
vSphere 8 Expands Machine Learning Support: Device Groups for NVIDIA GPUs and NICs

Data scientists and machine learning developers are building and training very large models these days with more extensive GPU memory needs. Many of these larger ML applications need more than one NVIDIA GPU device on the vSphere servers on which they operate or they may need to communicate between separate GPUs over the local network. This can be done for the purpose of expanding the overall GPU framebuffer memory capacity or for other reasons. Servers now exist on the market with eight or more physical GPUs in them and that number of GPUs per server will likely grow over time. With vSphere 8, you have the capability to add up to 8 virtual GPUs (vGPUs) to one VM. You can have even more than that with Passthrough (DirectPath I/O) mode, but our focus in this article will be on vGPU - as that gives us vMotion capability and more control over the VM's consumption. The capability to use multiple full physical GPUs for ML, represented as vGPUs in vSphere, is why customers now more frequently ask us about deploying multiple GPUs on a server - and how to best configure them. The expanded vGPU capability per VM, along with the new concept of "device groups" in vSphere 8 were implemented so as to tackle this customer need.
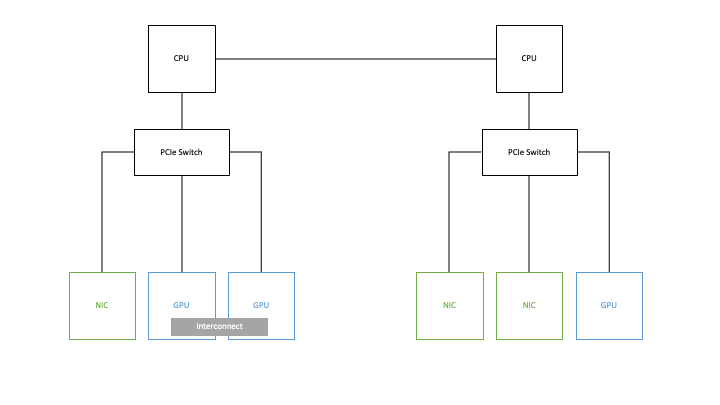
Figure 1: A simple example PCIe layout of NIC and GPU devices within a server
We start by looking at the ways in which multiple devices in servers are physically connected today. The physical device layout at the PCIe bus level (and at the inter-connect layer) can vary widely from one host server to another. GPUs or other devices can be located far from each other on the PCIe hierarchy or they could be close to one another. Communication between such devices is influenced heavily by their proximity to each other. This presents choices as to where a VM is placed by vSphere Distributed Resource Scheduler (DRS) at VM boot-up time. For this reason, choosing the most suitable physical server location for your VM to run on becomes very important. vSphere 8 gives the vSphere Client user much more automation and control over that choice of destination host, through the new concept of device groups.
An example physical server layout with two CPU sockets is shown in Figure 1 above. The NVIDIA NVLINK hardware (a communication device between GPUs) is shown on the lower left as an interconnect between two GPUs. You can read more detail on VMware’s performance tests done using GPUs with NVLINK here. The short summary is that NVLINK benefits your performance significantly with multiple GPUs in an NVLINK setup.
Secondly, the PCIe switch device setup on the right hand side of Figure 1 is becoming more common now in converged architectures, for faster GPU-to-NIC communication. The GPU-to-GPU connection over NVLINK represents scale-up of your GPU power to large models within a server, while the GPU-to-NIC communication is geared up for scale-out across multiple servers, for distributed training for example.
The decision on initial placement of a VM onto a particular ESXi host is made by vSphere DRS - with minimal need for administrator intervention. We look at how DRS in vSphere 8 makes its decisions about VM placement onto a host, when device groups are specified, in this article.
Up to now, the vSphere Client user has had very limited control over DRS’ decisions on initial VM placement onto a suitable host server. Device groups in vSphere 8 gives the user visibility to a collection of PCIe devices that are paired with each other at the hardware level, either using NVLINK or through a common PCIe switch.
This vSphere 8 device groups feature allows a set of PCIe devices to be presented to a VM as one unit for use in VM placement decisions by DRS in vSphere. The VM creator is establishing a contract, in adding a device group to the VM, that informs the DRS placement algorithm what it needs to see in the hardware for satisfying this VM's needs. Two examples of separate device groups in vSphere 8 are shown in the familiar "Add a PCIe device to a VM" dialogs as seen in the vSphere Client below.

Figure 2 : Two examples of different device groups in the vSphere 8 Client
A device group in vSphere 8 can be composed of a pair of GPUs that have one or more NVLINKs between them, allowing more efficient communication between them than via the PCIe bus. Notice that the GPUs are represented here within the device group names using their vGPU profiles. This dual-GPU device group is shown, as discovered automatically in the hardware by the NVIDIA host vGPU driver, in the first entry in the vSphere Client’s Device Selection dialog in figure 2 above. The "2@" in the device group name signifies two physical GPUs, represented as vGPUs. Note that the vGPU profile used in the device group name is a full-memory allocation, time-sliced one. A subset of the GPU memory in a device group specification is not allowed. Multi-instance GPU (MIG) profiles are not supported for device groups in vSphere 8. For now, the assumption is that if you are using the GPU in a device group, then you are allocating all of that device's capacity for this VM.
A device group can also be made up of four physical GPUs on a host server (again, represented as vGPUs) that all have NVLINK connections between them. This last example is not shown in the above screen. Figure 3 shows an outline of the two forms of NVLINK connections we have mentioned. In the second example on the right below, each GPU is connected over NVLINKs to three other GPUs on the same server.

Figure 3 - NVLINK connections between two and four physical GPUs in a server
Separately, a device group can be composed of a GPU device and a Network Interface Card (NIC) that share the same PCIe Switch for communicating together. This is seen in the second entry in the vSphere Client list above. The NVIDIA A100X and A30X converged cards have a built-in PCIe switch, for example, and there are other server hardware configurations that include a PCIe switch also.
The idea is that you would want those sets of devices, contained in a group, to be allocated together to your VM – instead of allocating a random available GPU or network card from just anywhere on your vSphere cluster. Device groups may only contain "full profile" time-sliced vGPUs. There is no partial GPU capability in a device group, in vSphere 8.
How Device Groups Differ from Earlier Methods
In vSphere Version 7 and earlier, you could choose to add a PCIe device to your VM, such as a GPU or a network card like an NVIDIA ConnectX-5 or ConnectX-6. These devices can also be seen from within Kubernetes pods that run within VMs, but let’s focus on the VMs, to begin with. In vSphere 7, the system administrator had to identify particular GPUs by their PCIe bus identity, and discover by hand that they had NVLINK between them, in order to identify them specifically together as a pair to one VM. You can read more about this in the Deployment Guide for the AI-Ready Enterprise Platform on vSphere 7. This choice of devices is made much simpler for the vSphere 8 user - with much more intelligence about these device pairings in the hardware.
Before vSphere 8, you chose to “Add a PCIe device” individually to your VM at configuration time in the vSphere Client. At this point, the guest OS in the VM is not booted and the VM is powered off. You could add a GPU, one at a time, either in Passthrough mode or in vGPU mode, up to a maximum limit.
For vSphere 8, this limit is increased from 4 to 8 vGPUs (and thus 8 full physical GPUs) for one VM.
You could also add a single SR-IOV virtual function (VF) from a Connect-X5 card in Passthrough mode to your VM. You choose the device in the “Edit Settings – Add New Device - PCIe Device” dialog in the vSphere Client. Notice however, that we say “the particular device” – indicating just one device to be added at a time. That single device addition capability is enhanced in vSphere 8 with the addition of a device group – using the same dialog sequence. With this, you don’t have to change the way you operate today with the vSphere Client to get to the available device groups.
With vSphere 8, we can allocate two individual GPUs to a VM separately, in vGPU mode. But the problem is that on a server with for example, 4 physical GPU devices, which GPUs are the ones chosen to add to my VM? If I were to choose one GPU that happens to have no NVLINK connection to my second GPU, then I have a sub-optimal setup for my application. Prior to vSphere 8, I had to do a lot of manual device discovery and setup to exercise control over this NVLINKed GPU decision. In the simpler cases, DRS chose the device for me – and I could only reference one GPU/NIC device at one time. That now changes in vSphere 8 to handle more demanding scenarios.
vSphere 8 with Device Groups

Figure 4 : Device groups for (a) two GPUs and (b) for a GPU and a NIC on the same PCIe switch on a server
The device group capability in vSphere solves the problem of pairing of devices as they get assigned to a VM, and as the VM gets placed onto the appropriate hardware at VM boot-up time.
You can think of this as
(a) Scaling up the power of your VM to two or more physically linked GPUs. This is the NVLINK case between two or four GPUs on one host, where NVLINK gives dedicated data bandwidth between the GPUs,
and
(b) Scaling out your application to multiple host servers, where the GPU-to-NIC communication within each host is traveling over the PCIe switch inside the host server to get the data in and out of that host. That is, the GPU and NIC are in a device group – and what that means is that the physical GPU and NIC card are connected to the same PCIe switch.
User Interface for Adding a Device Group to a VM
The mechanism for expressing a VM’s need for a device group is very familiar to those who added single PCIe devices to a VM using the vSphere Client in the past. In the “Edit Settings - Add New Device - Other Devices - PCIe Device” section of the vSphere Client, we are presented with a list of the available individual devices and the device groups on the servers in that cluster. These device groups are discovered by the NVIDIA GPU Manager (the NVIDIA host driver installed in the vSphere kernel) and then presented to vCenter and the vSphere Client for display.

Figure 5 - Edit Settings to Add a PCIe Device in the vSphere Client
From there, we can choose from the list of devices and device groups (seen in Figure 2) for specification to the VM. This list can include the applicable vGPU profiles that refer to the single GPU model, and virtual functions from an SR-IOV enabled NIC, along with the device groups seen earlier. The vSphere Client user assigns one of the device group entries to the VM. From the list seen in Figure 2, we pick a device group to add. In the example seen below, we chose the second device group from the list.

Figure 6: A device group that includes one vGPU and one ConnectX-6 NIC, associated with a virtual machine
Virtual Machine Placement
DRS in vSphere places a VM onto a particular host from a suitable set in the cluster. DRS operates at the vSphere cluster level and decides which hosts are candidates for hosting a VM based on resource availability and a set of compatibility checks.
DRS determines whether a host can fulfill the contract that is expressed by the VM when it requests a single device or a device group of a particular nature. It does this as part of its compatibility checks. When those checks are done, DRS then places the VM onto one of the chosen hosts. If a suitable device group in the server hardware within the cluster cannot be found to fulfill the request, then the VM will not be started.
vMotion and Device Groups
When a vMotion, or live migration across hosts, of a VM with an associated device group is done, the target host server for the move is again examined by vSphere DRS to determine whether that target host can fulfill the device group requirement. If that test fails, then the vMotion process will not complete.
Summary
Users of vSphere 8 now have the capability to express very precisely those device groups in the server hardware that are needed for their VMs. By automatically placing the VM onto a hardware configuration that is ideal for its needs, as expressed in the device group contract, DRS and vSphere deliver the best infrastructure to support the machine learning application within its VMs. Two examples of different device groups that include GPUs are shown in this article. Other forms of device group are expected to appear over time as the technical innovation continues at all levels of the hardware and software stacks.