
Preliminary Performance of Project Radium
Introduction
VMware vSphere Bitfusion is a product that virtualizes certain GPU hardware. Project Radium is a more generalized approach to virtualize a larger body of hardware accelerators. This paper takes a very early or preliminary look at the performance Project Radium is achieving. We are encouraged by what we are seeing. The development work, so far, has concentrated on functionality. The focus is now shifting to performance and optimization. The Project Radium fundamentals are different than Bitfusion's and required a completely new implementation. The benchmarks we've run so far indicate that Radium's performance has a solid foundation, even before optimization work begins.
This paper examines performance by running Bitfusion and Project Radium head-to-head. Project Radium is presented here as a tech preview.
This paper may contain product features or functionality that are currently under development. This overview of new technology represents no commitment from VMware to deliver these features in any generally available product. Features are subject to change, and must not be included in contracts, purchase orders, or sales agreements of any kind. Technical feasibility and market demand will affect final delivery. Pricing and packaging for any new features/functionality/technology discussed or presented, have not been determined.
The testing for this paper consists of running the well-known TensorFlow CNN image recognition machine learning (ML) benchmark. The benchmark prints results in images per second processed. We set a baseline with the benchmark running on a VM with local GPUs (using DirectPathIO for GPU passthrough). This baseline is compared against the results from three other set-ups that all provide remote, virtualized GPUs: 1. Bitfusion using TCP/IP, 2. Bitfusion using PVRDMA (RoCE), and 3. Project Radium on TCP/IP
Let's look in more detail at Project Radium, Bitfusion, the benchmark, and the test environment.
Project Radium
Project Radium virtualizes more devices than Bitfusion and does so in a more general fashion. Bitfusion (available since 2019) virtualizes NVIDIA GPUs. Project Radium virtualizes any accelerator from any vendor — and is a new, from-the-ground-up implementation based on new principles. Project Radium preserves the features of Bitfusion, adds new ones, and takes a simpler, more general approach to virtualization. In fact, engineers refer to the approach as GPR, generalized process remoting; naming its potential to enable remote virtualization of processes in general, going beyond just accelerator virtualization.
And this approach has begun to demonstrate its possibility of doing remote virtualization with better performance.
Project Radium Preview
For more detailed descriptions of Project Radium see:
You can also look at Project Radium from the CLI at this preview demo.
Machine Learning, Virtualization, and Bitfusion
Virtualization of hardware accelerators is primarily driven by machine learning (ML) and artificial intelligence (AI) applications. These driving applications require acceleration hardware, otherwise they run too slowly to be useful. But if this hardware (GPUs, mostly, today) can't be shared — shared easily — among multiple users, machines, and applications, it tends to sit idle around 85% of the time. Bitfusion and Project Radium both allow very dynamic sharing and partitioning of GPUs or other accelerators.
They:
- Allocate resources on the fly, allow an application instance to consume them, and then free them for other runs.
- Require no re-configuration of resources, nor that VMs be spun up or down.
- Allow allocation of single, multiple, and partial devices.
- Allocate remote acceleration resources (over the network). Applications run on hosts without accelerator devices, but consume acceleration services on remote machines.
- Run applications as-is, without refactoring or re-compilation.
Motivation, Benchmark, Equipment, and Machines
The primary motivation for Bitfusion and Project Radium is to increase the accelerator utilization. In monetary terms, if the GPU you need costs $10,000, you could buy one of them to share among four users instead of buying four of them.
- But… you don't want this sharing to be cumbersome.
- And… you don't want this sharing to make the "accelerator" run slowly.
An absolutely perfect virtualization solution would make sharing invisible. An absolutely perfect virtualization solution would be as fast as exclusive ownership of the physical hardware. In this curmudgeonly imperfect, real world, however, we accept a certain amount of bother and a certain amount of performance overhead in exchange for all the benefits of sharing. And then we work to minimize that bother and overhead.
Project Radium virtualizes GPUs and other accelerators over a TCP/IP network (RoCE coming). This paper will see how well we are currently (preliminarily) handling the network latency and how well we are preserving the accelerator performance. Let's examine the benchmark, the two-Bitfusion/one-Radium set-ups, and the physical equipment.
TensorFlow CNN benchmark
The good people behind TensorFlow, the ML framework, have created a Convolutional Neural Network (CNN) training benchmark that we have used for many years as part of our performance and correctness testing approach for Bitfusion. The benchmark has parameters for the model, the batch size and many other characteristics of machine learning that data scientists and developers play with. The benchmark trains a model to recognize images (is this an image of a shirt, or trousers, or a shoe?). It reports the number of images it is processing per second as it trains the model. Higher is better than lower.
In this paper we use a few configurations of this benchmark and establish a baseline by running these configurations on a VM with local, dedicated GPUs (using DirectPathIO to pass the GPUs through). Next, we run the same configurations under Project Radium and Bitfusion with two types of networking. Results will be given in raw images per second and as normalized values — local GPU performance is set to 1.0 and the others as a value relative to that.
We will test a few combinations of:
- Models: Alexnet, Resnet20, Resnet32, Resnet56, and Resnet110
- Batch sizes: 32, 128, and 512
Physical Equipment
We used two physical hosts for the tests on NVIDIA Tesla V100 GPUs:
- Dell R6740, 2 x 8260 processor, 96 cores, 384 GB memory
- No installed GPUs
- Runs the Bitfusion and Project Radium benchmarks using virtualized GPUs from the other host.
- Dell PowerEdge C4140, 2 x 8260 processors, 96 cores, 384 GB memory
- 2 NVIDIA Tesla V100 GPUs
- Runs the bare metal benchmarks
- Provides the remote, virtualized GPUs for Bitfusion and Project Radium benchmarks
When a VM was used to either run a benchmark, Bitfusion, or Project Radium, that VM was given exclusive and sole use of its physical host.
The hosts had a TCP/IP connection and a PVRDMA connection:
- 10 Gbps TCP/IP network
- MTU 1500
- 80 microsecond average latency
- Average measured bandwidth of 4.75 Gbps
- 100 Gbps PVRDMA (RoCE) network
- MTU 4096
- 1.66 microsecond average latency
- Average measured bandwidth 96 Gbps
- Mellanox Technologies MT27700 Family (ConnectX-4) and MT27800 Family (ConnectX-5) networking cards
- Mellanox MSN2700-CS2F 100GbE switch
Roughly comparable hosts and networking were used for the tests on the AMD MI100 GPU — but a direct comparison of the two test sets is not appropriate with this set-up.
We tested a few combinations of:
- Network: TCP/IP and PVRDMA
- GPU allocation: 1 GPU, 2 GPUs
Results
The results from the testing show Project Radium comparing favorably with Bitfusion, often outperforming Bitfusion. In several tests, Project Radium approaches or matches the baseline, local GPU performance.
These tests are capturing the images/sec data after the application and Bitfusion/Radium have initiated, warmed up, and reached a steady state, so as not to conflate three different stages of a run and not to conflate three different targets for optimization.
Most tests set up a few or several adversarial conditions for Bitfusion. Perhaps the most fundamental challenge of remote virtualization is the network latency. Adverse conditions were set up to help us judge Project Radium's new attack on that challenge.
Each subsection below has a table and a chart for its set of tests, plus a brief description and discussion of that test.
Tesla V100 16 GB GPU, Many Models, Small Batch Size, CIFAR10 Dataset
This test runs training with the CIFAR10 dataset on several ML models with a batch size of 32. Tests were run with one and two NVIDIA Tesla V100 GPUs with 16 GB of memory. The test self-reports performance in images per second and we calculate ratios of baseline performance against Bitfusion and Project Radium. Bitfusion is run with both TCP/IP networking and PVRDMA. The baseline is from a run on a VM with local GPUs.
Adversarial conditions include:
- TCP/IP
- Standard MTU: 1500 (Bitfusion recommends 4096 or higher)
- Network latency exceeds recommended 50 microseconds
- Available Bandwidth is less than half of expected 10 Gbps
- Dataset, batch size, and models do not make heavy demands on the GPU — the pipeline between the Bitfusion Client and Bitfusion server frequently drains, costing more latency payments
- Multiple GPUs — Bitfusion has higher overhead when the number of GPUs increases
Note: The PVRDMA connection follows Bitfusion recommendations, removing all network adversarial condition in its tests.
| Case | Local GPU | Radium | Bf PVRDMA | Bf | Radium ratio | Bf PVRDMA ratio | Bf ratio |
|---|---|---|---|---|---|---|---|
| alexnet 1 gpu | 9725.84 | 4110.33 | 6660.9 | 2841.2 | 0.42261954 | 0.68486629 | 0.29212901 |
| alexnet 2 gpu | 10446.99 | 5932.79 | 7353.01 | 2596.49 | 0.56789468 | 0.70384005 | 0.24853953 |
| resnet32_v2 1 gpu | 3288.34 | 3072.56 | 1922.32 | 858.07 | 0.93438026 | 0.58458675 | 0.26094321 |
| resnet32_v2 2 gpu | 3121.87 | 3111.79 | 1330.38 | 471.51 | 0.99677117 | 0.42614843 | 0.15103448 |
| resnet56 1 gpu | 1987.43 | 1921.85 | 1109.36 | 511.99 | 0.96700261 | 0.55818821 | 0.2576141 |
| resnet56 2 gpu | 1681.06 | 1750.75 | 812.23 | 275.49 | 1.04145599 | 0.48316538 | 0.16387874 |

These tests were chosen as stress tests against Bitfusion. We have long recommended large batch sizes as a way to keep the pipeline full (and performance high) between the Bitfusion clients and servers. For similar reasons, Bitfusion has typically performed better with larger models and dataset elements. We also recommend low-latency, high-bandwidth networking. Even under the adversarial conditions, we are seeing here that Project Radium, in two-thirds of the tests, exceeds the performance of Bitfusion even with favorable PRDMA networking. In those same four tests, Radium even approaches baseline performance. The two tests where Project Radium falls behind Bitfusion use the Alexnet model, an older model less efficient with the GPU and less conducive to pipelining. Even with Alexnet, however, Radium outperforms Bitfusion when both use TCP/IP networking.
Another encouraging trend is that Project Radium performs closer to the local GPU baseline when allocating multiple GPUs than when allocating a single GPU. Bitfusion loses efficiency as the number of GPUs increases.
We note that in one case, Project Radium exceeded the baseline performance. While we expect that Project Radium may occasionally achieve this feat by virtue of having more processors/cores available (the client and the GPU server could operate on the process simultaneously), in this instance, we attribute the 104% performance to the noise of testing (the performance varies a little bit each time you run it).
Tesla V100 16 GB GPU, Many Models, Large Batch Size, CIFAR10 Dataset
This test runs training with the CIFAR10 dataset on several ML models with a large batch size of 512. Tests were run with one and two NVIDIA Tesla V100 GPUs with 16 GB of memory. The test self-reports performance in images per second and we calculate ratios of baseline performance against Bitfusion and Project Radium. Bitfusion is run with both TCP/IP networking and PVRDMA. The baseline is from a run on a VM with local GPUs.
Adversarial conditions are the same as above except for the batch size, which is now favorable:
- TCP/IP
- Standard MTU: 1500 (Bitfusion recommends 4096 or higher)
- Network latency exceeds recommended 50 microseconds
- Available Bandwidth is less than half of expected 10 Gbps
- Dataset and models do not make heavy demands on the GPU — the pipeline between the Bitfusion Client and Bitfusion server frequently drains, costing more latency payments
- Multiple GPUs — Bitfusion has higher overhead when the number of GPUs increases
Note: The PVRDMA connection follows Bitfusion recommendations, removing all network adversarial condition in its tests.
| Case | Local GPU | Radium | Bf PVRDMA | Bf | Radium ratio | Bf PVRDMA ratio | Bf ratio |
|---|---|---|---|---|---|---|---|
| alexnet 1 gpu | 12226.47 | 10284.22 | 10876.69 | 10956.38 | 0.84114385 | 0.88960182 | 0.89611965 |
| alexnet 2 gpu | 12077.98 | 10618.11 | 10568.87 | 10406.75 | 0.87912962 | 0.87505278 | 0.86163001 |
| resnet32_v2 1 gpu | 11408.37 | 9733.82 | 9411.54 | 7765.26 | 0.85321742 | 0.82496798 | 0.68066341 |
| resnet32_v2 2 gpu | 11856.51 | 9913.9 | 10566.4 | 6159.37 | 0.83615668 | 0.89118973 | 0.51949267 |
| resnet56 1 gpu | 6679.58 | 6655.46 | 5820.2 | 5121.02 | 0.99638899 | 0.87134221 | 0.76666796 |
| resnet56 2 gpu | 11637.73 | 10045.25 | 8747.35 | 4138.98 | 0.86316232 | 0.75163713 | 0.35565183 |
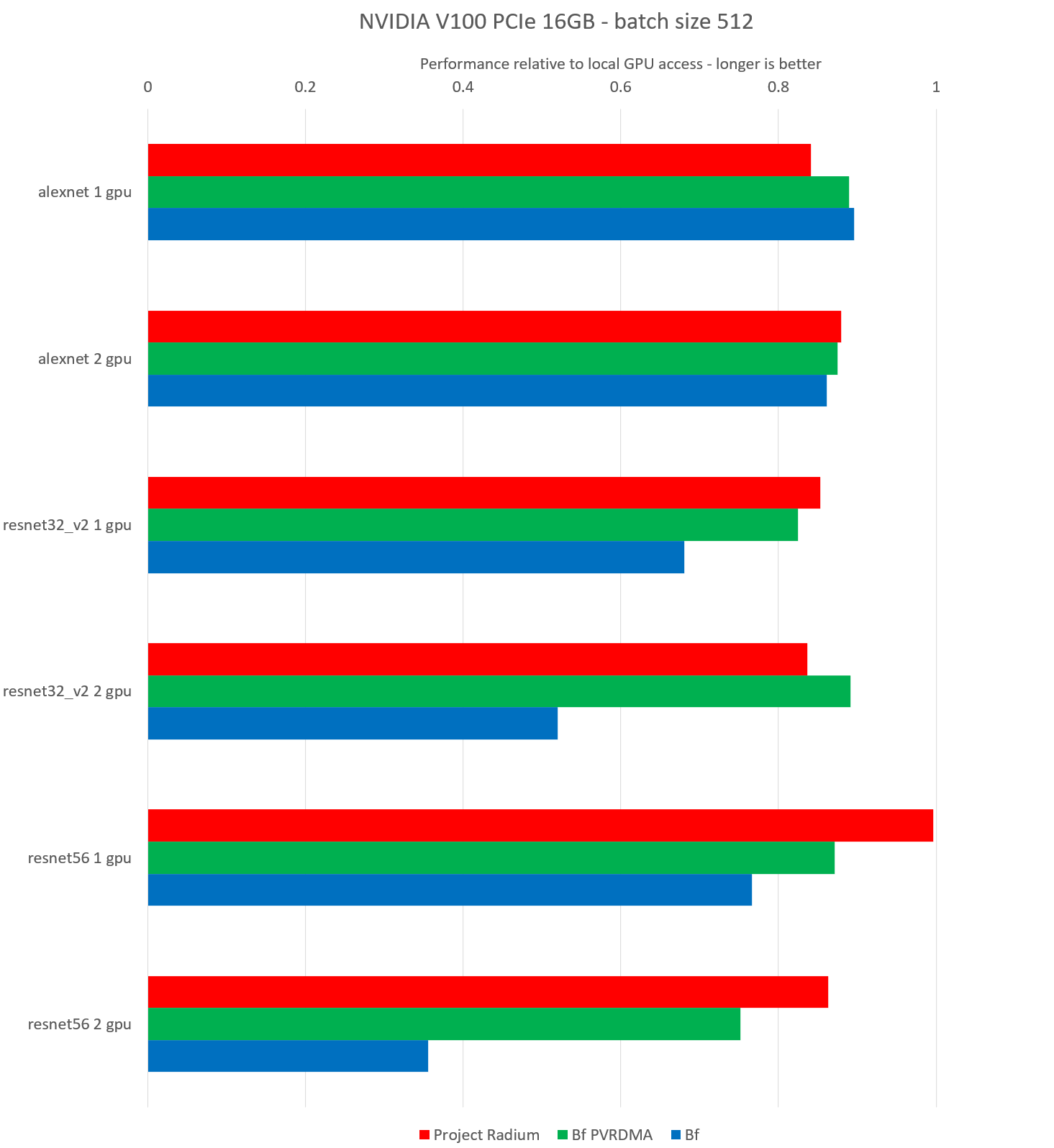
These tests differ from the previous tests by only one variable: they use a large batch size instead of small, following standard Bitfusion recommendations. In the case of Alexnet, we see that the batch size recommendation was effective for all three Bitfusion set-ups.
Project Radium approaches or exceeds parity against Bitfusion in all cases. Project Radium is never below 84% of baseline performance.
Unlike the small batch size tests, here we see higher overhead for Project Radium with multiple GPUs. That is something for us to examine more closely going forward.
AMD MI100 32 GB GPU,
Project Radium has the ability to virtualize GPUs from different vendors. This series examines the AMD MI100 with 32 GB of memory. We can only compare it to the baseline; we cannot compare it to Bitfusion as Bitfusion only virtualizes the CUDA-capable GPUs from NVIDIA. We examine multiple batch sizes. We only run with a single GPU.
This test runs training with the CIFAR10 dataset on several ML models. The test self-reports performance in images per second and we calculate ratios of baseline performance against Project Radium. The baseline is from a run on a VM with a local GPU.
| Case | Local GPU | Radium | Radium ratio |
|---|---|---|---|
| resnet20_v2 1 gpu batch size 32 | 3881.45 | 1959.64 | 0.50487318 |
| resnet56_v2 1 gpu batch size 32 | 1671.95 | 1452.83 | 0.86894345 |
| resnet110_v2 1 gpu batch size 32 | 946.5 | 853.05 | 0.90126783 |
| resnet20_v2 1 gpu batch size 128 | 8928.03 | 6109.81 | 0.68434022 |
| resnet56_v2 1 gpu batch size 128 | 4388.67 | 3853.01 | 0.8779448 |
| resnet110_v2 1 gpu batch size 128 | 2526.63 | 2312.75 | 0.9153497 |
| resnet20_v2 1 gpu batch size 512 | 11237.6 | 8448.72 | 0.75182601 |
| resnet56_v2 1 gpu batch size 512 | 6443.03 | 6369.45 | 0.98857991 |
| resnet110_v2 1 gpu batch size 512 | 3342.09 | 3314.55 | 0.99175965 |

These tests are our first benchmarks on AMD GPUs. Our first observation is that our goal to work with multiple GPU vendors has been achieved. Bitfusion works by interposition with the CUDA API. Project Radium works by intercepting system and memory events, a different underlying approach that nevertheless delivers a user experience mostly the same as Bitfusion.
Next, we observe that larger models and larger batch sizes experience lower overhead, higher performance than smaller models and batch sizes, consistent with the reasons behind the current Bitfusion recommendations. Lastly, we are encouraged that two runs are within 98% of local GPU baseline performance, four are within 90%, and six are within 85%.
Conclusion
We are trying to achieve several goals with Project Radium, but the two we are examining in this paper are:
- Similar or better performance than Bitfusion
- Immediate support for other accelerators
Performance: We believed the new approach to remoting and accelerator virtualization, in and of itself, should be good for performance. We ran benchmarks under conditions adversarial to Bitfusion to highlight the differences between the old and the new approach. These preliminary tests suggest the new approach is performing well. Many of the tests are already within a few percentage points of local GPU performance.
The tests above measure performance after initialization and after warm-up. Also, while the tests well represent typical workloads, they constitute, nonetheless, a small sample. There are many optimizations to make beyond pushing the above performances ever closer to local GPU numbers. This work will soon begin using both benchmarks (as the above) as well as detailed tracing.
Our major conclusion is that we have demonstrated the feasibility of good performance with this approach.
More Accelerators: We have demonstrated the generality of the Project Radium. The new technology virtualizes remote GPUs from both NVIDIA and AMD. Testing of additional vendors will follow. The approach does not rely on hardware or API specifics. As with Bitfusion, Project Radium runs applications using remote accelerators without refactoring or recompilation.