
Stretched Clusters and VMware Site Recovery Manager
Introduction
When using VMware vSphere™ to virtualize your environment, a primary consideration for architecture is how to best maximize the availability of the services provided by the virtual machines. Availability solutions can be designed to improve the resiliency of local systems or entire sites and fall broadly into the categories of downtime avoidance and fault recovery.
Traditional data center architectures had rigid distinctions between high availability and disaster recovery. High availability was considered an automated failover solution within a single datacenter. Whereas, disaster recovery was a manual process for recovering workloads at a recovery site from replicated data. Recently, data center architects have begun to look at solutions that blur these original distinctions. These solutions include newer architectures such as stretched clusters that span sites as well as disaster recovery automation tools such as VMware vCenter Site Recovery Manager (Site Recovery Manager). The ability to increase the distance for clustering a high availability solution and the significant improvement in disaster recovery automation solutions has led customers to consider the deployment of these solutions in an attempt to deliver workload mobility, availability, and disaster recovery-all within one solution.
While these solutions are intended to help improve the availability of services, they have different primary goals:
- Stretched clusters offer the ability to balance workloads between two datacenters, with non-disruptive workload mobility enabling migration of services between geographically close sites without the need for sustaining an outage. The capability of a stretched cluster to provide this active balancing of resources is the primary benefit and design goal of a stretched cluster.
- Site Recovery Manager offers a different primary goal, focused primarily on configuring, automating, and reporting on a repeatable and robust disaster recovery process. The primary goal of Site Recovery Manager is to provide managed and consistent automated processes for restoring services after an outage, coupled with non-intrusive testing and reporting for routine confirmation of the capability of restored services.
The purpose of this paper is to clarify some of the concepts involved with vSphere site availability and to help understand the use cases for these availability solutions in the vSphere landscape. The intent is to provide guidance not in terms of purchasing decisions or products, but in terms of what various technologies intend to do and how to best achieve availability goals for your environment.
Often, Site Recovery Manager is held up in the market in opposition to stretched clusters. This is a false dichotomy as they are different tools that provide different solutions; both solutions enhance service availability, while stretched clusters focus on data availability and service mobility Site Recovery Manager focuses on controlled and repeatable disaster recovery processes to recover from outages.
Terms and Definitions
Availability solutions can be designed to improve the resiliency of either local systems or entire sites and fall broadly into the categories of disaster avoidance or disaster recovery.
Overview
Availability solutions can be designed to improve the resiliency of either local systems or entire sites and fall broadly into the categories of disaster avoidance or disaster recovery. When designing the architecture of a vSphere environment for availability, it is important to understand the terminology for these categories and thereby distinguish the purpose of an individual technology.
Local Availability
Solutions designed to help increase the uptime and availability of services within a geographically localized environment. Proactive management can help avoid service outages with use of technologies such as VMware vMotion™ (vMotion) and vSphere Storage vMotion (Storage vMotion). Rapid response to localized system failures with technologies like VMware High Availability (VMware HA) and VMware Fault Tolerance (VMware FT) decrease service outages or avoid outages entirely, respectively.
Site Availability
Site level protection includes solutions that will provide either non-disruptive proactive avoidance or rapid recovery from outages or major events that threaten the productivity of an entire site. Site availability solutions can fall into proactive disaster avoidance solutions or rapid recovery models under the category of disaster recovery. The assumption with site availability solutions is that a primary datacenter is either unavailable or is no longer the preferred location to run services. One important design factor of site availability solutions is that a recovery site must have sufficient available capacity to host critical workloads after a failure of the primary site. This may entail shutting down or suspending workloads to free capacity.
Orchestration and Dependencies
Recovery of an environment from an outage can require very specific sequencing of application startup. Virtual machines may contribute to a service that has dependencies on other systems or on other virtual machines. In order to ensure service resumption, orchestration is able to provide a predefined set of steps that should be followed for a recovery of a service, prioritize for startup of individual virtual machines and define dependencies that must be met. For example, in some cases availability of a specific subsystem or set of virtual machines must be running before starting dependent services.
Disaster Avoidance
This is a process that allows proactive behavior to avoid an impending outage to services. Disasters tend to affect an entire site or have an impact on the services of the entire site even if only a partial site failure is sustained. Disaster avoidance technologies allow for configuration of a vSphere host, cluster or an entire site in such a fashion that irrespective of disaster, the services being provided will continue with minimum interruption. In most cases, disaster avoidance involves brief outages to services at a site followed by an orderly restart at a recovery site. A minimum outage sustained under controlled circumstances is typically considered acceptable as an alternative to sustaining an uncontrolled and extended outage associated with a true disaster.
Downtime Avoidance
Downtime avoidance differs from disaster avoidance as the former migrates the workloads between systems or sites with no downtime and no loss of data. vSphere technologies such as vMotion and Storage vMotion facilitate moving virtual machines or virtual machine storage with no interruption of the services they provide. Configuring vMotion and Storage vMotion requires that vSphere hosts are managed within a single VMware vCenter Server datacenter object and are configured with shared access to storage and network segments.
Disaster Recovery
This process assists rapid recovery from unplanned outages that bring down services in a fashion that makes local recovery within an acceptable time unlikely. In disaster recovery scenarios the goal is to rapidly return to operational status of the services, usually in a different datacenter in a safe location. Disaster recovery solutions will help automate return to operations of services that have stopped due to catastrophic failure of infrastructure.
High Availability and Fault Recovery
Highly available systems are designed to recover services following an unplanned outage. High availability technologies reduce the period of outage sustained by services during failure, allowing for a rapid recovery of virtual machines. Traditional high availability clusters provide automated fault recovery: it is a reactive technology that responds to unplanned outages at the host hardware, vSphere and virtual machine operating system levels and restarts virtual machines as appropriate.
Stretched Clusters
Stretched clusters are traditional vSphere Clusters that are configured with host systems located in multiple locations. The location might be in different floors of a datacenter, different buildings or facilities in a metropolitan area. Stretched clusters are designed to take the capabilities of high availability and downtime avoidance and extend the implementation of these features across sites. While stretching clustered systems between sites may initially appear to provide disaster recovery capability, there are several limitations discussed later that restrict their efficacy as a disaster recovery solution.
Enhancing Local Availability and Reducing Downtime
Solutions designed to enhance local system availability focus on technologies that increase the capabilities of the infrastructure to ensure reliability
Overview
Solutions designed to enhance local system availability focus on technologies that increase the capabilities of the infrastructure to ensure reliability or rapid recovery of workloads running within a site.
vSphere assembles VMware hosts into aggregate systems called clusters that enable resources of storage and network to be shared among multiple systems and made available to virtual machines that can now run on any of the hosts within the cluster.
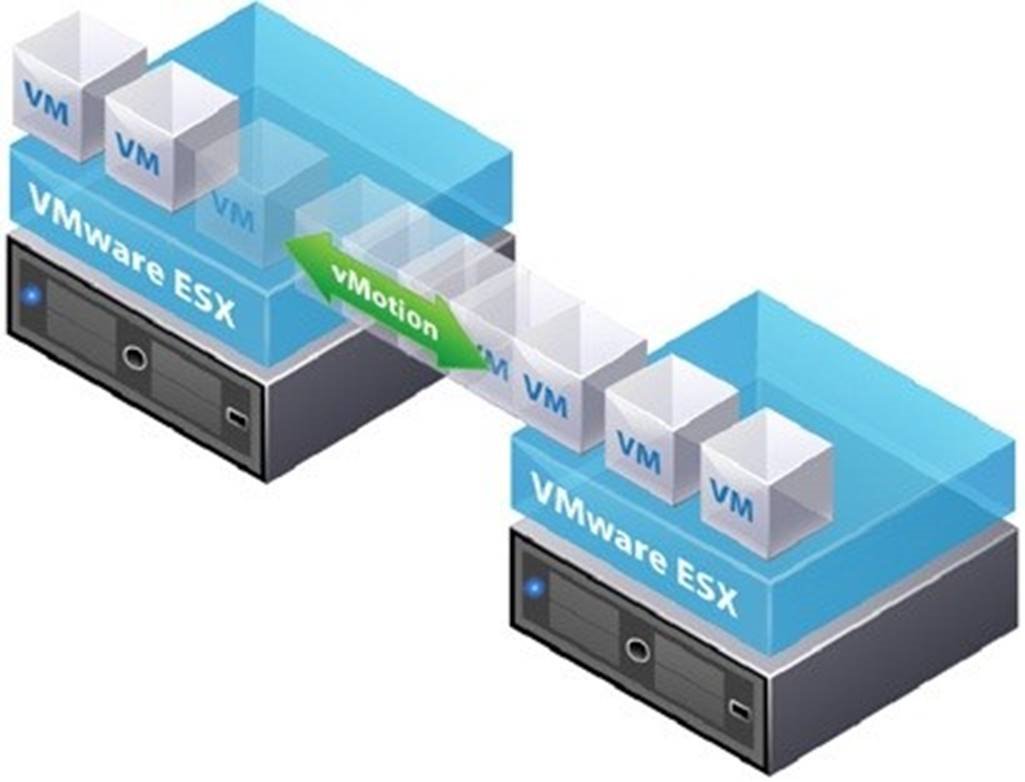
Figure 1. vMotion in a vSphere cluster allows online migration between hosts
From an availability perspective, clustering gives several benefits, specifically enabling the technologies of vMotion, Storage vMotion and VMware HA. vMotion and Storage vMotion enable advanced proactive management of the environment for numerous purposes. For availability the benefit lies in avoidance of outages associated with planned maintenance or known impending issues.
vMotion enables the administrator to migrate running virtual machines from one host to another online and in real-time with no loss of data or interruption to the service. This may be done on an individual virtual machine basis or en masse with a number of virtual machines. Even an entire host may be evacuated of running virtual machines by such actions as placing the host into “maintenance mode”. Maintenance mode will automate the process of evacuation by executing a vMotion against all virtual machines in the host and onto other systems within the cluster.
With this capability of vMotion, physical hosts that are targeted for maintenance or that are experiencing failures may safely be powered off and fixed or replaced without sustaining any outages to the virtual machines providing services. In this sense vMotion allows for localized downtime avoidance through proactive manual intervention by an administrator.
In a similar capacity, the capability of Storage vMotion within a cluster allows for avoidance of outages associated with datastores or the storage subsystems attached to the cluster. Storage vMotion will migrate the disk files of a virtual machine from one storage location to another. This migration is done online and in real-time with no interruption or outage of the virtual machine that is being migrated. With this mechanism outages associated with storage maintenance can also be avoided. If a datastore needs maintenance (for example an array is being retired, fixed or replaced), Storage vMotion can allow for evacuation without impacting the virtual machines resident thereon.
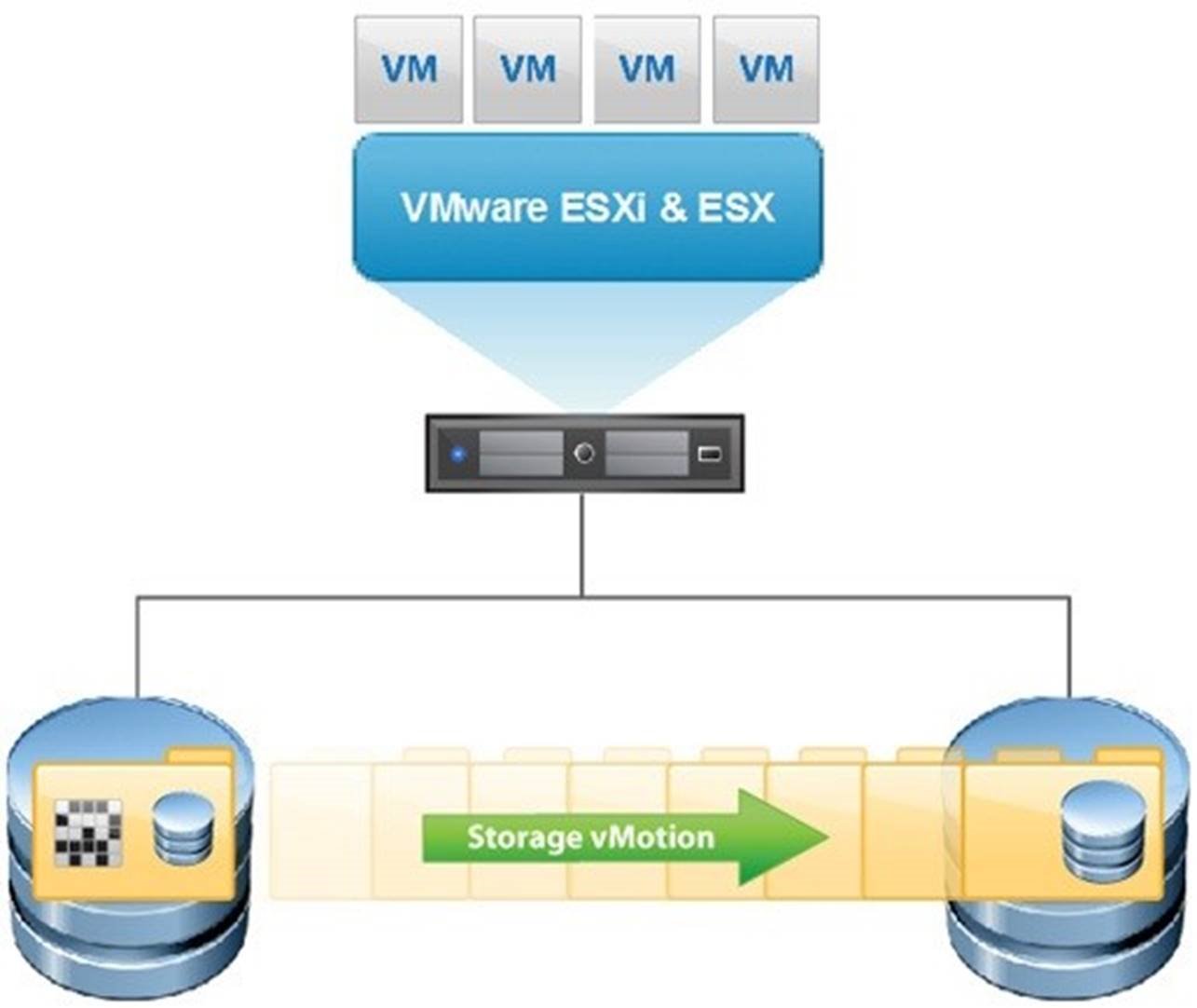
Figure 2. Storage vMotion allows for online migration of virtual machines from one datastore to another
Both of these migrations increase local availability through manual proactive management: If hosts, networks or storage subsystems experience problems or are required to be changed in an intrusive fashion, migration through vMotion can avoid outages that otherwise would be required.
VMware HA is a further capability of vSphere clusters that is designed to enhance local availability through rapid and automated response to unplanned outages.
VMware HA tracks responsiveness of virtual machines and vSphere hosts to ensure systems are running correctly. If a virtual machine or a vSphere host stops responding for any reason, VMware HA will detect this and attempt to restart the impacted virtual machines.
Outages addressed by VMware HA are reactive by nature. Rather than intervening before a failure, VMware HA will only work in response to an outage that has already occurred. For example, possible outages to which VMware HA will respond are: if a host has become isolated from the network; if storage paths have become unavailable; if a virtual machine has crashed and is no longer responding; and many other situations. Irrespective of the nature of failure, VMware HA is designed to monitor the health and responsiveness of the cluster nodes and respond to failures at the hardware, vSphere and virtual machine operating system levels, and respond by rapidly restarting the virtual machines that are no longer available due to the outage.

Figure 3. VMware HA rapidly recovers virtual machines on other hosts
VMware HA is strongly capable of enhancing local system availability, but was originally designed to track systems within a datacenter. Should a major portion of the environment fail, constituting a large number of virtual machines, VMware HA is not designed for complex recovery scenarios in which virtual machines start sequences that need to be orchestrated or for environments with complex interdependencies. Nor can it provide test capabilities, audit reports, virtual machine reconfiguration or geographically distant multisite recovery. It excels at local rapid recovery of virtual machines in response to an unplanned outage.
In almost all vSphere implementations configuring a highly available cluster is advantageous. The requirements are minimal and mostly focus on the use of shared storage. It is easy to implement, adds little cost and dramatically improves local availability by enabling proactive outage avoidance with migration capabilities as well as rapid recovery from unplanned outages through automated crash recovery. It is important to note that in almost all cases, an outage to which VMware HA responds will restart the affected virtual machines in a crash-consistent state.
Multisite Stretched Clusters
A stretched cluster is a model of a VMware HA/DRS cluster that is implemented with a goal of reaping the same benefits that high availability clusters provide to a local site in a geographically
Overview
A stretched cluster is a model of a VMware HA/DRS cluster that is implemented with a goal of reaping the same benefits that high availability clusters provide to a local site in a geographically dispersed model with two datacenters in different locations. A stretched cluster is, at its core, architected and built on the premise of extending what is defined as “local” in terms of network and storage to allow these subsystems to span geographies, presenting a single and common base infrastructure set of resources to the vSphere cluster at both sites. It is in essence stretching storage and the network between sites.
The primary benefit of a stretched cluster model is to enable fully active and workload-balanced datacenters to be used to their full potential while gaining the capability of migrating virtual machines with vMotion and Storage vMotion between sites to enable on-demand and non-intrusive mobility of workloads.
Due to the technical constraints of an online migration of virtual machines, these datacenters have some requirements that must be met prior to consideration of a stretched cluster implementation: they must be closer than approximately 100 kilometers apart (due to latency requirements) with a minimum of 622Mbps redundant network links and they must have round-trip time latency of 5 milliseconds or less (10ms or less for vMotion if using vSphere Enterprise Plus licenses, 1ms or less for cross-site fault tolerance). The network requirements are due to the fact that although there are two physical datacenters, they are now being managed as a single logical datacenter.
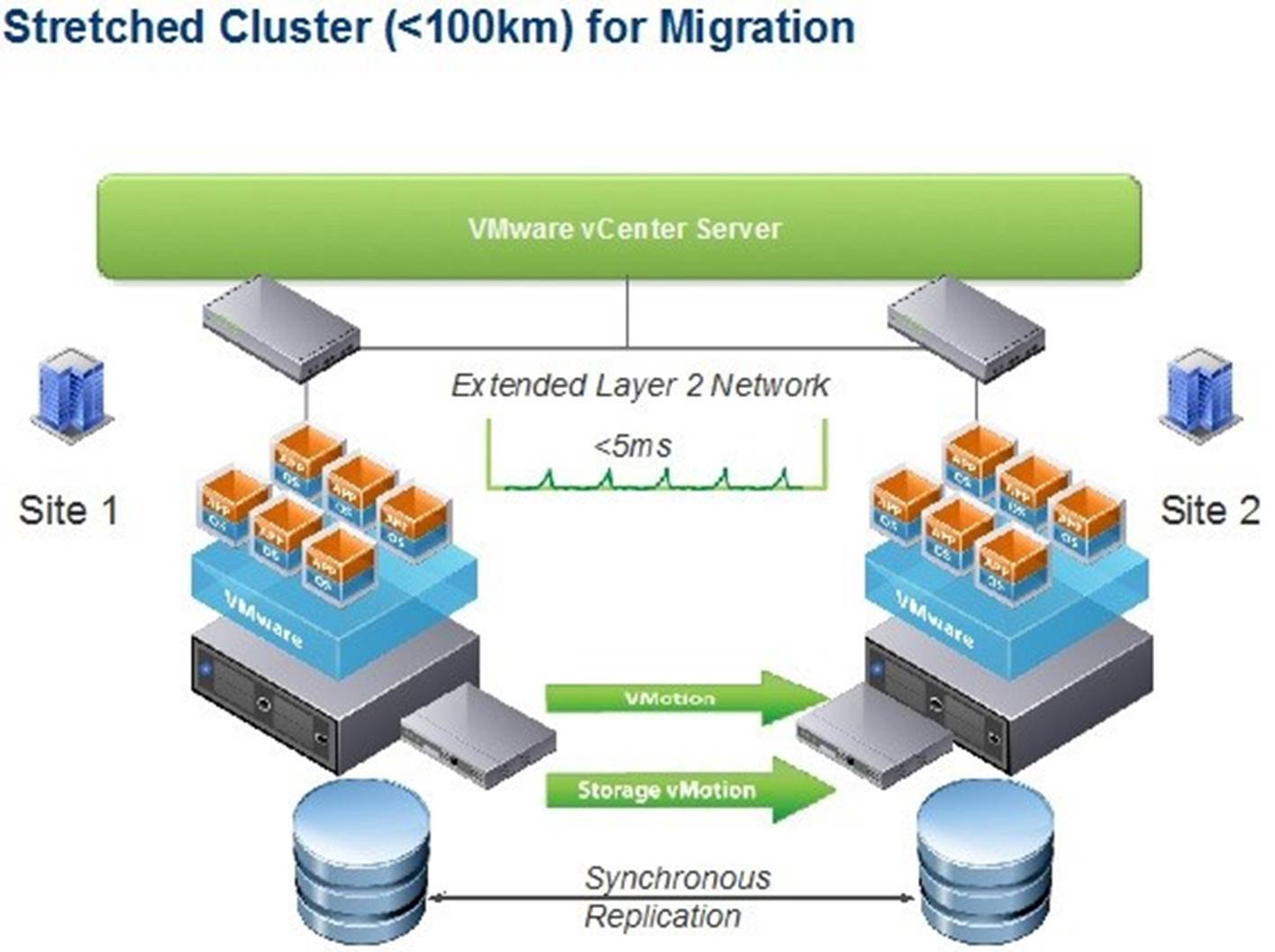
Figure 4. Stretched clusters provide cross-geography proactive disaster avoidance
The storage requirements are slightly more complex. A cluster requires what is in effect a single storage subsystem. In this design, a given datastore must be able to be read and written to, simultaneously at both sites. This precludes traditional synchronous replication solutions, as they create a primary/secondary relationship for replicated data and storage devices. With stretched clusters the storage subsystem must be able to be read and written to from both locations and all disk writes are committed synchronously at both locations to ensure that data is always consistent regardless of the location from which it is being read. This difference from traditional replication models requires significant bandwidth and very low latency between the sites involved in the cluster. Increased distances or latencies will cause delays to writing to disk, making performance suffer dramatically and will disallow successful vMotion between the cluster nodes that reside in different locations.
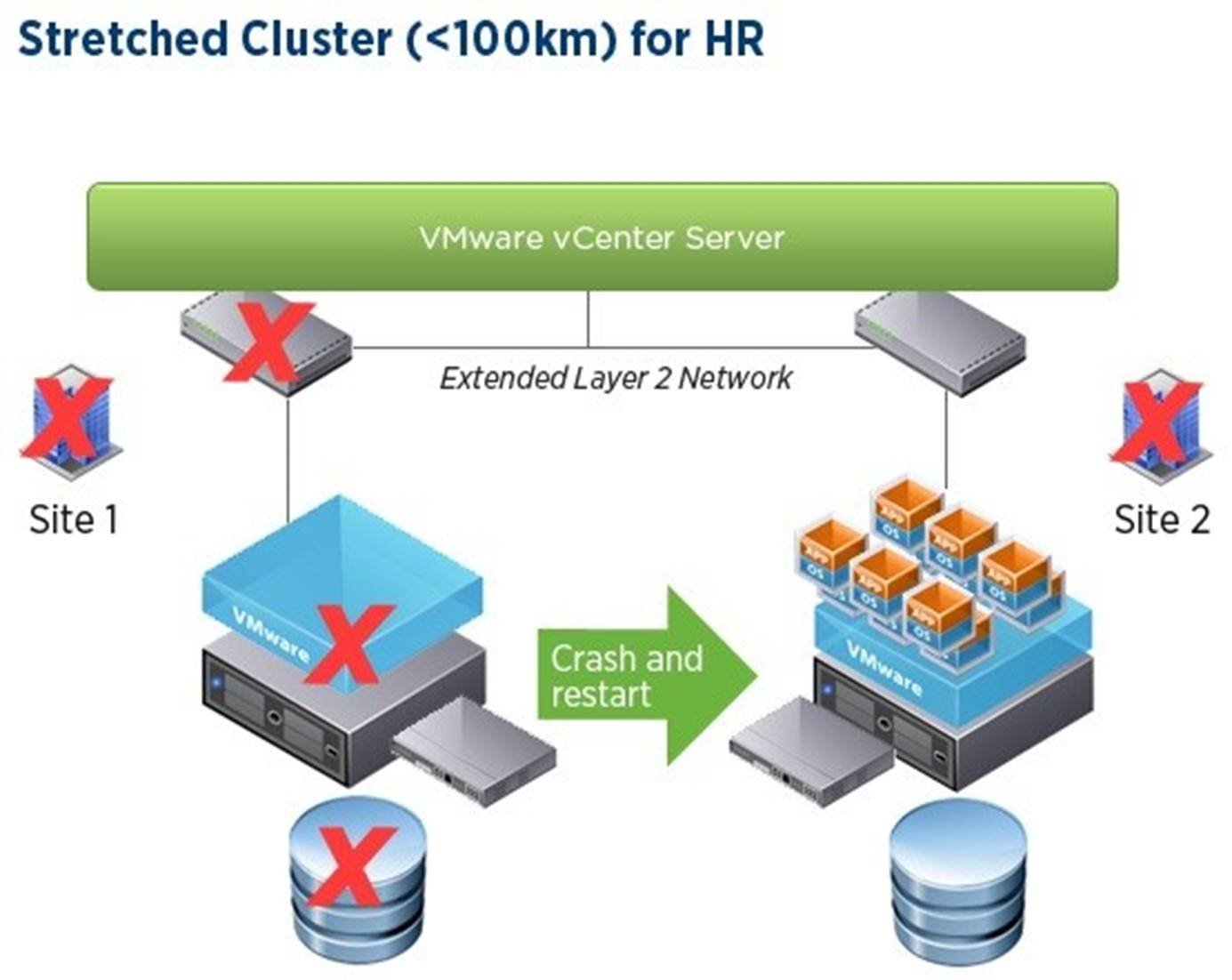
Figure 5. Stretched clusters are sometimes used for basic disaster recovery
To differentiate a stretched cluster from a local cluster we need to look at the reason for implementing each. A local cluster is designed for improved availability from both a proactive management perspective with vMotion and a reactive local fault recovery model with VMware HA failover.
A stretched cluster is designed primarily with the goal of enabling datacenters to be utilized highly, in an active-active fashion and to enable vMotion between sites in a manual and proactive downtime avoidance model similar to a local cluster.
While a stretched cluster will allow VMware HA to work across physical sites, there are major architectural and operational considerations that must be thoroughly examined to understand why the strength lies in workload mobility and downtime avoidance rather than in disaster recovery.
Fundamentally, a stretched cluster is operating at the disk and network subsystem level and extends the base resources available to vSphere. The primary reason for implementing a stretched cluster is to take advantage of capabilities such as vSphere clustering, VMware HA, vMotion and Storage vMotion and to allow these features to operate cross-site.
vMotion is highly useful with a stretched cluster for automated mobility of services between sites. Downtime avoidance can be enhanced with the ability to use these tools cross-site by enabling a site to be evacuated to another through the use of inter-site vMotion.
Since the primary goal of a stretched cluster is to have active workloads in both datacenters and be able to move between the two using vMotion, the architecture is designed around the capabilities of proactive management and vMotion.
A site level failure, by nature, is an unpredictable and often catastrophic or at best, massively intrusive to operations. During a disaster, it can be presumed that an outage will occur and some form of crash and cold restart will be required at the remaining recovery site.
How an HA cluster responds to this outage is through very basic controls to prioritize and start virtual machines. High availability clusters are not site aware in order to keep workloads automatically at their appropriate site, they are also not built to orchestrate large scale startup and sequencing or to handle dependencies of virtual machines. For extremely coarse sequencing of virtual machine start order, virtual machines can be manually configured to reside in one of three priority groups (High, Medium or Low), and VMware HA will attempt to start virtual machines with this categorization. The difficulty here is, if critical systems must start first before other systems that are dependent on those virtual machines, there is no means by which VMware HA can control this start order or handle alternate workflows or run books that handle different scenarios for failure. For example, if there is a partial site failure and vMotion is not working, it would require a manual process to halt and restart only the individual virtual machines that need to be failed over.
Moreover, there is no ability to ensure free resources and capacity to provide a successful failover. If cluster admission control is not extremely aggressive, there is no guarantee that all the virtual machines will be allowed to start, should a failure occur and the recovery site is not configured with sufficient resources to run the failed virtual machines.
Other technical considerations for using a stretched cluster for disaster recovery arise from very specific design choices with operational management impact. For example, ensuring virtual machines reside on the correct site for which their primary storage resides is a manual process and requires rigorous operational management of things like host affinity rules and will have impact on VMware HA admission controls.
Another consideration regards partial site failures: A matrix must be understood for all possible levels of failure ranging from virtual machine crashes to entire site failures and risk controlled at every level. Serious networking and storage investments must be made to mitigate the risk of a “split-brain” scenario in which each site incorrectly determines it needs to run all the virtual machines. Split-brain is one of the worst possible scenarios for a cluster as it can lead to virtual machines running simultaneously in two locations, both determining they are authoritative and try to broadcast themselves and process data. Storage capabilities can restrict split-brain virtual machines from writing to disk, but cannot stop the split-brain from occurring in the first place without considerable investment to mitigate the risk.
Stretched clusters add benefits to site-level availability and downtime avoidance, but introduce considerable complexity at the network and storage layers, as well as demanding rigorous operational management and change control. They also restrict the ability to use disaster recovery tools like Site Recovery Manager due to the predication on a single vCenter instance. This means that disaster recovery planning is now impacted as the capability to orchestrate partial site failover, to handle complex scenarios in which dependencies and timing are important and the ability to test or reproduce failover scenarios becomes impossible. Should a full inter-site link connection failure occur, a stretched cluster can introduce outages as now a non-catastrophic failure from a virtual machine processing perspective will create a high availability event and systems will automatically fail and restart between sites.
Stretched clustering has enormous benefits for downtime avoidance and site workload balancing: the ability to move running virtual machines between sites with no interruption; the ability to ensure your data is always available at two different locations; and the ability to evacuate an entire site without outage. These benefits, however, can make disaster recovery more complex: the goals of inter-site non-disruptive mobility and complete disaster recovery automation are currently mutually exclusive.
When to use Stretched Clusters
- When there is a requirement for inter-site non-disruptive mobility of workloads between active-active datacenters.
- When there are proximate datacenters with high-speed low-latency links.
- When enabling multi-site load balancing.
- When increasing availability of workloads through partial or complete site subsystem failures, that is, to recover from a total network, storage or host chassis failure at a site.
Scenarios to Avoid Using Stretched Clusters
- When orchestrated and complex reactive recovery is required.
- When the distance between sites is long (100km or more).
- When there are highly customized environments with rapid changes in configuration.
- When there are environments that require consistent, repeatable and testable recovery time objectives.
- If there are environments where both datacenters might simultaneously be hit with a common disaster.
- When disaster recovery compliance must be shown through audit trails and repeatable processes.
The fundamental choice between a stretched cluster and a traditional disaster recovery model is that each will provide a different benefit at the exclusion of the other. A stretched cluster provides live migration of workloads with load balancing of datacenters but with minimally controllable disaster recovery, while disaster recovery models provide controlled, repeatable, any-distance, orchestrated disaster recovery but require an outage and restart of all virtual machines and services being moved between sites.
Disaster Recovery - vCenter Site Recovery Manager
Disaster recovery models are designed primarily with the goal of a rapid recovery time objective after a site-impacting outage has occurred.
Overview
Disaster recovery models are designed primarily with the goal of a rapid recovery time objective after a site-impacting outage has occurred.
The assumption for a disaster recovery toolset is that the data is replicated from one or more sites to a recovery location at any distance afield and during an outage the environment and services that were running at the primary site can be restarted and recovered at the recovery site.
Since an outage is assumed, most disaster recovery solutions do not focus as closely on disaster avoidance technologies as much as disaster recovery orchestration models.
A proper disaster recovery toolset should include the capability to non-intrusively test failover scenarios. In test models a disaster recovery solution can simulate or isolate a test environment in which recovery scenarios can be run repeatedly to capture and fine-tune recovery plans, which are centralized, organized and automated.
Disaster recovery solutions provide not only this level of repeatable testing but also reporting and extensive customization capabilities during failover. For example, the abilities to rapidly change network settings of virtual machines and to execute scripts during failover are two very important components of a proper disaster recovery orchestration tool.
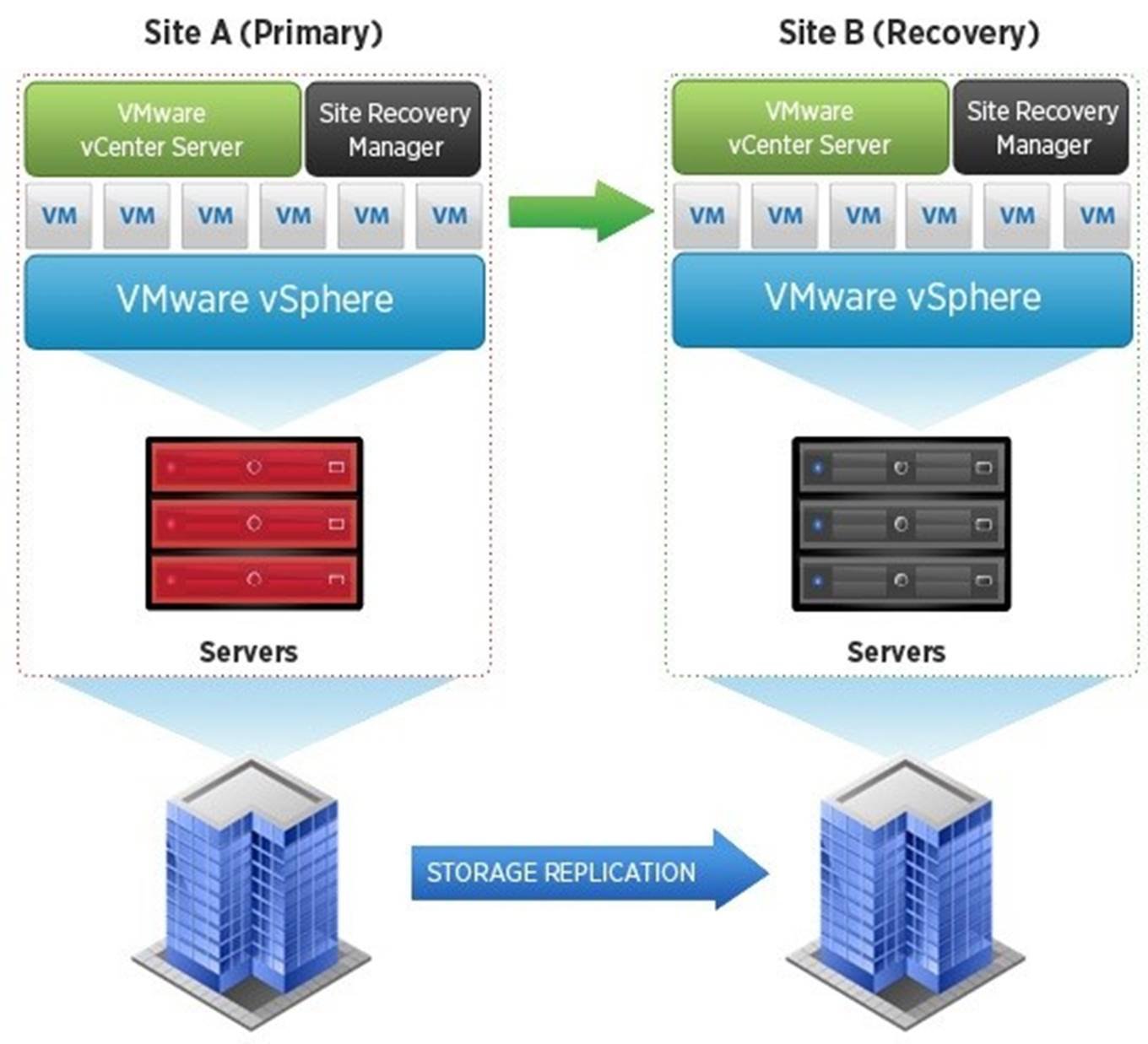
Figure 6. VMware Site Recovery Manager allows for orchestrated recovery after an outage
Site Recovery Manager, at its core, is built on the idea that failures and service outages are sometimes unavoidable even at a site level – the goal of a disaster recovery solution is to provide automated, centralized and repeatedly tested recovery plans to ensure that the recovery time is brief and that the process for recovery is known, automated, and easy to execute by any staff member either proactively, to migrate between sites, or reactively after sustaining an outage.

Figure 7. Full disaster recovery solutions can include many-to-one failover
One drawback with disaster recovery solutions when compared to stretched clusters is that Site Recovery Manager requires an outage to services during either a planned migration or failover between two sites. The advantage lies in the ability to have multiple recovery plans for multiple scenarios. For example, a disaster recovery solution should allow for both partial site, or application-specific failover, full site failover or even multi-site failover and allow the administrator the choice of which to run as appropriate in a given situation.
Another key component of Site Recovery Manager solution is the ability to handle multiple sites. With a disaster recovery solution a shared recovery model is supported wherein multiple sites can be configured to failover to a single location. Shared recovery models allow for enterprises with more than two datacenters to create a consolidated failover model or for remote office and branch offices to partake in a disaster recovery solution
When to use Site Recovery Manager
- When granularity for full site, partial site or individual application recovery is required.
- When there are services that can sustain an outage to migrate between sites.
- When complex recovery scenarios such as prioritization and dependencies are important.
- When consistent and repeatable recovery times are required for service level agreements or auditing purposes.
- When testing recoverability is a high priority.
- When more than two sites are being protected.
- For any-distance protection or failover.
- When virtual machine customization is important during failover (IP addresses, scripting, etc.).
Scenarios to Avoid Using Site Recovery Manager
- Recovery scenarios that can not sustain any outage at all to services.
- Where the priority of recoverability is lower than the priority of increased local or site resilience
Conclusion
This guide helps in understanding the options and fits for some of the available technologies and assists in decision-making for virtualized availability.
Overview
There are many options for choosing the best path to optimizing service availability of a virtualized environment. The chosen solution comes down to asking a few questions regarding the type of availability that is most important: Is the goal to balance workloads between sites? Do we need to prioritize workload mobility or ensure that we react appropriately to an unplanned outage? Can we sustain an outage of a virtual machine, a host, a subsystem or an entire site?
We hope this paper has been of value in understanding the options and fits for some of the available technologies and assists in decision-making for virtualized availability. Technology can assist in delivering a solution; but fundamentally, the priorities set by business drivers will dictate which solution is most appropriate for a given environment.
Appendices
Appendix A – Sample Scenarios and Solutions
| SCENARIO | SOLUTION |
| Balancing workloads between hosts at a local site. | Clusters with VMware DRS |
| Recovering from a virtual machine, host, or subsystem crash. | Clusters with VMware HA |
| Recovery of data following data loss or corruption | Restore from backup |
| Balancing and migrating workloads between two sites with no outage | Stretched clusters using vMotion |
| Automated restart of virtual machines following a site or major subsystem crash | Stretched clusters using VMware HA |
| Orchestrated and pretested site, partial site, or application recovery at a remote site. | Disaster recovery with Site Recovery Manager |
| Planned migration to move an application between sites. | Manual process with stretched clusters using vMotion (no outage required). Automated, tested and verified with Site Recovery Manager (outage required). |
| Evacuating a full site in advance of an outage | Manual process with stretched clusters using vMotion (may take considerable time to complete; potentially no outage required). Automated, tested and verified with Site Recovery Manager (outage required). |
| Many-to-one site protection | Disaster recovery with Site Recovery Manager |
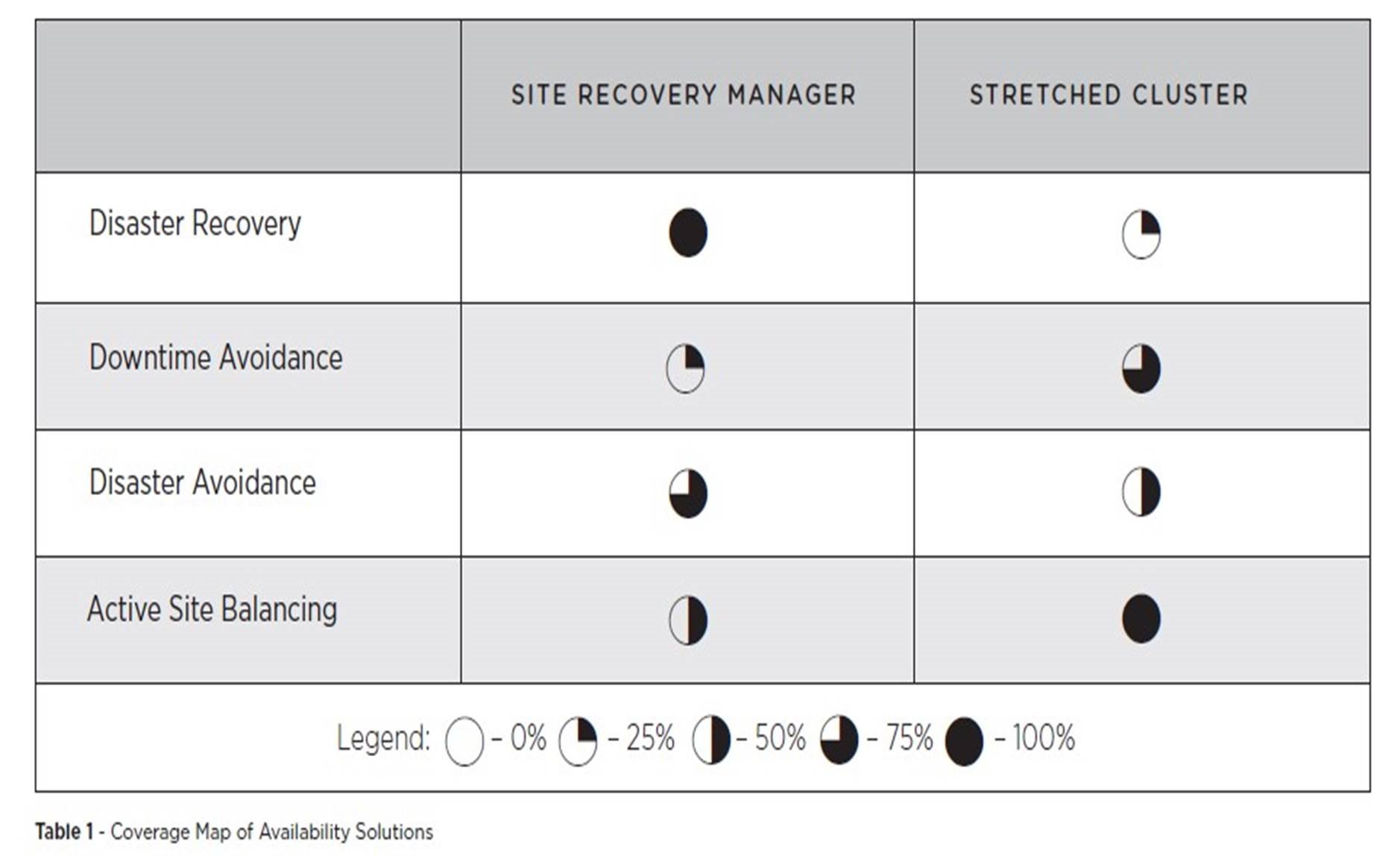
Appendix B – Comparison Details

- While Site Recovery Manager requires a restart of services after a disaster the testing, orchestration and repeatability of the solution gives it a full score. Disaster presumes an outage has occurred and crash recovery is the goal.
- Stretched cluster solutions also require a restart of services and the current lack of testing, orchestration, reporting, repeatability capacity assurance and predictable recovery times reduce its efficiency for disaster recovery.
- Site Recovery Manager requires an outage of services but can be invoked to avoid a larger outage.
- Stretched clusters allow for live migration between sites without outage but may be less efficient during impending outages due to the need to manually create capacity and the inherent time required for manual vMotion.
- Site Recovery Manager can allow for disaster avoidance through the use of a planned migration, but the requirement for a service outage and restart limits its effectiveness for disaster avoidance when avoiding service outage is the primary goal. The full orchestration, reporting, testing and repeatability of planned migrations give it added effectiveness.
- Stretched cluster solutions allow entire sites to be evacuated without a service interruption but are limited to geographically proximal sites that may easily be affected by a common disaster. The unplanned nature of disaster and time required to evacuate a site fully limits its effectiveness for avoidance during a crisis.
- Site Recovery Manager can migrate applications, services or groups of services between sites with orchestrated and repeatable processes but require an outage to services keeping it from doing active site balancing.
- Active site balancing of online workloads between geographies is the core strength of a stretched cluster allowing for non-disruptive workload migration.