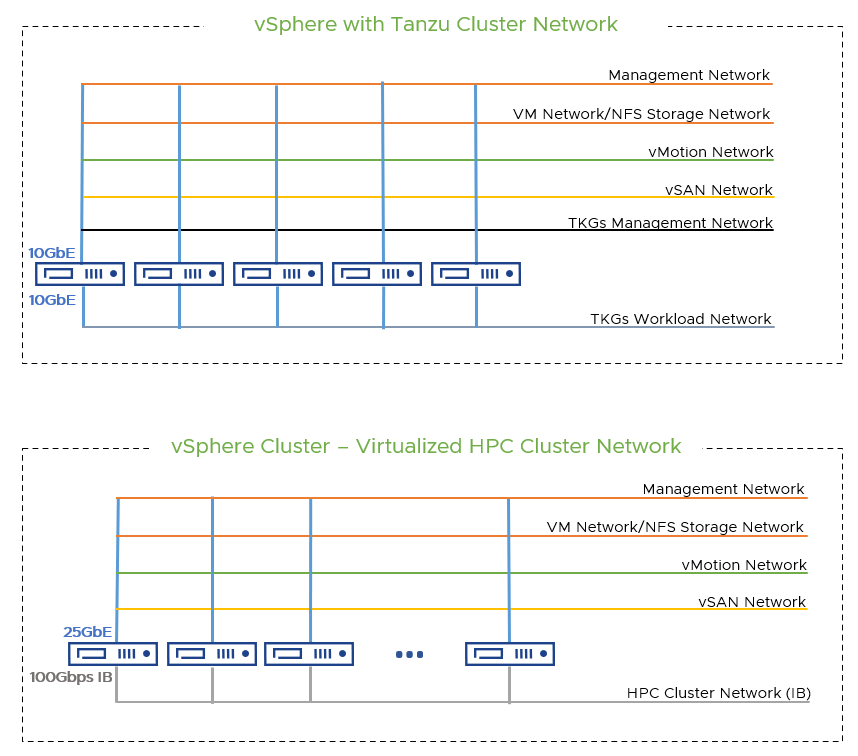
Figure 2 Demonstrate Network Design for both Tanzu Cluster and HPC Cluster
DEPLOYING DKUBE CLUSTER IN TANZU
Once Tanzu Kubernetes Grid Service has been successfully deployed and configured in vSphere, it will be required to create and configure a namespace that will be used to host DKube’s Kubernetes Cluster.
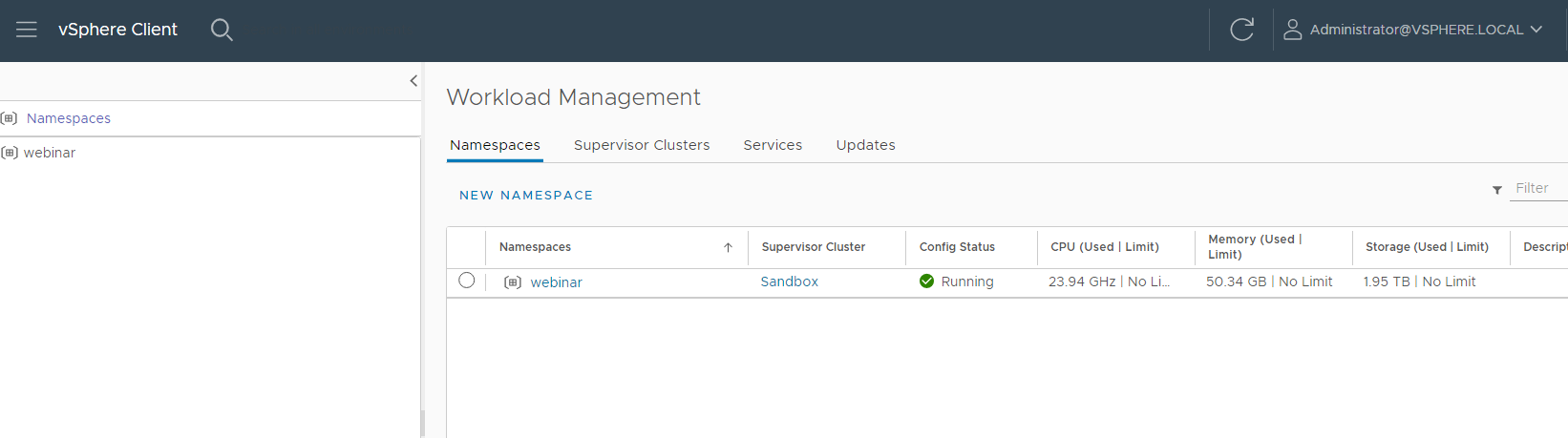
Figure 3 vSphere Workload Management

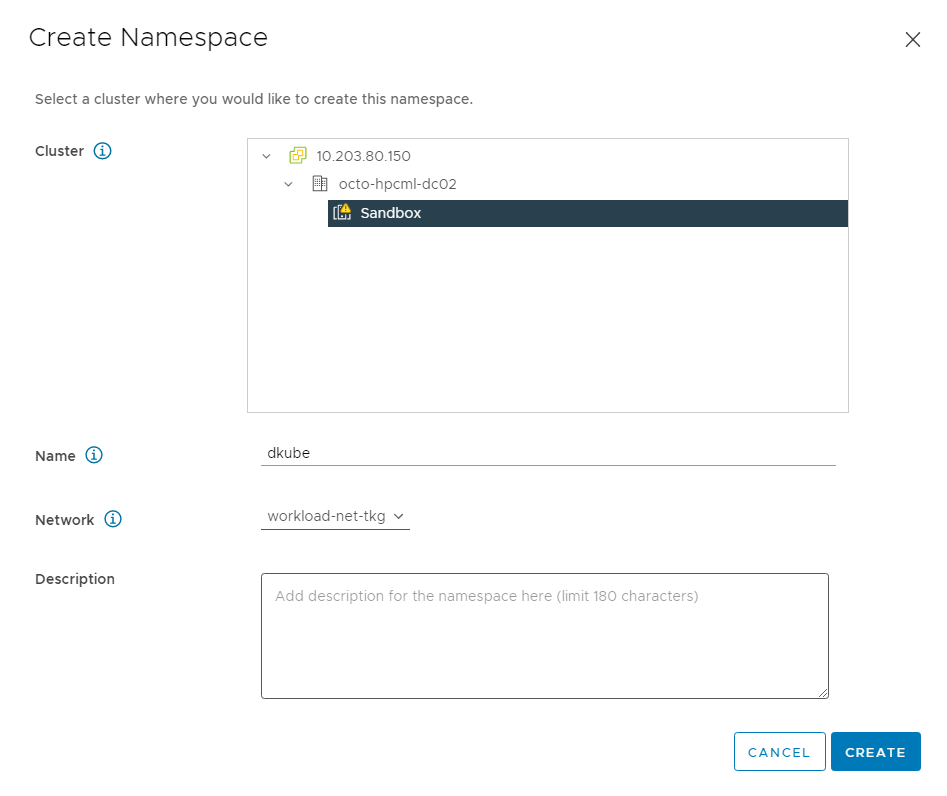
Figure 4 Creating a New Namespace
The workload cluster can be deployed using a configuration file (yaml) via “kubectl” command after namespace has been created in vSphere. See the example below:
#Login into TKGs, change context to dkube namespace, then apply "dkube-cluster.yaml" configuration file
$kubectl vsphere login --vsphere-username administrator@vsphere.local --server=Tanzu_Supervisor_IP --insecure-skip-tls-verify
$kubectl config use-context dkube
$kubectl apply -f ../k8s-cluster-deploy/dkube-cluster.yaml
#Set ClusterRoleBinding to Run a Privileged Set of Workloads
$kubectl create clusterrolebinding default-tkg-admin-privileged-binding --clusterrole=psp:vmware-system-privileged --group=system:authenticated
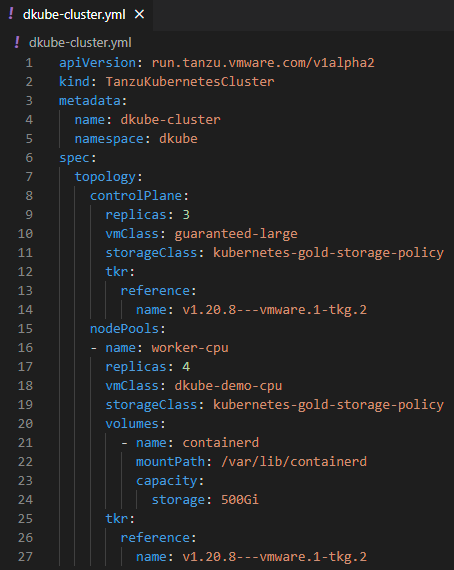
Figure 5 Tanzu Workload - YAML Configuration File Example
In the example above, three Control Planes will be deployed using the VM Class guarantee-large and four CPU only workers will be deployed using a dkube-demo-cpu VM Class. For more information on VM Class, please refer to VMware’s documentation.
INTEGRATING DKUBE AND SLURM
This section describes how to integrate DKube with an existing Slurm Cluster after successfully deploying DKube via Helm on vSphere with Tanzu.
First, let us deploy DKube on TKGs.
#Download DKube pre-req binaries and files. Contact DKube support for docker credentials.
$sudo docker login -u $docker_user -p $docker_pass
$sudo docker run --rm -it -v $HOME/.dkube:/root/.dkube ocdr/dkubeadm:3.8.1 init
#Install Helm, add DKube repo, generate "values.yaml" file
$sudo apt-get install helm
$sudo helm repo add dkube-helm https://oneconvergence.github.io/dkube-helm
$sudo helm repo update
$sudo helm show values dkube-helm/dkube-deployer | sudo bash -c 'cat - > values.yaml'
#Edit "values.yaml" file. This file contains the parameters necessary to deploy DKube, such as user/password, Dkube version, provider, NFS, etc.
$sudo vi ~/.dkube/values.yaml
#Install DKube
$sudo helm install -f values.yaml dkube-3.8.1 dkube-helm/dkube-deployer
#To configure DKUbe to use HAProxy LB and retrieve assigned External IP
$kubectl patch svc/istio-ingressgateway -n istio-system -p '{"spec":{"type":"LoadBalancer"}}'
$kubectl get svc/istio-ingressgateway -n istio-system
For more information, please refer to the DKube installation Guide for Tanzu[1].
DEMOS
The on-demand webinar session link provided below grants access to demos. Kindly register for the webinar to watch the videos.
Demos covered during the Webinar:
- Connecting Slurm HPC Cluster to DKube
- DKube MNIST example
- DKube Pipeline example
https://www.dkube.io/dkube-vmware-webinar-25-05-2023#Register-section
CONCLUSION
In conclusion, integrating vSphere with Tanzu, DKube and HPC Slurm Clusters provides customers with a comprehensive platform for managing and deploying containerized workloads, running large-scale compute-intensive workloads, and building and deploying machine learning models at scale. By leveraging the strengths of each of these platforms, customers can achieve greater efficiency, scalability, and agility, helping them to accelerate their time to market and achieve their business goals.
REFERENCES
- Tanzu Quick Start Guide: https://core.vmware.com/resource/vsphere-tanzu-quick-start-guide-v1a
- DKube Getting Started: https://www.dkube.io/guide/guide3_x/Getting_Started.html
- Slurm Quick Start User Guide: https://slurm.schedmd.com/quickstart.html
- InfiniBand/RoCE Setup and Performance on vSphere 7.x: InfiniBand/RoCE Setup and Performance on vSphere 7.x
- RoCE SR-IOV Setup and Performance Study on vSphere 7.x: https://www.vmware.com/techpapers/2022/vsphere7x-roce-sriov-setup-perf.html
- InfiniBand SR-IOV Setup and Performance Study on vSphere 7.x: https://www.vmware.com/techpapers/2022/vsphere7x-infiniband-sriov-setup-perf.html
- Achieving Near Bare-metal Performance for HPC Workloads on VMware vSphere 7: https://blogs.vmware.com/performance/2022/01/achieving-near-bare-metal-performance-for-hpc-workloads-on-vmware-vsphere-7.html
- Performance Study of HPC Scale-Out Workloads on VMware vSphere 7: https://blogs.vmware.com/performance/2022/04/hpc-scale-out-performance-on-vmware-vsphere7.html
- Virtualized High Performance Computing Toolkit (vHPC Toolkit): https://github.com/vmware/vhpc-toolkit
ABOUT THE AUTHORS
Fabiano Teixeira is a seasoned Solutions Architect with over 20 years of experience in technical support, services, and engineering. He is currently part of the VMware OCTO team, where he specializes in emerging solutions architecture. Fabiano is passionate about exploring new technologies and developing innovative solutions to complex challenges. In his current role, he leverages VMware software solutions to create new AI/ML and HPC solutions, with focus on customer experience. In his free time, he loves spending time with his family, coaching basketball and playing video games.
Yuankun Fu is a Senior Member of Technical Staff in the VMware OCTO team. He holds a Ph.D. degree in Computer Science with a specialization in HPC from Purdue University. Since 2011, he has worked on a wide variety of HPC projects at different levels from the hardware, middleware, to the application. He currently focuses on the HPC/ML application performance on the VMware multi-cloud platform, from creating technical guides and best practices to root-causing performance challenges when running highly technical workloads on customer platforms. In addition, he serves on the Program Committee of several international conferences, such as BigData’23 and eScience’23. Yuankun also loves musicals, art museums, basketball, soccer, and photographing in his spare time.