
Intelligent Rebuilds in vSAN
Executive Summary
A common requirement of enterprise storage systems is the ability to maintain resiliency and expected levels of performance in the face of hardware faults and other unforeseen conditions. VMware vSAN is the industry leading distributed storage system built right into VMware vSphere, and is designed to offer the highest level of resiliency and performance, with the maximum amount of agility should hardware faults occur, or demands of the environment change. vSAN's awareness of data placement is tightly integrated with routine activities such as host decommissioning, and VMware High Availability (HA). vSAN can also place data intelligently based on site topology designs such as stretched clusters, and user defined fault domains. These, and many more conditions are accounted for in vSAN's ability to intelligently manage performance, efficiency, and availability of data stored on a cluster powered by vSAN. These mechanisms fall under the category of "intelligent rebuilds" and will be discussed in more detail in this document.
Introduction to Intelligent Rebuilds
In traditional three-tier architectures, the resiliency of storage is provided by the use of redundant hardware componentry within a single storage unit - typically in the form of an array enclosure. In traditional storage systems, data is protected by using RAID protection schemes. These schemes are defined on a storage array, and achieved by spreading bytes of data across multiple drives, without regard to the type of data being stored on the LUN. Since virtualized environments might use a single array to provide storage for hundreds of VMs, this limits the flexibility of delivering various levels of protection and performance to individual VMs. Traditional arrays can only assign RAID protection levels per LUN. This presents operational challenges to virtualized environments, where many VMs could be running in a single LUN serving a datastore. If the array uses "wide striping" then it can only protect at one RAID level across the entire array.
By contrast, VMware vSAN is a distributed storage system that uses physical storage devices on each ESXi host in a cluster to contribute to the vSAN storage system. vSAN removes the concept and limitations around defining LUNs, and presents storage as a single, distributed datastore visible to all hosts in the vSphere cluster. VMware vSAN is an object-based storage system integrated into VMware vSphere. Virtual machines that live on vSAN storage are comprised of a number of storage objects. VMDKs, VM home namespace, VM swap areas, snapshot delta disks, and snapshot memory maps are all examples of storage objects in vSAN.
In vSAN, RAID protection levels are defined and controlled in VMware vCenter, using storage policy based management (SPBM). vSAN protects data at an object level, giving you the ability to protect VMs using various levels of protection (RAID-1, RAID-5, RAID-6) and performance on a per VM, or even per VMDK basis. vSAN uses the concept of a RAID tree to ensure protection of objects. A "component" is the "leaf" of an object's RAID tree, and is how redundancy is provided to a given object. When using a RAID-1 protection scheme, a “replica” represents a complete copy of all of the components that make up an object. Figure 1 illustrates the relationship between between objects, components, and replicas.
Components may be split into smaller components depending on environmental conditions, policy settings, and the size of the objects. These disaggregated pieces of an object can be stored separately from the other components that make up an object. vSAN automatically manages the distribution of components across the hosts that constitute a vSAN cluster, and will actively rebuild or resynchronize components when VM objects are not currently adhering to their defined protection policies, severely imbalanced, or in the event of some operational change in the environment.
.png)
Figure 1. The relationship between an object, components, and replicas
Beginning with vSAN 6.6 and continuing through the very latest edition of vSAN, VMware has introduced several improvements designed to offer more intelligent rebuilds, optimizing the return to normal operations and compliance quickly, and automatically.
Purpose of Intelligent Rebuilds
The purpose of any type of component resync or rebuild is to restore or ensure the level of resiliency defined for a given VMDK, VM, or collection of VMs. Several technologies exist in vSAN that assist in the rebuild process and placement of components. The goals of the improvements were to provide the following:
- Achieve better balance of components across vSAN hosts.
- Reduce time of rebuild or resync activities.
- Reduce amount of backend resources (CPU, network, disk I/O) used for storage related activities that are not the direct result of I/O generated by VMs. This includes a rebuild or resync of a component.
vSAN 6.6 included a number of changes related to component rebuilds, such as:
- Intelligent rebuilds using enhanced rebalancing
- Intelligent rebuilds using smart, efficient repairs
- Intelligent rebuilds using partial repairs
- Resumable resyncs
- Maintenance mode decommissioning improvements
Each enhancement will be described in more detail throughout this document, and will include recommendations to ensure the best use of these technologies for your vSAN environment.
RECOMMENDATION: Use supplementary tools to understand vSAN backend activity. VMware vRealize Log Insight paired with the Log Insight content pack for vSAN is a great way to better visualize vSAN activity related activity. vRealize Operations paired with the management pack for vSAN can also be used to better understand trends and workload behavior of your vSAN powered environments.
Intelligent Rebuilds using Enhanced Rebalancing
Rebalancing is the act of redistributing components across the hosts that comprise a vSAN datastore. The need to rebalance can be for a number of different reasons, such as thin provisioned virtual disks being filled up, or introducing an additional host to vSAN, but the objective remains the same: Effective balancing of components across hosts leads to more efficient utilization of resources for both performance and capacity, and minimizes the effort to accommodate planned or unplanned events in a cluster.
Rebalancing efforts fall into two general categories: Proactive rebalancing, and reactive rebalancing.
- Proactive rebalancing occurs when disks are less than 80% full. The opportunity to run a proactive rebalance will only occur when any single disk has consumed 30% more capacity than the disk with the lowest used capacity. vSAN automatically checks for these conditions, and with more recent editions of vSAN, will automatically rebalance the data. For more information, see the blog post: "Should Automatic Rebalancing be Enabled in a vSAN Cluster?"
- Reactive rebalancing occurs when any disk is more than 80% full. This is an automatic process taken by vSAN to ensure the best distribution of components. An imbalance will automatically be detected, and vSAN will automatically invoke efforts to achieve better balance.
Several ongoing enhancements have been made in rebalancing components beginning with vSAN 6.6, and extending to vSAN 7 U1..
- Better decision making in rebalancing efforts. When determining the best strategy for moving components, vSAN 6.6 and later factors in additional information about the components on disks exceeding 80% capacity. vSAN evaluates how much data must be moved out of the identified disk in order to meet the desired balancing objective, and factors this into the component selection process. A more sophisticated selection process of components has been introduced in vSAN 6.6 that prioritizes components so that the components selected for moving will make a more meaningful difference in the rebalancing effort. Previous editions of vSAN relied on a rebalancing primary to publish placement decisions for all components moving out of the source disk and host. This information could grow stale by the time the hosts act on the information. vSAN 6.6 and later make data placement decisions based on a more recent cluster state, courtesy of more up to date information from other hosts. This improved decision making process for component placement can reduce the number of components being moved, and the number of unsuccessful component moves, thereby reducing the overall amount of CPU and network resources used to maintain proper balance.
- Splitting large components during redistribution. vSAN may take an individual large component, and break it into smaller pieces for more optimal distribution. The breaking of components into smaller chunks will only occur during reactive balancing, when a disk has consumed more than 80% of its capacity. During the rebalancing process, if vSAN finds a new disk with sufficient capacity for the component without the need for breaking into multiple components, it will place the component there in its entirety, and not split the component. As seen in Figure 2, if vSAN can't find a new disk without breaking up the component, it will break into two, and retry the rebalancing effort. If it still cannot find a disk after the initial split, it will continue to further divide the component, and retry the previous step. This logic will be followed for up to 8 splits. The splitting of a component will only occur on the component being redistributed. Previous editions of vSAN did not have this ability, and rebalancing efforts could either lead to less than ideal placement, or simply the inability to rebalance due to large component sizes coupled with minimal free space.
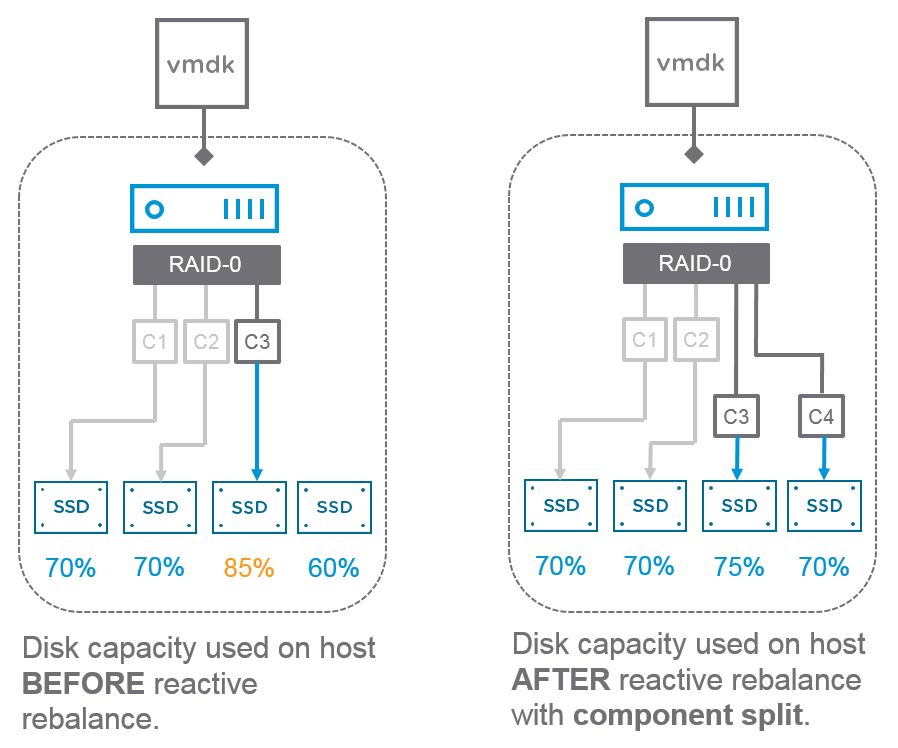
Figure 2. Reactive Rebalance with component split
- Improved visibility of rebalancing. Two improvements have been made to provide better visibility when rebalancing. The rebalance status has been updated to provide more frequent updates with more accurate reports of progress. The improvements make it much easier to report the number of bytes being moved out for rebalancing, and new resync graphs have been introduced in the performance service so that resync traffic can be monitored in greater detail. As shown in Figure 3, this can be found at the disk group level in the host-related vSAN metrics.
.png)
Figure 3. Visibility of resync performance per disk group.
vSAN provides a number of rebalancing "states" in the UI, as shown in Figure 4.
- Proactive rebalance is needed. This state is triggered after vSAN determines proactive rebalancing is needed following a 30 minute monitoring period.
- Proactive rebalance is in progress. This state is shown when a proactive rebalance is in progress.
- Proactive rebalance failed. This is when the object manager couldn’t find any components that could be moved due to policy restrictions, lack of resources, etc.
- Reactive rebalance task is in progress. This state simply notifies the user that a reactive rebalance is in progress.
.png)
Figure 4. An example of a rebalancing state as seen in the UI
Note that rebalancing of components aims to achieve a relatively even distribution of components across the storage devices contributing to storage in a vSAN datastore. This is designed both to optimize performance, by distributing across the most devices, and to minimize the size of any given fault domain. It will not rebalance data in such a way that it will compromise a given protection policy. For instance, vSAN will never place the other leaf component of an object with a RAID-1 mirror on the same drive for the sake of balance.
- Adaptive Resync. The traffic generated by any resyncing or rebalancing of components occurs on the network designated for vSAN traffic. As described in this document, a number of techniques in vSAN exist to reduce the effective amount of data traversing the vSAN network during rebalancing or repair processes. In some cases, such as permanent host decommissioning during heavy workload, there may be times of resource contention between the VM's demand on the storage and network, and the need of resynchronization activities. This is where vSAN's Adaptive Resync mechanism aids to manage the flow of I/O during times of contention.
Intelligent Rebuilds using Smart, Efficient Repairs
vSAN is designed to automatically detect when an object is no longer compliant with an assigned protection policy, and after a designated amount of time will rebuild the relevant components elsewhere to regain compliance. A common scenario would be if a host in a vSAN cluster is unexpectedly offline. These component rebuilds are invoked when the compliance failure has occurred for 60 minutes or longer, and no explicit error codes were sensed. A rebuild would occur on the entire set of components deemed absent, in order to regain compliance with the assigned protection policies. Note that in scenarios where vSAN detects an object no longer compliant with an assigned policy as a result of a device failure and resulting error code sensed, a rebuild will begin immediately.
vSAN uses a few techniques to restore the compliance of protection policies to objects, while minimizing resources used for a rebuild.
- Additional repair method. In early editions of vSAN, a rebuild was based on a strict component rebuild process invoked after components were marked as absent for 60 minutes or longer. Once this rebuild process started, it would continue until completion, even if the affected host would come back online shortly after the 60 minute timeout window. This process would also resync the slightly outdated components on the recently restored host while rebuilding the entire component elsewhere, but could only use the rebuilt component upon completion. vSAN now uses a repair method that also allows vSAN to take advantage of the resyncronized component on the host, should vSAN deem this the more efficient method to use.
- New logic to determine best method to use. When a host or device comes back online after a 60 minute window, vSAN will look at the amount of data remaining for a component rebuild to complete, versus how long it would take to repair or resync the outdated component, and choose the method that will complete with the least amount of effort, cancelling the other rebuild operation.
These techniques reduce the amount of data that needs to be rebuilt, and the time that it takes for objects to regain compliance of their protection policies. Reducing the need for full component rebuilds can also free up space that is not needed immediately for the rebuild process. The added repair method, and the new logic in determining the best method for repair is extremely beneficial for hosts that were in their maintenance window just slightly longer than the 1 hour timeout period, as well as for hosts that hold a large amount of consumed capacity for objects.
Intelligent Rebuilds using Partial Repairs
When objects are no longer in compliance with their designated protection policy, vSAN manages the repair and rebuilding process in the most efficient way possible. It takes into account a number of factors, including component size, distribution of objects, storage policy conditions, and capacity remaining on devices. When the repair or rebuild process begins after components have been absent for longer than 60 minutes, it will attempt to make the smartest decisions on the order and placement of the components it is rebuilding.
In some data resynchronization circumstances, vSAN uses the concept of "partial repairs." In older editions of vSAN, a repair would only be able to successfully execute a repair effort if there were enough resources to repair all of the degraded, or absent components in entirety. Partial repairs will take a more opportunistic approach to healing by repairing as many degraded, or absent components as possible, even if there are insufficient resources to ensure full compliance. The effective result is that an object might remain non-compliant after a partial repair, but will still gain increased availability from those components that are able to be repaired.
Any remaining components that are not repaired to meet their full level of compliance according to the SPBM policy will be repaired as soon as enough capacity resources become available.
An example of a partial repair process can demonstrated in a scenario of a 6 node vSAN cluster, with a VM configured for an FTT set to 2. As shown in Figure 6, In the event that two host failures occur, the VM would still be available, but the effective FTT would be 0, as there would only be one replica remaining. With the new partial repair process, vSAN will initiate and complete a repair of the objects if enough resources are available to increase the effective FTT level as a result of the repair. While the objects might remain non-compliant from the desired SPBM policy of FTT=2, the partial repair process will have increased the effective availability to FTT=1. vSAN will eventually complete the repair to make the object fully compliant when resources become available. Increased resource availability could come from adding hosts, adding capacity, deleting unused VMs, or reducing protection levels of other VMs.


Figure 6. An example of a partial repair process in a standard cluster.
Partial repairs work in both standard and stretched cluster environments. An example of a partial repair process in a stretched cluster environment can be demonstrated in a scenario of an 8 node stretched cluster, with a VM configured for PFTT=1 (remote protection level), and SFTT=1 (Local protection level). As shown in Figure 7, in the event that a site failure occurs, and the remaining site has an host failure, the VM would still be available in the remaining site. The effective PFTT would be 0, and SFTT would be 0, as it would be the last replica remaining. The new partial repair process will initiate and complete a “best effort” repair in the surviving site. While the object might remain non-compliant across sites (PFTT), the partial repair process will have increased the effective local protection level to a locally compliant level of SFTT=1. vSAN will eventually complete the repair to make the object fully compliant across sites when resources become available.





Figure 7. An example of a partial repair in a stretched cluster.
In both examples, vSAN will give priority to the partial repair of data components over witness components.
Intelligent Rebuild using Resumable Resync
Resynchronization efforts play an important role in the ability to ensure compliance of protection policies for objects in vSAN.
vSAN has improved the resync action so that it is more resilient, and efficient. In prior editions of vSAN, an interrupted resync would need to start the resync process from the beginning. An example of a resync interruption includes an absent host coming back online, running the resync process, followed by a brief network interruption. Changing an SPBM policy on an object while the host containing the owner object is offline is another scenario in which resyncs would need to start from the beginning. As shown in Figure 8, vSAN is now able to transparently resume a resync operation where it left off following an interruption, avoiding the need to reprocess already resynchronized data.

Figure 8. Resumable resyncs.
Resumable resyncs are achieved by accepting writes and tracking the changes on the component that remains available. vSAN identifies the last write that the component has when the host containing the component goes offline, while keeping the previous effort of resynchronized data. The updated writes that are committed to the component still available is tracked separately from the original resync tracking. Once the component comes back from being temporarily unavailable, the tracked changes on the active components are merged into the components temporarily offline so that it can resume the resynchronization process. As data is resynchronized, vSAN will incrementally update its understanding of what data has been committed so that in the event of another incremental outage, it does not have to resync data already synchronized.
Intelligent Restart Improvements
Intelligent vSAN Host Reboot
Host reboots are a necessary task in todays data center. The longer a host takes to restart, the greater the amount of new writes will need to be sychronized to a vSAN host. VMware looked for opportunities to optimize the time it takes for a vSAN host to restart during a planned maintenance event. The result of these improvements include dramatically improved restart times for vSAN 7 U1 hosts during planned host restarts: comparable to restarts of vSphere hosts not running vSAN. These optimizations take advantage of the known state of the in-memory tables used to track changed data, quiescing the data and commit it to disk prior to the host restart, and read the data to reconstruct the tables.

vSphere QuickBoot and vLCM
Quick Boot is a feature of VMware vSphere that speeds up the upgrade process of an ESXi server. A regular reboot involves a full power cycle that requires firmware and device initialization. Quick Boot optimizes the reboot path to avoid this, saving considerable time from the upgrade process.
For cases where firmware patches need to be applied, vSphere Life Cycle Manager (vLCM) allows for coordinating multiple updates of firmware/bios and drivers into a single reboot cycle reducing the time spent with a host in maintenance mode.
More information can be found at the vLCM Technote.
Intelligent Rebuilds with Maintenance Mode Decommissioning
Maintenance mode operations are an important aspect of typical data center operations. The Enter Maintenance Mode (EMM) workflow is integrated into vSAN operations, and gives the following options:
- Evacuate all data
- Ensure data accessibility
- No data evacuation
"Ensure data accessibility" simply allows the VMs to remain accessible, yet potentially in a degraded state of redundancy. This is typical for most quick maintenance mode operations, and no data will be moved. “No data evacuation” is most often related to a full cluster shutdown, and just as the name implies, no data will be moved. “Evacuate all data” will rebuild the components onto other hosts to maintain the desired protection policies assigned to the VMs. This last option is commonly used for activities such as hardware maintenance, decommissioning, or possibly ondisk format changes introduced in vSAN. These modes apply not only to host entering maintenance mode, but disk, and diskgroup EMM activities.
vSAN optimizes the process of evacuating data to other hosts has been optimized to reduce the amount of overhead and data migration during an EMM operation. This translates to a quicker time to complete the EMM operation.
The object manager will no longer attempt to fix compliance at an object level across the cluster during a full evacuation, but rather, only strive to move all components from the node entering maintenance mode onto other nodes in the cluster. vSAN will preserve a current object effective FTT level during this operation. If an object had been assigned FTT=2 in its policy, but had an effective availability of FTT=1, it will preserve this FTT=1 status for the EMM effort. This reduces the amount of time required, minimizes data movement across the cluster, and also increases the chance for a successful maintenance mode operation. Previous editions would require all affected objects to be fully compliant, including the repair of other unrelated components before completing the EMM process.
RECOMMENDATION: Choose the correct maintenance mode operation for your intention. Typical vSphere patches are often applied quickly, and the most significant downtime might just be the reboot process of the host. If you’re VMs can run with less resiliency for a brief amount of time, then the “Ensure Accessibility” maintenance mode option is an extremely efficient way to go. Other maintenance activities on a server expected to take a longer time period might be more suitable for the “full evacuate” option.
vSAN 7 U1 Improvements
In vSAN 7 U1, significant improvements to resynchronization were made when using "Maintain Availability" for entering maintenance mode. The missing writes will be redirected to other nodes in the cluster, increasing not only data durability but improving performance for resynchronization of stale components.
If RAID-5/6 is used in a condition where a host exits out of maintenance mode, vSAN will strive to use the delta components as the source of the resync. This is a substantially faster process than a rebuild of the stripe, as it eliminates the need to reconstruct the resyncing blocks for the base component from other components. If RAID-1, it will strive to use the delta components as the source for the resync, but can optionally use the full replica for resyncing if the delta is not active.

vSAN 7 U2 extended the use of durability components from not only planned maintenance events (described above), but unplanned events such as host or disk failures.
Activities that benefit from improved Intelligent Rebuilds
Nearly all back-end management activities by vSAN benefit from the improvements described in this document. The activities listed below highlight where, and how the individual improvements will provide benefit. The benefits of the enhancements are not limited to these examples, but serve as an way to better understand how the improvements apply to real world use cases.
Sustained Fault domain failure
Sustained fault domain failures can be the result of a single fault domain such as a host, device, disk group, or defined fault domain. A failed host for instance will be able to take advantage of a number of enhancements to intelligent rebuilds. Partial repairs will attempt to improve the FTT level even if it cannot satisfy the entire policy, while resumable resyncs will allow for a quicker time to completion in the event of intermittent outages during a rebuild process. Improved visibility of resync activity in the UI is also an important part of the intelligent rebuild process.
Fault domain restored prior to rebuild completing
A vSAN cluster that has a host go offline for a temporary amount of time (but over 60 minutes) will also benefit from a number of enhancements to intelligent rebuilds. Smart efficient repairs provides the primary benefit in determining the best strategy for rebuild once the host comes back online. Improved visibility of resync activity in the UI is also an important part of the intelligent rebuild process.
Decommissioning of a host or diskgroup
Decommissioning a host in a vSphere cluster is a common practice in the data center. Whether it be for permanent removal of a host from a cluster, or temporarily for maintenance activities. In the event of entering maintenance mode in which full evacuation of data is desired, vSAN’s intelligent rebuilds take advantage of enhancements in maintenance mode decommissioning to speed of the process of entering maintenance mode. Improved visibility of resync activity in the UI provides additional benefit to the user. These enhancements are also applicable to disk and diskgroup decommissioning that can occur as a result of disk format changes, or other disk evacuation activities.
RECOMMENDATION: Use a single host maintenance mode for rolling cluster updates. In traditional three-tier architectures, persistent storage was housed separately, and if a cluster had sufficient compute resources to tolerate more than one host offline at any given time, this could speed up the remediation process for host updates. In vSAN, a single host maintenance mode rolling update is a better strategy as it will reduce the amount component resyncing to ensure proper compliance.
Disks nearing capacity
As storage devices in a vSAN datastore fill up, the improvements made in vSAN 6.6 show up in many areas. When the automated, reactive rebalancing is initiated, the enhanced rebalancing will allow for components to be split, offering better placement decisions during the rebalancing process. Improved visibility of resync activity in the UI provides additional benefit to the user.
RECOMMENDATION: Use performance graphs to understand backend activity. vSAN 6.6 significantly reduces this burden of backend traffic, but in order to understand the actual burden of resync, monitor resync activity using the graphs courtesy of the Performance Service in vSAN. The new resync graphs can be found by highlighting a host, clicking on Monitor > Performance > “vSAN – Disk Group” and looking at all resync related graphs.
Disks imbalanced across cluster
vSAN powered clusters that have sufficient capacity, but are identified by vSAN as imbalanced, will provide the option of a user initiated proactive rebalance, and will benefit from improved visibility of the resync activity during this rebalance effort. This imbalance could come from thin provisioned virtual disks having a sudden amount of growth, or perhaps from a host placed into maintenance mode where all of the data was evacuated, but has recently been brought back online. vSAN will notice this imbalance, and suggest a rebalance if it is advised. The performance graphs in the vSAN performance UI will illustrate the backend activity occurring during the resync, and the status indicators in the Health UI will provide more meaningful state of the rebalance activity.
Impending failure of a device
Not specifically discussed in this document, Degraded Device Handling (DDH) will also benefit from the enhancements made to intelligent rebuilds. In situations where there is only one valid copy of data left on the cluster, it will be evacuated and the component placements will be in accordance to the enhanced rebalancing mechanisms in vSAN 6.6. Improved visibility of resync activity in the UI provides additional benefit to the user.
Upgrade vSAN for faster Rebuilds
All of the individual enhancements to the task of intelligent rebuilds deliver specific performance and efficiency improvements to vSAN. These improvements, while described individually in this document, will have dramatic improvements in efficiency when vSAN uses them collectively against the demands of real workloads, and environmental demands of a production environment.
It should be noted that beyond these specific features, a number of general performance improvements related to network throughput, disk group write performance, tuned drivers and features like compression-only introduced in 7 U1 can also help significantly improve rebuild performance. For best rebuild performance, upgrade to the newest version of vSAN. For more information on the specific improvements related to performance in vSAN 7 U1, see the following blog.

About the Author
This content in this document was assembled using content from various resources from vSAN Engineering and vSAN Product Management.
Pete Koehler is part of the vSAN Technical Marketing Team in the Cloud Platform Business Unit at VMware, Inc. He specializes in enterprise architectures, data center analytics, software-defined storage, and hyperconverged Infrastructures. Pete provides more insight to challenges of the data center at vmpete.com, and can also be found on twitter at @vmpete.