
Running Multiple Applications on One GPU with vSphere Bitfusion
This post was has two authors, Lan Vu Senior, Member of Technical Staff and James Brogan, Sr. Solutions Architect for vSphere Bitfusion. Also, Josh Simons Senior Director & Chief Technologist, High Performance Computing and Ricky Ho Senior Staff Data Scientist served as the reviewers.
There are many AI/ML applications that while having a practical requirement for hardware acceleration, do not need the full GPU capacity in terms of time or space (GPU compute power or memory) . Inference applications or even training applications with small models serve as examples. It would be nice to make use of this extra capacity, to let other apps run concurrently.
Divide and Conquer—A Strategy for Peacetime, too
The better translation (Latin: divide et impera) might be, divide and rule. Can you rule your GPU costs and power needs? Given vSphere Bitfusion’s ability to partition GPUs into fractions (or into multiple, smaller shared GPUs), this blog investigates if simultaneous runs by different clients give you a better return on investment. We run four different, concurrent applications, and compare their simultaneous performance against isolated runs (non-concurrent runs with the full, dedicated GPU).
We will start with a brief look at Bitfusion and then describe the experiments in detail, following which, we will examine the results.
Share Your Toys—A Strategy for after Kindergarten, too
AI and ML apps, and more particularly Deep Learning apps, practically require hardware acceleration (quite often GPUs). Without acceleration, most of them run extremely slowly. Hardware accelerators, though, come at a high monetary price, and the price is compounded by utilization numbers that are typically low (perhaps below 15%, according to some industry studies).
Here some common reasons for low utilization:
- Many real-world workloads, even inference workloads, do not run 24 hours a day
- Many workloads use small models or have other characteristics that tend to have GPU utilization significantly below 100%
- Hardware devices (such as GPUs) sit on the PCIe bus and are hard to share—they must be assigned to a single client (for example, a DirectPathIO assignment to a VM)
But now, vSphere Bitfusion lets clients share GPUs. A client can dynamically allocate a GPU, or multiple GPUs, or even a portion of a GPU, then use the resource(s) to accelerate an ML app, and finally release the hardware so other clients can use it too.
This is done with a client-server architecture. A set of vSphere Bitfusion servers have access to physical GPUs and provide access across the network to vSphere Bitfusion clients (machines with no GPUs). A client uses vSphere Bitfusion first to allocate GPUs and then as it runs its AI/ML app within the Bitfusion environment, the CUDA API calls are 1) intercepted, 2) sent with referenced data (e.g. training data, weights, etc.) to the Bitfusion server, 3) executed (e.g. matrix operations, etc.) on the remote GPU(s), and 4) completed by sending results from the server to the client. Figure 1 shows a vSphere Bitfusion cluster with four clients
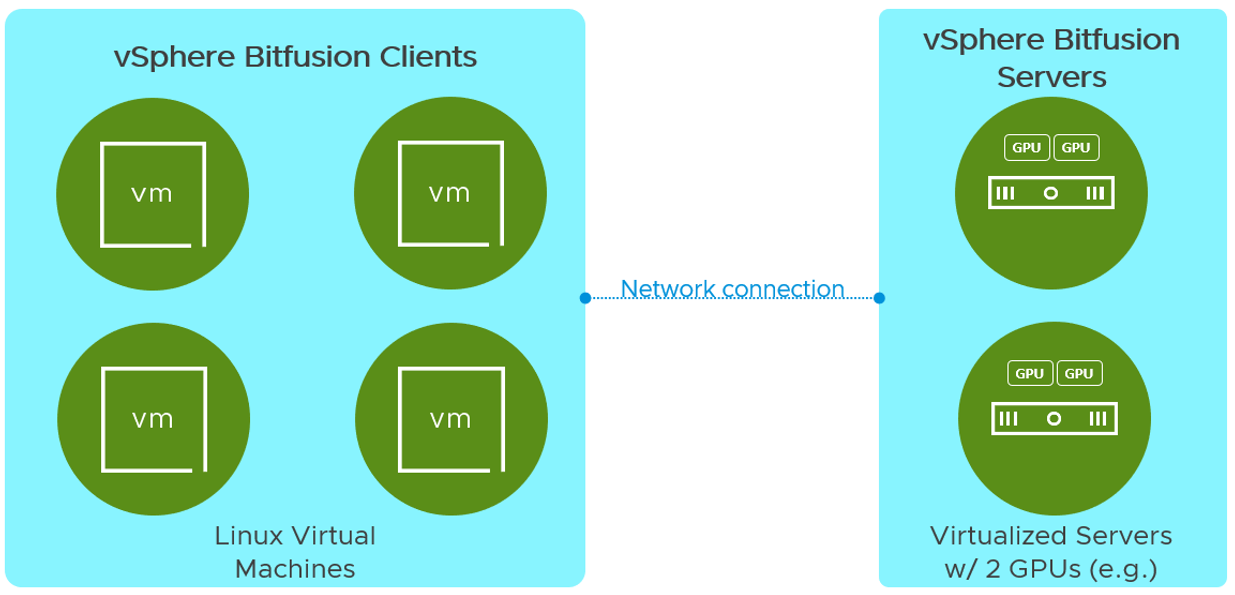
Figure 1
Bitfusion shares GPUs in two ways and both can be used at the same time:
- Remote GPU access
- Partitioning GPUs
Partitioning divides GPU memory into arbitrarily-sized chunks assignable to different clients. This can be done in MBs or as a percentage of total memory. For example, Client A could request 25% of a GPU (memory) and Client B could request 31.4%. This would leave 43.6% of memory available for additional clients.
GPU compute is not partitioned; it is fully available to all clients; the driver and GPU hardware are responsible for scheduling. This helps to achieve maximum utilization of the compute resources.
Are We There Yet?—A Strategy for Dealing with the Inner Child, too
Let us figure out what we want, so we will recognize it if it happens. We want to exploit the parallelism offered by the partitioning. If, for example, we have four applications that can run with 25% of GPU memory, all would fit in the memory of a single GPU. Thus, they could all run at the same time. If we further assume each app required always had GPU utilization of 25%, then potentially, all four would run at full speed, even while running in parallel. But together, we’d see the GPU utilization rise to 100% and the throughput quadruple.
That would be the ideal case, of course, but even if the apps used more than 25% of the compute power (but less than 100%), they should still run more efficiently together, and with greater throughput, that if run sequentially.
In a worst-case scenario, assuming each application needed 100% of the compute power, the opportunities might be different or limited, but still valuable.
- There may yet be parallelization possibilities as not all cores or features may be used when GPU utilization is measured at 100%
- Since applications no longer block each other, the apps may progress together and provide intermediate results or streaming results at the same time
- Since applications no longer block each other, a long-running application can be launched without preventing other short running applications from running
When Software and Hardware Love Each Other Very Much…—A Strategy for Reproducing Results, too
Now we will outline the actual experiments we performed.
MLPerf is an open source inference benchmark. It has the ability to run a matrix of four models (resnet, mobilenet, ssd-small, and ssd-large) in four modes (Server, Offline, Single Stream, and Multi-Stream). We obtained a Docker image of this project (from the vSphere Bitfusion DevOps and testing teams), configured and proven to run all four models in Server Mode (Offline too, but we focused on Server Mode) on a 16 GB GPU.
We used one host with a 16 GB GPU as the Bitfusion GPU server. We used two hosts to run four VMs as Bitfusion clients. Each client ran MLPerf in Server mode of MLperf Inference with a different model: resnet, mobilenet, ssd-small, and ssd-large. This is shown in Figure 2, below. Each client requested a 25% partial GPU from the GPU server. Since the models had drastically different run times, we had to take care to keep each partial GPU busy for the entire test.
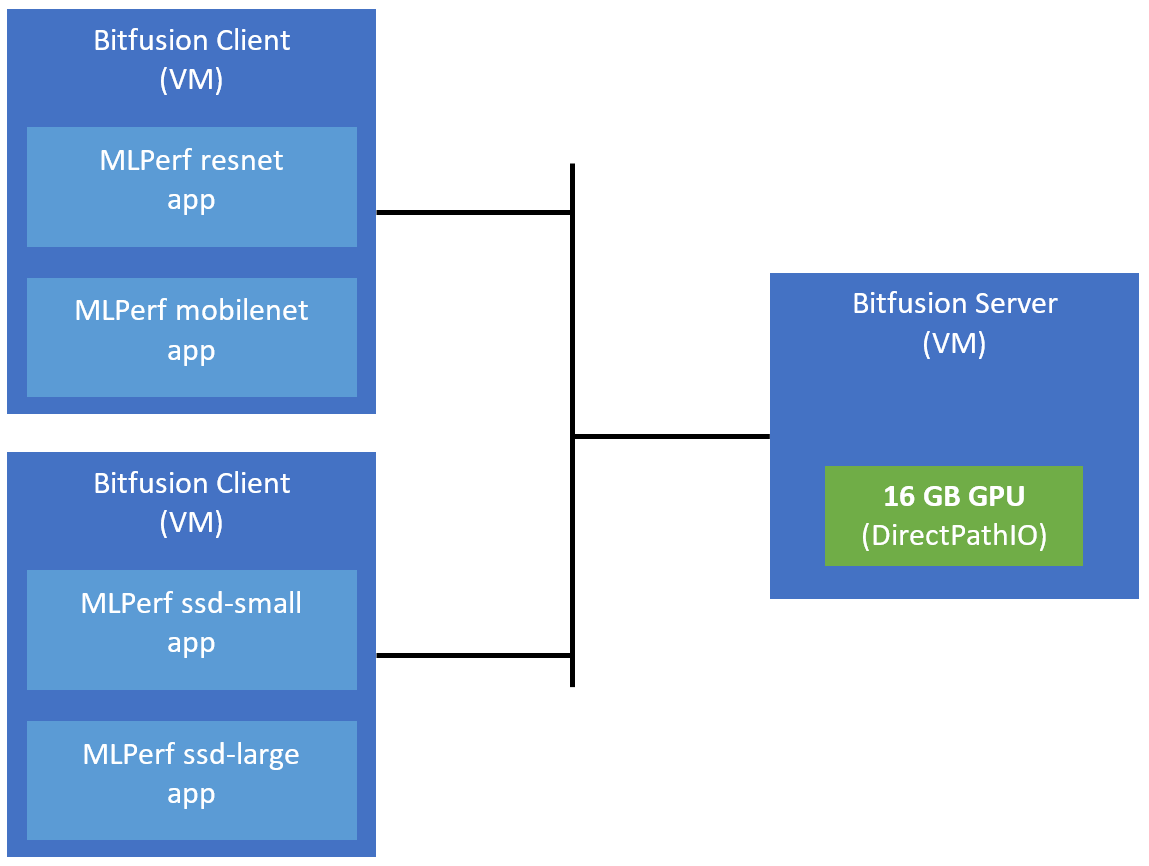
Figure 2
Here is an example batch script to run the resnet loop under Bitfusion:
#!/bin/bash
export RUN_ARGS=’--benchmarks=resnet --scenarios=Server --configs measurements/T4x8/resnet/Server/config.json --test_mode=PerformanceOnly --server_target_qps=4000′
for counter in {1..25}
do
echo “Run $counter”
bitfusion run -n 1 -p .25 -l 172.16.31.201 -- time make run_harness
done
The server mode of MLPerf Inference benchmark continuously generates and executes a large number of inference queries; each query is to do the inference for one sample (i.e. one image) of dataset. We define the load of inference benchmark runs by setting --server_target_qps which is used to specify the Scheduled Samples per Second (SSPS). The benchmark will capture the actually completed samples per second (CSPS) which we refer as the throughput. To demonstrate the different GPU usage patterns of ML/AL inference application, we define two cases:
-
Light weight load with low GPU utilization. This case, SSPS of each model is set low in such a way that GPU utilization of a ML model fell to a range typically between 30% and 50%.
-
Heavy workload with high GPU utilization. This case, SSPS of each model is set high and the GPU utilization is higher than the other case.
In both cases, we chose an inference batch size for optimizing the GPU usage as follows: batch size = 32 for Mobilenet, Resnet and SSD Small models; and batch size = 4 for SSD Large model. The table below shows the desired utilization objectives.
For a demonstration of the differences and benefits of sharing by using Bitfusion partial GPUs, we conducted our experiments by running four ML models in MLperf Inference benchmark both sequentially in a single VM and in parallel in four VMs as illustrated below in Figure 3.
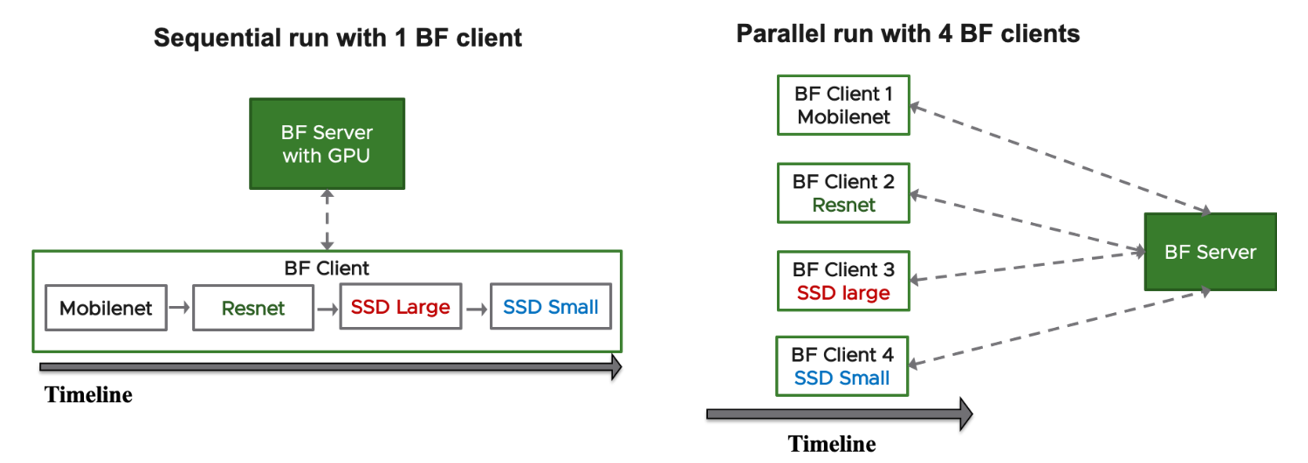
Figure 3
We measured throughput (completed samples per second) as reported in the output of the benchmark runs and used it to compute the total samples given an execution time. GPU utilization and GPU memory usage were also collected.
GPU Sharing with Bitfusion for lightweight loads that have low GPU utilization
GPU Sharing brings the most benefits in the case of low-GPU-utilization workloads, which is the case for many real-world applications. For the lightweight workload simulation, we ran the MLPerf Inference benchmark with --server_target_qps of 1000 (mobilenet), 1000 (resnet), 50 (ssd-large) and 1000 (ssd-small). The throughput (completed sample per seconds) and other results are reported in Table 1 and Table 2. Both sequential runs and parallel runs show similar throughput achieved for each ML model while parallel runs give better GPU utilization and GPU memory usage. This illustrates the benefits of sharing GPUs for lightweight workloads that enable 4 workloads to use same GPU without compromising the expected throughput. Hence, this could save on hardware costs compared to using a dedicated GPU for each workload.
For the sequential runs, we report the total completed samples in 300 seconds of each ML model. Since each ML model is run for 300 seconds sequentially, the total execution time is 1200 seconds. For easy comparison, the execution time of parallel runs are extended to 1200 seconds, which is same length as total of the sequential runs. We compare the normalized total completed samples in 1200 seconds of both test cases in Figure 4, which show a 4 times increase in total completed samples of the lightweight loads.
Table 1: The lightweight load results of sequential runs with single BF client
| Workload | Throughput (Sample Per Seconds) |
Execution Time (seconds) |
Total Samples | GPU Utilization (%) |
GPU Memory Usage (MB) |
|---|---|---|---|---|---|
| mobilenet | 1000 | 300 | 300000 | 31 | 1525 |
| resnet | 1000 | 300 | 300000 | 49 | 1254 |
| ssd-large | 50 | 300 | 15000 | 35 | 1958 |
| ssd-small | 1000 | 300 | 300000 | 39 | 1780 |
Table 2: The lightweight load results of parallel runs with 4 BF clients
| Workload | Throughput (Sample Per Seconds) |
Execution Time (seconds) |
Total Samples | GPU Utilization (%) |
GPU Memory Usage (MB) |
|---|---|---|---|---|---|
| mobilenet | 1000 | 1200 | 1200000 | 100 | 6488 |
| resnet | 1000 | 1200 | 1200000 | 100 | 6488 |
| ssd-large | 50 | 1200 | 60000 | 100 | 6488 |
| ssd-small | 1000 | 1200 | 1200000 | 100 | 6488 |
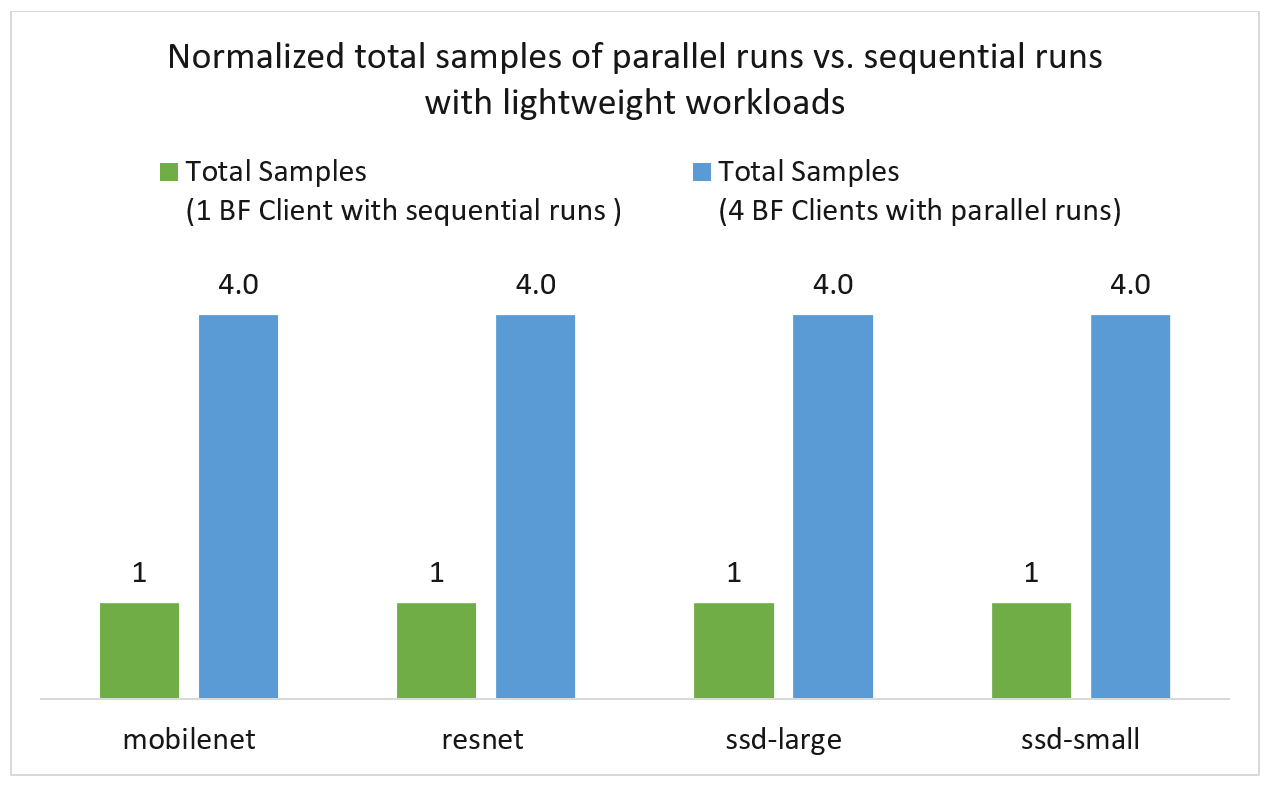
Figure 4: Comparison of total completed samples of lightweight workloads
GPU Sharing with Bitfusion for heavy workloads with high GPU utilization
For heavy workloads, with very high GPU utilization, GPU sharing still brings some benefits. This is because the GPU usage pattern of an application can vary during the day and most applications will not utilize 100 % of the GPU 24/7. In this experiment, we studied the performance impact of sharing GPUs among applications with heavy GPU use (i.e. ~100% GPU utilization). For this purpose, we ran the MLPerf Inference benchmark with very high --server_target_qps settings: 16000 (mobilenet), 6000 (resnet), 150 (ssd-large) and 8000 (ssd-small). The throughput (completed sample per seconds) and other results are reported in Table 3 and Table 4. In the sequential runs, each workload uses nearly the entire GPU throughout the run and it issues a large number of inference requests per second. The obtained throughput of these workloads is sharply higher than the case of lightweight workloads; their GPU utilization numbers range from 95% to 100%. For parallel runs, 4 concurrent workloads share a single GPU so their throughput is not as high as in the case of sequential runs.
For a fair comparison, we keep the total execution time of sequential & parallel runs in our experiments equal, which is to say 400 seconds for parallel run and 100 seconds per workload for sequential runs. We compare the normalized total completed samples of both test cases in Figure 5 which show GPU sharing still helps to increase total completed samples 1% – 25% depending on the ML models. Hence, sharing GPUs can even give marginal throughput benefits in heavy workload cases.
Table 3: The heavy load results of sequential runs with single BF client
| Workload | Throughput (Sample Per Seconds) |
Execution Time (seconds) |
Total Samples | GPU Utilization (%) |
GPU Memory Usage (MB) |
|---|---|---|---|---|---|
| mobilenet | 12852 | 100 | 1285200 | 95 | 1525 |
| resnet | 4335 | 100 | 433500 | 98 | 1254 |
| ssd-large | 112 | 100 | 11200 | 100 | 1958 |
| ssd-small | 5817 | 100 | 581700 | 97 |
1780 |
Table 4: The heavy load results of parallel runs with 4 BF clients
| Workload | Throughput (Sample Per Seconds) |
Execution Time (seconds) |
Total Samples | GPU Utilization (%) |
GPU Memory Usage (MB) |
|---|---|---|---|---|---|
| mobilenet | 3945 | 400 | 1578000 | 100 | 6488 |
| resnet | 1144 | 400 | 457600 | 100 | 6488 |
| ssd-large | 35 | 400 | 14000 | 100 | 6488 |
| ssd-small | 1462 | 400 | 584800 | 100 | 6488 |
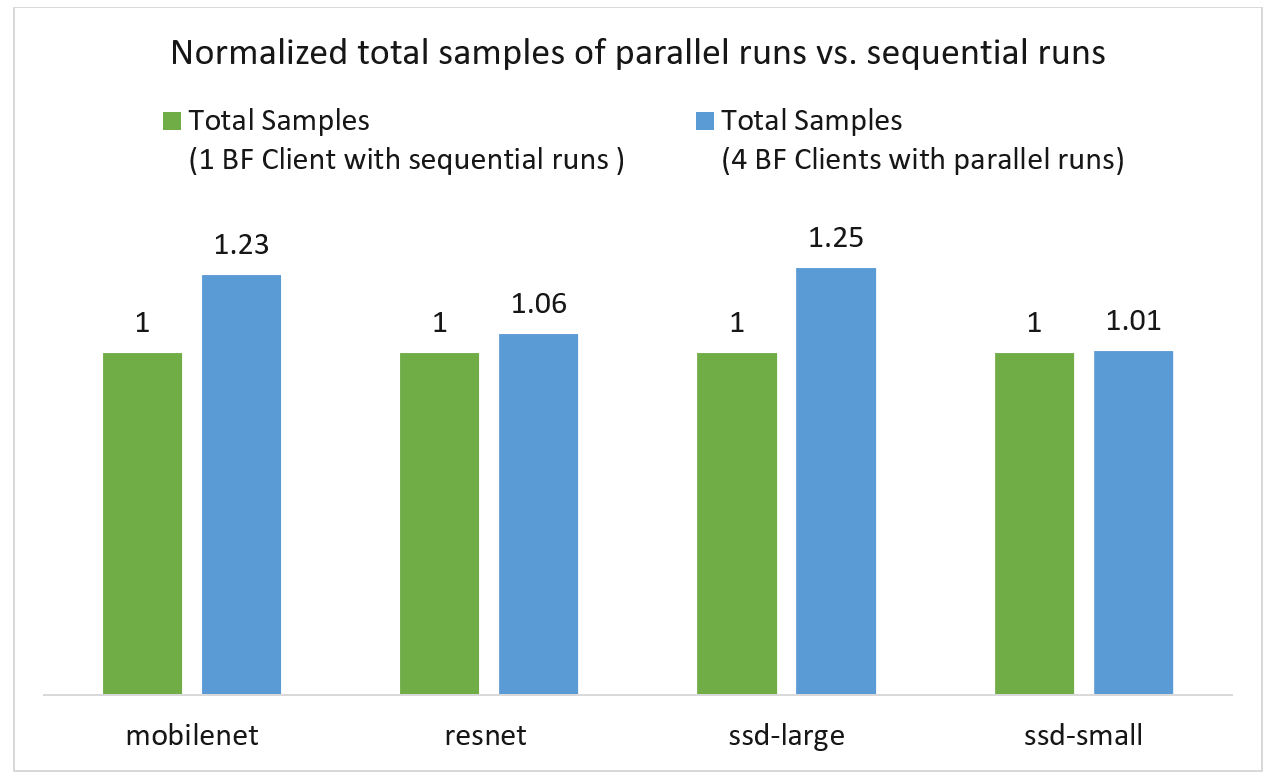
Figure 5: Comparison of total completed samples of heavy workloads
Please note that the performance gain in this experiment is achieved with a careful selection of batch sizes for GPU-based inference as described above. For smaller or larger batch sizes, the performance benefits of sharing GPU can be lower, based upon our observations.
The Interpretation of Dreams—A Strategy for Empiricists, too
So, have we achieved our hopes and goals? Quoting the fortune-telling Magic 8-Ball we won at a carnival many, many years, ago… “Signs point to yes”.
This blog only looks at a single performance benchmark, but yields the throughput and utilization increases we posited.
The other benefit we were interested in was also achieved, albeit, more implicitly. We ran multiple applications without blocking behavior. In other words, concurrency itself was demonstrated.
While further testing and additional applications should be run, we can summarize our conclusions so far:

- Applications with appropriate performance profiles—smaller memory requirements, lower utilization—run successfully in parallel on shared, partial GPUs, instantiated on single physical GPUs. They can fill each other’s “gaps” and thereby increase the GPU utilization and throughput.
- Even jobs with seemingly 100% GPU utilization, do not necessarily use all compute resources. GPU partitioning lets you eke out additional parallelism.
- Several brief jobs can be run at the same time as a long-running job. Blocking is eliminated and all users get to make progress.
It’s a Wrap—A Strategy to Stop Typing “A Strategy for <Insert Barely Applicable Metaphor>, too”
In this blog we have only been able to look at a very small set of benchmarks, but have shown there is reality to the value proposition of partitioning GPUs. vSphere Bitfusion has a true capability to share a single, physical GPU as multiple, smaller GPUs and make them available for concurrent use to several clients. When parallel applications share a GPU, the GPU utilization rises and users do not block each other.
The dynamic nature of vSphere Bitfusion is especially helpful. Moment-by-moment, client-by-client, the demands on hardware acceleration change. Having the GPUs in a pool of remote servers frees the users to concentrate on their individual tasks, while letting the technology exploit the sharing opportunities, both in parallel and across time.