
Project Radium Workflow — Simplicity and the 70's
Wherein we randomly mash up news about the Project Radium workflow demo with 70's tropes most fond to the decade's children.
Introduction — Feeling Groovy
The smiley face — So simple, so sunny. Drew a real-world grin on my third grade countenance. You'll share that inner glow, when you see how simple it is to use containers and Project Radium.
Machine learning applications frequently need you to install a long list of dependencies, ranging from frameworks (such as TensorFlow and PyTorch) and libraries to sets of drivers, especially accelerator drivers (such as CUDA). Installing all these components is daunting. And distributing your apps and models is a nightmare; you may have to walk 10,000 new best friends through the same installation procedure.
Unless...
Unless you wrap everything up in a container. Then, you do the daunting work once, and the nightmare turns into an avalanche of accolades and thank-you notes. Better yet, you get the appropriate base image from an accelerator device manufacturer's library and even you avoid doing the daunting.
For this reason, the machine learning community is heavily organized around containers. And for that reason, Project Radium relies on containers too.
We've created a video demo showing how easy it is to use containers under Project Radium. In particular, Radium removes steps that were required in Bitfusion, and Radium preemptively automates its way past some would-be new requirements. But first, let's quickly review what Project Radium is.
What is Project Radium? — Feeling UV
Black Light Posters (and don't forget fluorescent crayons!) — By turning UV into the visible spectrum, they appeared to the eye as a light source themselves. Project Radium makes deviceless machines appear to source their own accelerators.
Project Radium virtualizes GPU devices (as does Bitfusion) and other accelerators, as well. Users can dynamically allocate GPUs from a pool of remote servers, run an application using those GPUs, and then release them. Project Radium uses a different technology than Bitfusion and is being developed from the ground up. Its general-purpose approach supports multiple devices & device types, and multiple vendors. If you want a far-more thorough explanation read this blog.
Flow — Cocoa, not Orinoco — Feeling Movie
Willy Wonka & the Chocolate Factory — the standout children's movie of the decade; nothing came close. It had a chocolate river! Now that's a flow-state I can really get into.
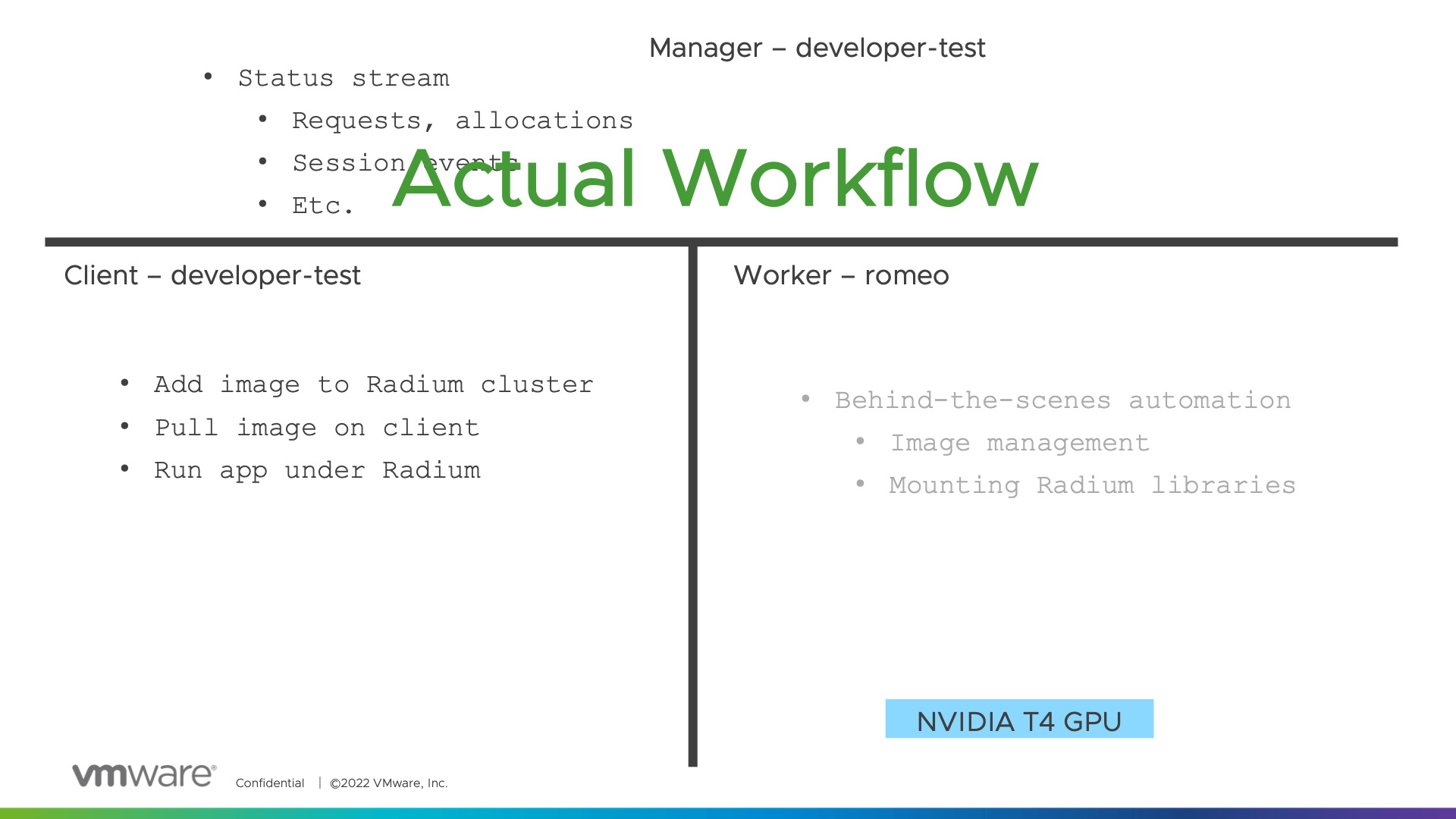
The better the virtualization, the more invisible it is — at least to the user. The admin behind the curtain may be working furiously to feed the illusion, but users are barely aware that their equipment is being shared and scheduled. Project Radium is not entirely invisible to users, but nearly so. The new Project Radium Demo shows that a data scientist's workflow is about the same, whether working in or out of the Radium environment.
Particularly, there are two things nicely hidden. There are two things you do not have to do:
- You do not have to make a derivative container image.
- When you run a container, Radium libraries and executables are mounted, automatically, and everything will be there. It even detects your linux distribution to ensure you get the right code. You do not install Radium and save a new image. And you do not make new images every time the base image or Radium has an update.
- You do not have to log on to the pool's GPU machines.
- You, from your own working machine, register your image with Radium. Behind the scenes, Radium ensures all elements of the virtual environment pull the image. You do not have to act as an administrator beyond telling Radium which applications need virtual GPUs.
This keeps your workflow short and simple. If you are using docker, in addition to the two normal pull and run commands, your only nod to the virtualized environment is to register the image with Radium. The table below compares the non-virtualized and virtualized environments.
| Default (e.g. Docker) | Project Radium |
|---|---|
| docker pull $IMAGE | docker pull $IMAGE |
| radium images add $IMAGE. [register your image] | |
| docker run <args, options, etc.> | radium run <args, options, etc.> |
This workflow means data scientists perform their work all on their own client machines.
Conclusion — Feeling Juvie
Pong — Pinball was often seen as contributing to the delinquency of minors. Pong changed the universe. Can you even appreciate it if you weren't there? But good news! You are there for Project Radium.
If you've read all the way through, or just scrolled all the way down looking for the good stuff at the bottom, here is the link to the Project Radium Workflow Demo.

Just clicking through a collection of stills from Tommy is equivalent to three years exposure to the 1970's. This pinball wizard photo alone is worth 6 weeks. So, keep on truckin'!