
Determining GPU Memory for Machine Learning Applications on VMware vSphere with Tanzu
VMware vSphere with Tanzu provides users with the ability to easily construct a Kubernetes cluster on demand for model development/test or deployment work in machine learning applications. These on-demand clusters are called Tanzu Kubernetes clusters (TKC) and their participating nodes, just like VMs, can be sized as required using a YAML specification.
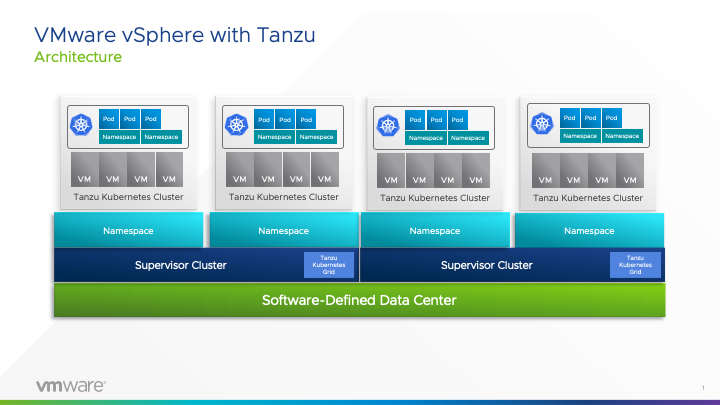
In a TKC running on vSphere with Tanzu, each Kubernetes node is implemented as a virtual machine. Kubernetes pods are scheduled onto these nodes or VMs by the Kubernetes scheduler running in the Control Plane VMs in that cluster. To accelerate machine learning training or inference code, one or more of these pods require a GPU or virtual GPU (vGPU) to be associated with them. Other pods will not need GPUs, and these non-GPU pods can easily co-exist in one TKC.
One of the key design tasks in getting a TKC ready for use by a data scientist is finding the appropriate GPU/vGPU memory allocation for one or more worker nodes, or VMs, in the TKC. This vGPU allocation is done on VMware vSphere with Tanzu through the “VM Class” mechanism. That method is described in detail here. GPU-aware worker node VMs for hosting pods are shown along with non-GPU worker VMs in the named "node pools" shown below in the YAML specification for building a TKC. You create a TKC by simply issuing a "kubectl apply -f <specfilename>" command when you have access to the appropriate namespace in vSphere.
Over time, a library of these VM classes will be constructed by a system administrator or a devops person, with different selections of vGPU sizing parameters. GPU framebuffer memory sizing and GPU core allocation (through use of the fractions of streaming multiprocessors inherent in MIG, for example) will differ for different VM classes – depending on the applications needs. The VM classes are then consumed by a Kubernetes platform manager, who wants to construct different-sized nodes in a Kubernetes cluster, for varying application purposes. The manager does this by choosing the particular VM class in the specification for a new TKC, as shown below. The example VM class used here is named “a30gpu-mig4-24c”, where the 24 indicates that this VM class specifies that all of the memory of the A30 GPU should be assigned to worker nodes of this class. That VM class is used under the gpuworker node pool. There can be more than one instance (VM) of that GPU worker type.

A YAML specification for creating a Tanzu Kubernetes Cluster in vSphere with an example VM Class named a30gpu-mig4-24c
At its core, the VM Class specification, constructed in the vSphere Client, identifies
- the hardware model of the GPU (such as A100, A30 or T4),
- the sharing mechanism - whether it is time sliced or multi-instance GPU,
- the compute nature of use, as opposed to graphics and
- importantly the amount of framebuffer memory to be allocated by the VM class
These values are all allocated when a VM is created of a named VM class. When the full amount of physical GPU framebuffer memory and the time-sliced form of vGPU are used together in a VM class, the user may choose to have multiple vGPUs assigned to the same VM class, giving multiple physical GPUs to one VM or node when the VM class is instantiated. That is currently the only combination allowed for the use of multiple vGPUs (and physical GPUs) on a single VM.
We can determine what VM class was used in the construction of any node in our TKC by using the command below, and searching for the appropriate VMclass entry:
kubectl describe tkc <TKC name>
Here is a snippet from the output of that command, that is executed in the correct Supervisor namespace.

A TKC cluster topology segment showing Node Pools and a custom VM Class used to create nodes with a vGPU profile
The key concern for the system administrator or Kubernetes platform engineer is to determine the correct VM class (and with it, the vGPU profile) that is to be assigned by the vCenter Server to this new VM. This choice determines the GPU power that is allocated to a TKC worker node in a cluster. The system administrator wants to ensure that memory sizing in this respect is done correctly, without over-allocating the GPU memory. Over-allocation would waste framebuffer memory on the physical GPU and possibly prevent other VMs from using it.
When creating a custom VM class, as described in this article a user may choose to allocate all of the framebuffer memory on a physical GPU to one VM – or just part it, so that other VMs can use the remaining part. For example, with an A30 GPU, a system administrator can choose 6, 12 or 24 GB of framebuffer memory to be used by a new VM class. The real question the system administrator should pose to the data scientist is: how much framebuffer memory is enough to satisfy the application’s needs?
This can be a tough question to answer, unless some tests are done with the real application using different vGPU sizes – and the performance of the application can be judged from there.
We conducted a test on this memory area using a sample ML classification application in our labs at VMware to see what would happen with various framebuffer fraction choices. As we discovered early on, the more GPU framebuffer memory you present to an example application written in Python, using the well-known TensorFlow framework, the more it will take for itself. This can distort our understanding of what framebuffer memory is actually needed by the ML application.
The application we chose to use is an image classification program that trains a neural network model on 60,000 images of clothing from the MNIST site. The application then runs a series of inference actions on one image and a set of sample images that it classifies. There are 10 classes to which any training object or test object can belong. The model accuracy achieved was in the 88-91% range, so not all of its inferences or classifications are correct. The idea in the experiment is not to get to a highly accurate model, but to assess the GPU framebuffer memory sizing that is appropriate for such an application. We used the “try it and see” method to get more insight into this. Below you see the application running in a Jupyter Notebook with model training in progress through its epochs. The pod that this application is running in is hosted on a vGPU-aware node in the TKC setup.
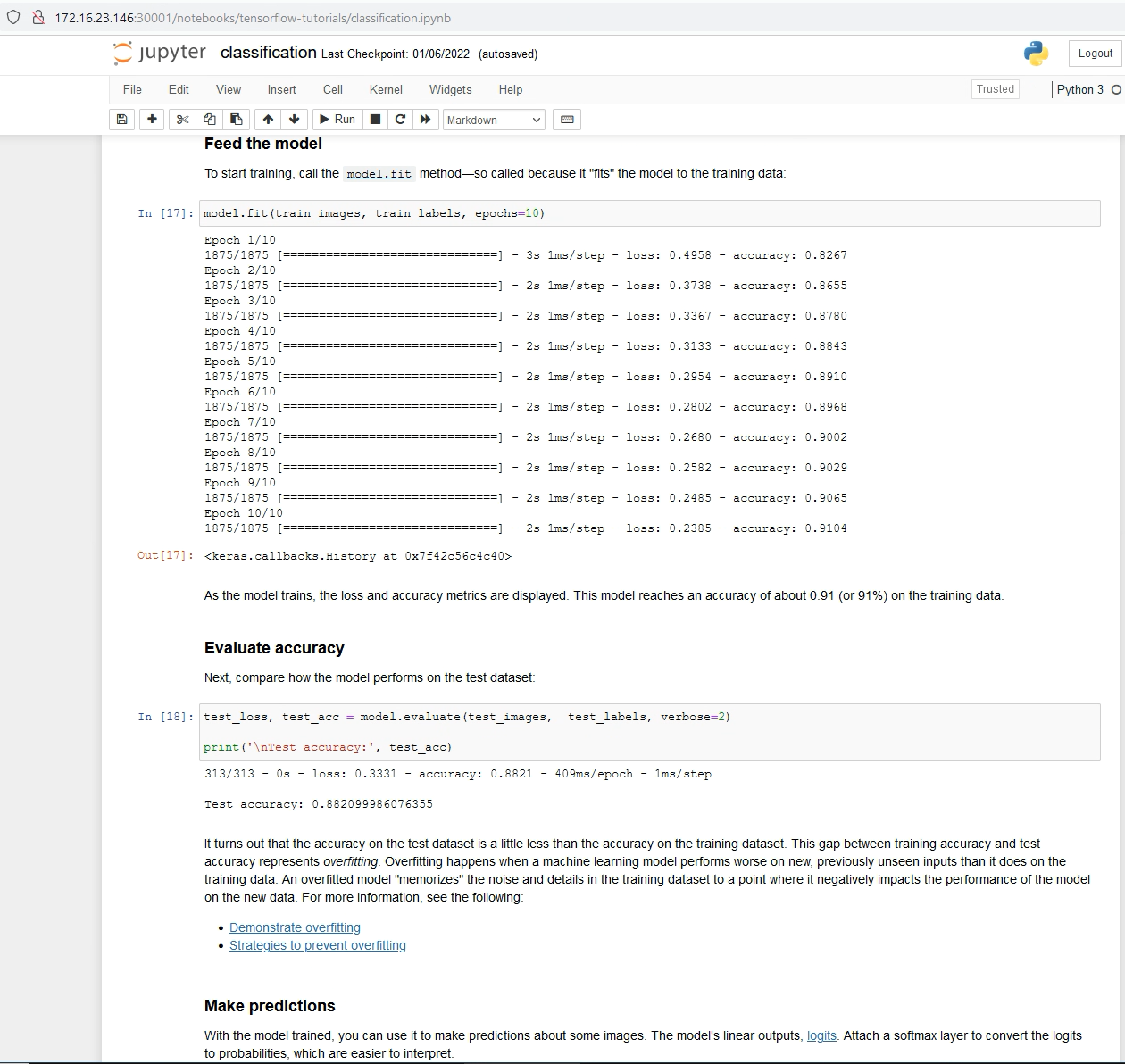
An example application running model training in a pod on a TKC cluster.
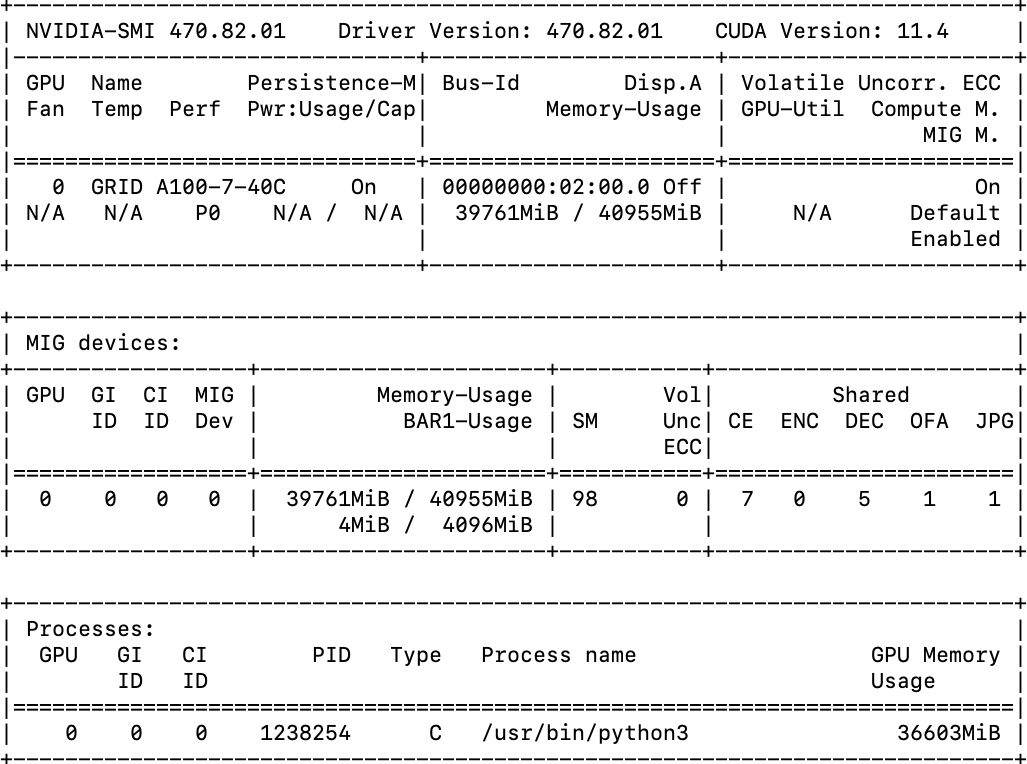
An initial test with an A100 GPU and a full framebuffer memory allocation (40GB) showed that the application could potentially use 36 of the total 40 GB of framebuffer memory allocated via the VM class. The vGPU profile allocated in the VM class is shown as "GRID A100-7-40C" below.
A subsequent similar test using the full 24GB of framebuffer memory on an A30 GPU, represented as a vGPU on the node, showed that the application appeared to take 21 GB of the total 24GB of frame buffer memory. We know that even with no process or pod using the GPU there is some memory taken up as overhead. In the example below, that overhead is 4 GB, leaving us with 20 GB of usable framebuffer memory. This is seen in the Memory-Usage area for an A30 full framebuffer allocation below.

Output from nvidia-smi on an A30 with no process running sand some memory used for BAR1 data,
Here is the same A30 GPU, now with the example TensorFlow image classification application running in it, where the vGPU attached to its hosting node was sized to use the full framebuffer memory. The application appears on the output here as a Python3 process.
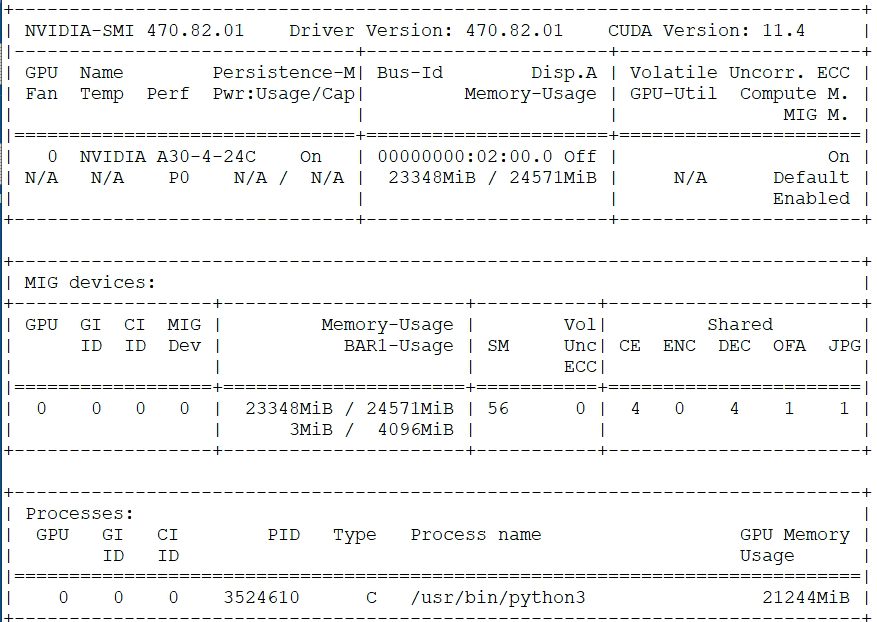
Output from nvidia-smi run on an A30 GPU while the test application is running, showing 21 GB of memory in use
Looking deeper into this high consumption of GPU memory, we found that TensorFlow uses an aggressive approach to acquiring GPU memory, such that it takes as much framebuffer memory as it can find, once the GPU begins to be used by the application code. To allow TensorFlow to instead grow its allocation of memory from a smaller starting point, we found a fairly simple piece of experimental code that addresses this issue. We inserted the lines of code into the highlighted notebook cell (at In [4] below) in the application.
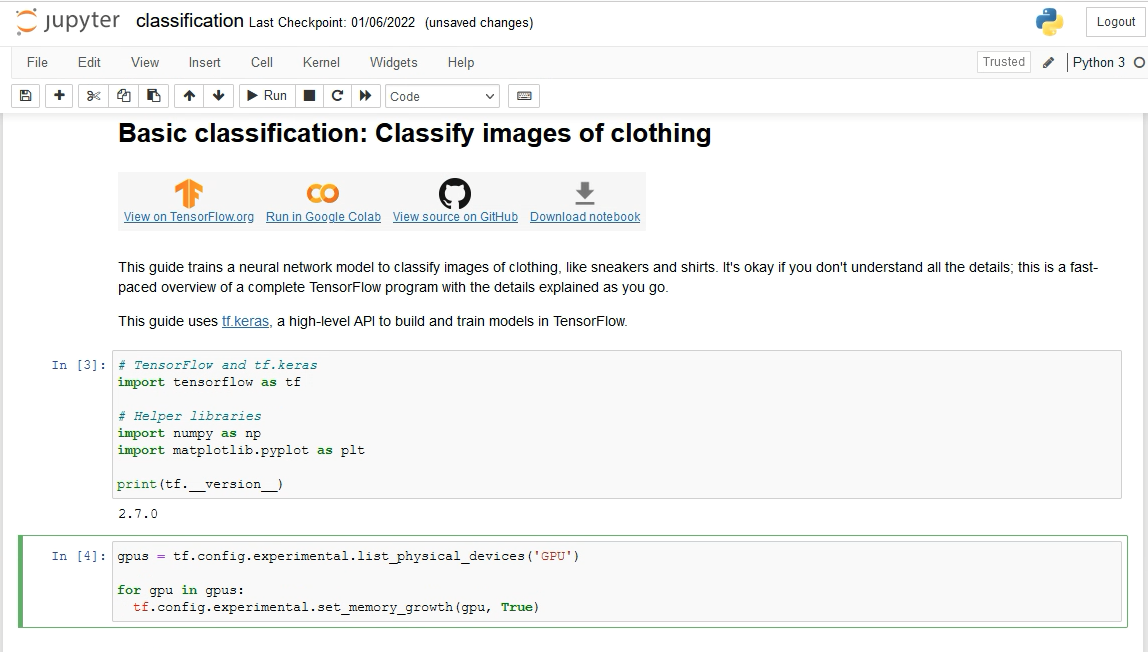
When this new version of the code was executed, the accuracy level achieved by the trained model was exactly the same at both training time and testing time. The wall time used up for training the model was not significantly different, less than a minute was taken in both the before and after cases. These are the critical factors to most data science practitioners. We saw a significant reduction in GPU framebuffer memory consumption with that new “set_memory_growth(gpu, True)” code executing. This new amount of GPU memory usage is shown in the last line of output below.
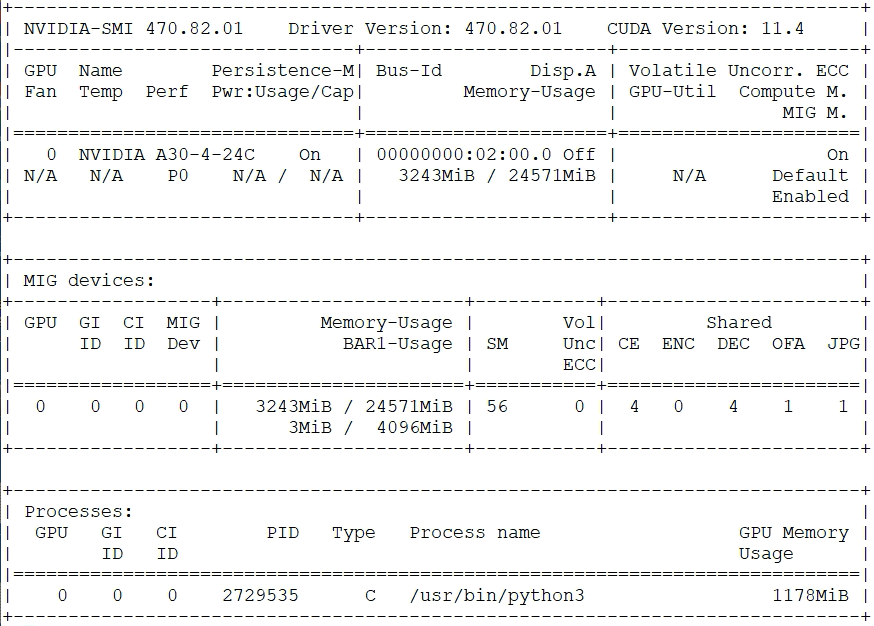
Nvidia-smi output with the application using lower GPU memory
In the last line of output from the “nvidia-smi” command above, we see that only 1.17 GB of GPU framebuffer memory is really needed – a saving of around 20 GB over the previous run. This is because TensorFlow, by default, aggressively takes all the free GPU framebuffer memory it can get, unless the memory growth feature is allowed by adding that extra code. With that "allow growth" code, TensorFlow becomes much more conservative in grabbing memory.
The implication of this is that the application developer and the person designing the VM (Kubernetes node) in which this code is executed both need to be aware of this memory growth pattern – and implement a strategy like the one used above, where it is applicable. We saw a similar result with the A100 GPU undergoing the same test. With the new memory growth code added to the application in that scenario, the framebuffer memory used was also considerably reduced, (from 36 GB down to less than 2 GB) as seen here.

nvidia-smi output for an A100 GPU, that is fully allocated to the node, with memory growth allowed in the application code
We believe that PyTorch may exhibit the same or similar memory consumption patterns, and so care must be taken when working memory sizing with this ML platform also.
Conclusion
Sizing of the Tanzu Kubernetes Grid nodes (i.e. VMs) that will have vGPU profiles assigned to them, via the VM class mechanism, requires some care. We have seen that wide differences can exist between two instances of the same application that take different approaches to GPU memory growth in TensorFlow. This becomes important at the point at which a system administrator/devops engineer or Kubernetes platform engineer is constructing a VM class with vGPU access in vSphere with Tanzu for use by a data science/ML developer.
References
Sizing Guidance for AI/ML Applications in VMware Environments
Deploy an AI-Ready Enterprise Platform on VMware vSphere 7 with VMware Tanzu Kubernetes Grid Service
vSphere 7 Update 2 vGPU Operations Guide
NVIDIA AI Enterprise Technical Documentation