
Bitfusion Jupyter Integration: It’s Full of Stars
This little 2020 odyssey describes how to integrate Bitfusion into Jupyter, allowing an AI/ML application in Jupyter notebooks to share access to remote GPUs.
Buy Jupyter!
If you are working with artificial intelligence and machine learning (AI/ML), there is a good chance you are a fan of Jupyter Notebooks or Jupyter Lab. The Jupyter project provides a very flexible and interactive environment. You can enter blocks of code, run them individually, and use results from one block as input to subsequent blocks. With Jupyter, you can iterate quickly through experiments, change configurations and run again, and you can integrate instrumentation and visualization. All your work is preserved or packaged as you would see it in a physical notebook, but one which lets you go back, change, and re-run any step of the work.
And, if you are running AI/ML applications, it is almost a certainty that you are a fan of GPU acceleration. Without acceleration, these applications run on geological timescales. On the other hand, GPUs are expensive resources that are 1) often idle and underutilized, and 2) difficult to share (which keeps them underutilized). VMware vSphere Bitfusion is a product that lets multiple client VMs, containers, and applications share remote GPUs from Bitfusion server VMs across the network. This sharing requires no modifications to the applications themselves. This blog demonstrates how to use remotely connected GPUs for AI/ML applications running in Jupyter notebooks.
Any block of code you create in a Jupyter Notebook needs to run on something, on some engine that handles your language and calls. This something in Jupyter parlance is called a kernel. For example, if a particular notebook needed to run python code, you should set up that notebook to run a python kernel. Jupyter lets you add personalized kernels to its menu of kernels. Then, each notebook can select the kernel it needs.
What we will do here is clone and modify the python kernel so that it launches with Bitfusion, and specifically, with a Bitfusion run command that allocates GPUs. You could create many such kernels: one that allocates a single GPU and another that allocates two GPUs. Or with Bitfusion partitioning, you could even create a kernel that allocates 31.4% of a GPU (meaning 31.4% of the GPU memory – remaining memory would be concurrently accessible by other clients).
By the Time I get to Venus
We’re going to take a journey of seven steps: three steps on the Bitfusion client machine (which will run Jupyter), three preparatory steps on a workstation (running a browser that interacts with Jupyter), and one last step to run an app within a notebook (from the browser on the workstation).
The setup in Figure 1 shows three machines: a Bitfusion GPU server, a Bitfusion client and a workstation. We are assuming we have already set up the Bitfusion server and client (the Installation Guide is on the Bitfusion landing page). We are further assuming we have installed the packages and dependencies to run TensorFlow benchmarks on the Bitfusion client.
The 7 steps are listed here:
On the Client:
- Install Jupyter Lab
- Make a Bitfusion kernel for Jupyter
- Launch Jupyter
On the Workstation:
- Set up port forwarding
- Browse to Jupyter through the local port
- Open the Bitfusion Notebook
Also on the Workstation:
- Run an application
For example purposes, we’ll assume:
- Bitfusion client has address 172.16.31.209
- Bitfusion client username is bf_user
- Workstation port 8001 will forward to 8234 on the Bitfusion client
.png)
Figure 1: Setup for Bitfusion Jupyter Integration
Kernel Never Mars the Finish
The Jupyter service requires a Bitfusion kernel (and for our purposes, Python too) to allow apps and notebooks to finish their connection to the GPUs.
Perform these next steps, 1, 2, & 3, on a Bitfusion client command line.
1. Install Jupyter Lab
sudo pip3 install jupyterlab
Jupyter lab is a later release than Jupyter Notebook, but includes Jupyter Notebook
2. Make a Bitfusion kernel and install in Jupyter
We will create a Jupyter kernelspec that brings up a Bitfusion environment by cloning a python3 kernel and modifying it for Bitfusion.
Install kernelspec python3 in Jupyter in ~/tmp.
ipython kernel install --prefix ~/tmp
Rename existing python3 kernel directory to bitfusion-basic (a name chosen to reflect the intent that this kernel bring up a simple Bitfusion use case, a single, full-sized GPU).
cd ~/tmp/share/jupyter/kernels/ mv python3/ bitfusion-basic
Edit kernel.json in the bitfusion-basic directory to add the contents highlighted in the New section below.
Original (python3/kernel.json):
{
"display_name": "Python 3",
"language": "python",
"argv": [
"/usr/bin/python3",
"-m",
"ipykernel_launcher",
"-f",
" {connection_file} "
]
}
New (bitfusion-basic/kernel.json):
{
"display_name": “Bitfusion",
"language": "python",
"argv": [
“bitfusion",
"run",
"-n",
"1",
"--",
"/usr/bin/python3 -m ipykernel_launcher –f {connection_file}"
]
}Install kernelspec bitfusion-basic in Jupyter
jupyter kernelspec install --user tmp/share/jupyter/kernels/bitfusion-basic/
3. Launch Jupyter
Launch Jupyter Lab assuming it has no browser support and assuming we want to specify the port. We’ll use port 8234 as a random example (the default is usually 8888).
jupyter lab --no-browser --port 8234
[I 22:46:39.532 LabApp] JupyterLab extension loaded from /usr/local/lib/python3.6/dist-packages/jupyterlab
[I 22:46:39.532 LabApp] JupyterLab application directory is /usr/local/share/jupyter/lab
[I 22:46:39.534 LabApp] Serving notebooks from local directory: /home/bf_user/tmp/share/jupyter/kernels/bitfusion-basic
[I 22:46:39.534 LabApp] The Jupyter Notebook is running at:
[I 22:46:39.534 LabApp] http://localhost:8234/?token=b2e777a34ff89bf86365fb3518312fa23cfabdcccafb1ddc
[I 22:46:39.534 LabApp] or http://127.0.0.1:8234/?token=b2e777a34ff89bf86365fb3518312fa23cfabdcccafb1ddc
[I 22:46:39.534 LabApp] Use Control-C to stop this server and shut down all kernels (twice to skip confirmation).
[C 22:46:39.537 LabApp]
To access the notebook, open this file in a browser:
file:///home/bf_user/.local/share/jupyter/runtime/nbserver-11343-open.html
Or copy and paste one of these URLs:
http://localhost:8234/?token=b2e777a34ff89bf86365fb3518312fa23cfabdcccafb1ddc
or http://127.0.0.1:8234/?token=b2e777a34ff89bf86365fb3518312fa23cfabdcccafb1ddcThe URL you will paste into a browser later is the second to last line above.
The Mercury Rises
Okay, the pressure is on. The Jupyter server is up and running, now we need a way for our workstation browser to get there.
Perform these next steps, 4, 5, & 6, on the workstation.
4. Set Up Port Forwarding
To launch a browser from the workstation and work connect to Jupyter on the client, you will need to forward a workstation local port (8001 is our example) to the Bitfusion client/Jupyter server port (8234 is our example).
On a Linux workstation:On an MS Windows workstation you can set up the tunnel using putty.
ssh -N -f -L localhost:8001:localhost:8234 bf_user@172.16.31.209
- First, launch putty and set up an SSH session to the client

Figure 2
- Second, set up the port forwarding information: click “Add”, then click “Open”
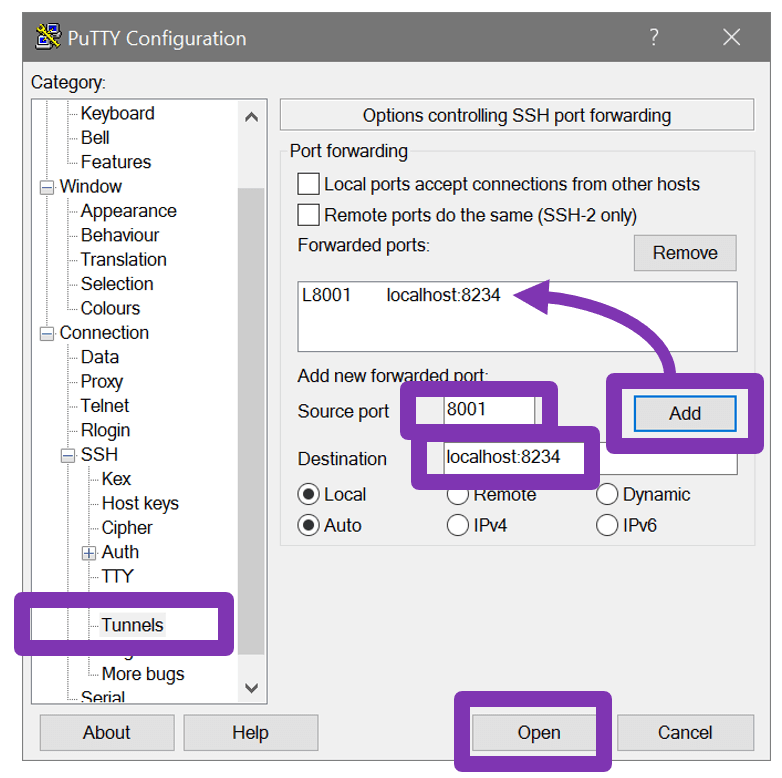
Figure 3
- Third, log in to the client to start the port forwarding over ssh

Figure 4
Leave the SSH login window up so the tunnel does not collapse.
5. Navigate to Jupyter

Launch a browser and go to the URL copied in Step 3, however, substitute the local port you have forwarded. In this example, remove port 8234 and use 8001 in its place.

Figure 5
6. Open the Bitfusion Notebook
Now, you will see the main Jupyter page and you can open the icon for the “Bitfusion” Notebook, shown in Figure 6.

Figure 6
Saturn Rings, and It Tolls for Thee (or He who Pays the Piper, Calls the Neptune)
We’ve finished all the preparations. Now we can run the GPU-accelerated AI/ML apps of our choosing, declare success, and erect an obelisk with our name inscribed on it for all time.
This step is performed on the workstation browser we set up above.
7. Run an Application
You are already in the Bitfusion Notebook, just run your machine learning applications. In the figures below we use the “!” prefix on our commands to escape to the shell environment on the Bitfusion client. We are assuming that datasets, the CUDA toolkit, and TensorFlow benchmarks have been installed there.
In the screenshot below, we run:
!nvidia-smi

Figure 7
Here we start a TensorFlow benchmark run.
!python3 ./benchmarks/scripts/tf_cnn_benchmarks/tf_cnn_benchmarks.py --data_format=NCHW --batch_size=64 --model=resnet50 --variable_update=replicated --local_parameter_device=gpu --nodistortions --num_gpus=2 --num_batches=100 --data_dir=/data --data_name=imagenet

Figure 8
And here is the end of the output from the TensorFlow benchmark run.

Figure 9
Holst it Right There
Since Bitfusion runs as an application, not as part of an operating system or hypervisor, it is easy to integrate into tool chains and environments. Here, we have integrated it as a Jupyter kernel giving notebooks access to remote GPUs. And Bitfusion sharing means dynamic sharing – other clients will immediately be able to access GPUs once our notebook has finished.
In classical antiquity, there were seven wandering bodies amongst the fixed stars in the celestial sphere. We’ve taken a less-aimless, 7-point path in this blog, at last arriving on Jupyter. We may long dwell there, if its gravity is all they claim, so let’s take advantage of its opportunities and the opportunities Bitfusion offers, as well.
And finally – farewell, Pluto, we hardly knew ye.
These other articles on Bitfusion may also be of interest: