
vSAN 6.7 U3 Proof of Concept Guide
vSAN 6.7u3Introduction
Decision-making choices for vSAN architecture.
Before You Start
Plan on testing a reasonable hardware configuration that resembles what you plan to use in production. Refer to the VMware vSAN Design and Sizing Guide for information on supported hardware configurations and considerations when deploying vSAN. Be sure the hardware you plan to use is listed on the VMware Compatibility Guide (VCG). If you're using a ReadyNode or VxRail, the hardware is guaranteed to be compatible with vSAN -however, BIOS updates, and firmware and device driver versions should be checked to make sure these aspects are updated according to the VCG. For vSAN software layer specifically, pay particular attention to the following areas of the VCG:
BIOS: Choose "Systems / Servers" from "What are you looking for" : http://www.vmware.com/resources/compatibility/search.php
Network cards: Choose "IO Devices" from "What are you looking for" : http://www.vmware.com/resources/compatibility/search.php?deviceCategory=io and select "Network" from "I/O Device Type" field.
vSAN Storage I/O controllers: Choose "vSAN" from "What are you looking for" : http://www.vmware.com/resources/compatibility/search.php?deviceCategory=vsan. Scroll past the inputs in "Step 2" and look for the link to "Build Your Own based on Certified Components" in "Step 3". Click that link. (The link executes javascript and cannot be linked to directly.) From the Build Your Own page, make sure "IO Controller" is selected in the "Search For:" field.
vSAN SSDs: Choose "vSAN" from "What are you looking for" : http://www.vmware.com/resources/compatibility/search.php?deviceCategory=vsan. Scroll past the inputs in "Step 2" and look for the link to "Build Your Own based on Certified Components". Click that link. From the Build Your Own page, select "SSD" from the "Search For:" field.
vSAN HDDs (Hybrid only) : Choose "vSAN" from "What are you looking for" : http://www.vmware.com/resources/compatibility/search.php?deviceCategory=vsan. Scroll past the inputs in "Step 2" and look for the link to "Build Your Own based on Certified Components". Click that link. From the Build Your Own page, select "HDD" from the "Search For:" field.
The following commands may come in handy to help identify firmware and drivers in ESXi and compare against the VCG:
- To list VID DID SVID SSID of a storage controller or network adapter:
vmkchdev -l | egrep 'vmnic|vmhba'
- To show which NIC driver is loaded:
esxcli network nic list
- To show which storage controller driver is loaded:
esxcli storage core adapter list
- To display a driver version information:
vmkload_mod -s <driver-name> | grep -i version
All-Flash or Hybrid
There are a number of additional considerations if you plan to deploy an all-flash vSAN solution:
- All-flash is available in vSAN since version 6.0.
- It requires a 10Gb Ethernet network for the vSAN traffic; it is not supported with 1Gb NICs.
- The maximum number of all-flash hosts in a single cluster is 64.
- Flash devices are used for both cache and capacity.
- Flash read cache reservation is not used with all-flash configurations. Reads come directly from the capacity tier SSDs.
- Endurance and performance classes now become important considerations for both cache and capacity layers.
- Deduplication and compression available on all-flash only.
- Erasure Coding (Raid5/6) is available on all-flash only.
vSAN POC Setup Assumptions and Pre-Requisites
Prior to starting the proof of concept project, the following pre-requisites must be met. The following assumptions are being made with regards to the deployment:
- N+1 servers are available and compliant with the vSAN HCL.
- All servers have had ESXi 6.7 (build number 8169922) or newer deployed.
- vCenter Server 6.7 (build number 8217866) or newer has been deployed to manage these ESXi hosts. These steps will not be covered in this POC guide. vCenter server must be at the same version or higher than ESXi hosts.
- If possible, configure internet connectivity for vCenter such that the HCL database can be updated automatically. Internet connectivity is also a requirement to enable Customer Experience Improvement Program (CEIP), which is enabled by default to benefit the customers for faster problem resolution and advice on how best to deploy their environments.
- Services such as DHCP, DNS, and NTP are available in the environment where the POC is taking place.
- All but one of the ESXi hosts should be placed in a new cluster container in vCenter.
- The cluster must not have any features enabled, such as DRS, HA or vSAN. These will be done throughout the course of the POC.
- Each host must have a management network vmkernel and a vMotion network vmkernel already configured. There is no vSAN network configured. This will be done as part of the POC.
- For the purposes of testing Storage vMotion operations, an additional datastore type, such as NFS or VMFS, should be presented to all hosts. This is an optional POC exercise.
- A set of IP addresses, one per ESXi host will be needed for the vSAN network VMkernel ports. The recommendation is that these are all on the same VLAN and network segment.
vSAN POC Overview
Overview of a vSAN POC process
Hardware Selection
The Power of Choice
Choosing the appropriate hardware for a PoC is one of the most important factors in the successful validation of vSAN. Below is a list of the more common options for vSAN PoCs:
Bring your own: Organizations considering vSAN for existing workloads can choose their existing hardware. One of the benefits of this option is 100% validation that vSAN achieves the success criteria and there are no surprises.
Virtual PoCs: Organizations solely interested in seeing vSAN functionality may be interested in the Virtual PoC. This is a virtual environment and is not a true test of performance or hardware compatibility but can help stakeholders feel more comfortable using vSAN. Please contact your VMware HCI specialist to take advantage of our “Test Drive” environment.
Loaner PoC: The vSAN PoC team maintains a collection of loaner gear to validate vSAN when there is no hardware available for testing. Please contact your VMware HCI specialist to take advantage of this option.
Hosted PoCs: Many resellers, partners, distributors, and OEMs recognize the power of vSAN and have procured hardware to make it available to their current, and future customers in order to be able to conduct vSAN proof of concepts.
Try and Buy: Whether a VxRail or a vSAN ReadyNode, many partners will provide hardware for a vSAN POC as a “try and buy” option.
There is no right or wrong choice, however choosing the appropriate hardware for a POC is vitally important. There are many variables with hardware (drivers, controller firmware versions) so be sure to choose hardware that is on the VMware Compatibility List.
Once the appropriate hardware is selected it is time to define the PoC use case, goals, expected results and success metrics.
POC Validation Overview
Testing Overview
The most important aspects to validate in a Proof of Concept are:
- Successful vSAN configuration and deployment
- VMs successfully deployed to vSAN Datastore
- Reliability: VMs and data remain available in the event of failure (host, disk, network, power)
- Serviceability: Maintenance of hosts, disk groups, disks, clusters
- Performance: vSAN and selected hardware can meet the application, as well as business needs
- Validation: vSAN data services working as expected (dedupe/compression, RAID-5/6, checksum, encryption)
- Day 2 Operations: Monitoring, management, troubleshooting, upgrades
These can be grouped into 3 common vSAN PoCS: resiliency testing, performance testing, and operational testing.

Operational Testing
Operational testing is a critical part of a vSAN PoC. Understanding how the solution behaves on day-2 operations is important to consider as part of the evaluation. Fortunately, because vSAN is embedded in the ESXi kernel, a lot of the vSAN operations are also vSphere operations. Adding hosts, migrating VMs between nodes, and cluster creation are some of the many operations that are consistent between vSphere and vSAN, resulting in a smaller learning curve, and eliminating the need to have storage specialists.
Some of the Operational Tests include:
- Adding hosts to a vSAN Cluster
- Adding disks to a vSAN node
- Create/Delete a Disk Group
- Clone/vMotion VMs
- Create/edit/delete storage policies
- Assign storage policies to individual objects (VMDK, VM Home)
- Monitoring vSAN
- Embedded vROps (vSAN 6.7 and above)
- Performance Dashboard on H5 client
- Monitor Resync components
- Monitor via vRealize Log Insight
- Put vSAN nodes in Maintenance Mode
- Evacuate Disks
- Evacuate Disk Groups
For more information about operational tests please visit the following sections on the vSAN PoC Guide:
- Basic vSphere Functionality on vSAN
- Scale-Out vSAN
- Monitoring vSAN
- vSAN Storage Policies
- vSAN Management Tasks
Performance Testing
This particular test seems to get a lot of attention during a vSAN POCs, but it's important to understand the requirements of the environment and pay close attention to details such as workload profiles. Prior to conducting a performance test, it is important to have a clear direction on whether it is a benchmark test or a real application test.
Ideally, having a clone of an environment for testing will yield the most accurate results during the test. Understanding the applications, and use case are important as this will determine the policies for objects and/or VMs. For example, if testing the performance of a SQL server solution, you would want to follow the SQL best practices that include using RAID-1 for performance, and also Object Space Reservation of 100% for objects such as the log drive.
On the other hand, a benchmark test can also be helpful as the test tends to be faster because there is no need to clone production VMs or do additional configuration. However, such tests require that you understand the workload profile to be tested. Some characteristics of a workload profile include block size, read/write percentage and sequential/random percentage among others. Conducting such a test will require knowledge of testing tools like Oracle's vdbench, how to deploy and interpret it. To make this test easier for the public, there is a fling tool available called HCIBench, which automates the deployment of Linux VMs with vdbench as a way to generate load on the cluster. vdbench also provides a Web UI interface for to configure and view results. HCIBench will create the number of VMs you specify, with the number of VMDKs you want in just minutes. HCIBench will trigger vSAN Observer on the back end, and make such output available as part of the results. HCIBench is truly a great tool that allows for faster testing utilizing well-known industry benchmarking tools.
One of the tools you can use to obtain your workload profile includes LiveOptics, previously known as DPACK. This tool is free to use.
For more information about HCIBench, please refer to the following blog posts:
- https://blogs.vmware.com/virtualblocks/2016/09/06/use-hcibench-like-pro-part-1/
- https://blogs.vmware.com/virtualblocks/2016/11/03/use-hcibench-like-pro-part-2/
- https://blogs.vmware.com/virtualblocks/2017/01/11/introducing-hcibench-1-6/
- https://labs.vmware.com/flings/hcibench
A high-level view of Performance Testing:
- Characterize the target workload(s)
- LiveOptics
- Simulate target workloads
- HCIBench
- Change Storage Policies and/or vSAN Services as needed
- Compare result reports & vSAN Observer output
.png)
Resiliency Testing
Conducting resiliency testing on a vSAN cluster is an eye-opening experience. By default, vSAN protects your information with 2 replicas of data, based on the vSAN default storage policy (FTT=1 mirroring). As the number of nodes increases, you are presented with the option to further protect your data from multiple failures by increasing your data replicas. With a minimum of 7 nodes, you are able to have up to 4 data replicas, which protects you from 3 failures at once, while still having VMs available. To simplify this guide, we will keep the vSAN default storage policy in mind for any examples.
Just like with any other storage solution, failures can occur on different components at any time due to age, temperature, firmware, etc. Such failures can occur at the storage controller level, disks, nodes, and network devices among others. A failure on any of these components may manifest itself as a failure in vSAN, but there are cases where this may not be true: for instance, a NIC failure might not result in a node disconnecting from the vSAN network, depending on whether redundancy was configured at the network interface/switch level.
When a failure occurs, the objects can go into an absent state or a degraded state. Depending on the state the components are after the failure, they will either rebuild immediately or wait for the time out. By default, the repair delay value is set to 60 minutes because vSAN is not certain if the failure is transient or permanent. One of the common tests conducted is physically removing a drive from a live vSAN node. In this scenario, vSAN sees the drive is missing, and claims failure. vSAN doesn't know if the missing drive will return, so the objects on the drive are put in an absent state. vSAN notes the "absent" state and initiates a 60-minute repair timer countdown begins. If the drive does not come back within the time specified, vSAN will rebuild the objects to go back into policy compliance. If the drive was pulled by mistake, and put back in within the 60 minutes, there is no rebuild, and after quick sync of metadata, the objects will be healthy again.
In cases of a drive failure (PDL), the disk is marked as degraded. vSAN will receive error codes, mark the drive as degraded, and begin the repair immediately.
Now that we understand the different object states based on failure type, it is important to test each type during the POC. Whether you have access to the physical nodes or not, running a test for a failed drive can be hard, unless the drive happens to die during the POC. Fortunately, there are python scripts available within ESXi that allows you to insert various error codes to generate both absent and degraded states. This python script is called vsanDiskFaultInjection.pyc. You can see the usage of this script below.
[root@cs-ie-h01:/usr/lib/vmware/vsan/bin] python ./vsanDiskFaultInjection.pyc -h
Usage:
injectError.py -t -r error_durationSecs -d deviceName
injectError.py -p -d deviceName
injectError.py -z -d deviceName
injectError.py -c -d deviceName
Options:
-h, --help show this help message and exit
-u Inject hot unplug
-t Inject transient error
-p Inject permanent error
-z Inject health error
-c Clear injected error
-r ERRORDURATION Transient error duration in seconds
-d DEVICENAME, --deviceName=DEVICENAME
Apart from disk failure testing, we also recommend to include the following tests to better understand the resiliency of vSAN:
- Simulate node failure with HA enabled
- Introduce network outage
- with & without redundancy
- Physical cable pull
- Network Switch Failure
- vCenter failure
- not considered a vSAN failure as vSAN keeps running
VMware Proof of Concept Resources
The following is a list of PoC evaluation criteria and VMware resources to assist with your evaluation:
|
Evaluation Criteria |
VMware Resources |
|
Full-stack integration, as well as a path to hybrid cloud |
|
|
Enterprise readiness in terms of feature set completeness, resiliency, availability, etc. |
|
|
Performance and sizing |
|
|
Partner ecosystem choices and strength |
(ReadyNode by all major OEMs, appliances, or BYO with certified hardware) |
|
PoC deployment flexibility and options |
Online or hosted:
On-prem:
|
|
Management, Day 2 operations, and OPEX savings |
vSAN Operations and Management Guidance |
|
Architecture fitness for production workloads, particularly Business/Mission Critical Applications (BCA/MCAs) |
vSAN Reference Architectures (Oracle, SQL Server, MySQL, Exchange, DataStax Cassandra, MongoDB, SAP HANA, Delphix, InterSystems Caché and IRIS, Cloudera, etc.) |
vSAN Network Setup
Note: If version 6.7 U1 or higher is used, optionally skip to 'Using Quickstart' in the next chapter to quickly configure a new cluster and enable vSAN
Before vSAN can be enabled, all but one of the hosts must be added to the cluster and assigned management IP addresses. (One host is reserved for later testing of adding a host to the cluster). All ESXi hosts in a vSAN cluster communicate over a vSAN network. For network design and configuration best practices please refer to the VMware vSAN Network Design Guide.
The following example demonstrates how to configure a vSAN network on an ESXi host.
Creating a VMkernel Port for vSAN
In many deployments, vSAN may be sharing the same uplinks as the management and vMotion traffic, especially when 10GbE NICs are utilized. Later on, we will look at an optional workflow that migrates the standard vSwitches to a distributed virtual switch for the purpose of providing Quality Of Service (QoS) to the vSAN traffic through a feature called Network I/O Control (NIOC). This is only available on distributed virtual switches. The good news is that the license for distributed virtual switches is included with all versions of vSAN.
However, the assumption for this POC is that there is already a standard vSwitch created which contains the uplinks that will be used for vSAN traffic. In this example, a separate vSwitch (vSwitch1) with two dedicated 10GbE NICs has been created for vSAN traffic, while the management and vMotion network use different uplinks on a separate standard vSwitch.
To create a vSAN VMkernel port, follow these steps:
Select an ESXi host in the inventory, then navigate to Configure > Networking > VMkernel Adapters. Click on the icon for Add Networking, as highlighted below:

Ensure that VMkernel Network Adapter is chosen as the connection type.
.png)
The next step gives you the opportunity to build a new standard vSwitch for the vSAN network traffic. In this example, an already existing vSwitch1 contains the uplinks for the vSAN traffic. If you do not have this already configured in your environment, you can use an already existing vSwitch or select the option to create a new standard vSwitch. When you are limited to 2 x 10GbE uplinks, it makes sense to use the same vSwitch. When you have many uplinks, some dedicated to different traffic types (as in this example), management can be a little easier if different VSS with their own uplinks are used for the different traffic types.
As there is an existing vSwitch in our environment that contains the network uplinks for the vSAN traffic, the “BROWSE” button is used to select it as shown below.
.png)
Select an existing standard vSwitch via the "BROWSE" button:
.png)
Choose a vSwitch.
.png)
vSwitch1 is displayed once selected.
The next step is to set up the VMkernel port properties, and choose the services, such as vSAN traffic. This is what the initial port properties window looks like:
.png)
Here is what it looks like when populated with vSAN specific information:
.png)
In the above example, the network label has been designated “vSAN Network”, and the vSAN traffic does not run over a VLAN. If there is a VLAN used for the vSAN traffic in your POC, change this from “None (0)” to an appropriate VLAN ID.
The next step is to provide an IP address and subnet mask for the vSAN VMkernel interface. As per the assumptions and prerequisites section earlier, you should have these available before you start. At this point, you simply add them, one per host by clicking on Use static IPv4 settings as shown below. Alternatively, if you plan on using DHCP IP addresses, leave the default setting which is Obtain IPv4 settings automatically.
.png)
The final window is a preview window. Here you can check that everything is as per the options selected throughout the wizard. If anything is incorrect, you can navigate back through the wizard. If everything looks like it is correct, you can click on the FINISH button.
.png)
If the creation of the VMkernel port is successful, it will appear in the list of VMkernel adapters, as shown below.
.png)
That completes the vSAN networking setup for that host. You must now repeat this for all other ESXi hosts, including the host that is not currently in the cluster you will use for vSAN.
If you wish to use a DVS (distributed vSwitch), the steps to migrate from standard vSwitch (VSS) to DVS are documented in the vSphere documentation.
2-Node Direct Connect
From vSAN 6.5, a separately tagged VMkernel interface can be used instead of extending the vSAN data network to the witness host (note that this capability can only be enabled from the command line). This feature allows for a more flexible network configuration by allowing for separate networks for node-to-node vs. node-to-witness communication.
This Witness Traffic Separation provides the ability to directly connect vSAN data nodes in a 2-node configuration; traffic destined for the Witness host can be tagged on an alternative interface from the directly connected vSAN tagged interface. Direct Connect eliminates the need for a 10Gb switch at remote offices/branch offices where the additional cost of the switch could be cost-prohibitive to the solution.
.png)
Enabling Witness Traffic Separation is not available from the vSphere Web Client. For the example illustrated above, to enable Witness Traffic on vmk1, execute the following on Host1 and Host2:
esxcli vsan network ip add -i vmk1 -T=witnessAny VMkernel port not used for vSAN traffic can be used for Witness traffic. In a more simplistic configuration, the Management VMkernel interface, vmk0, could be tagged for Witness traffic. The VMkernel port tagged for Witness traffic will be required to have IP connectivity to the vSAN traffic tagged interface on the vSAN Witness Appliance.
Enabling vSAN
Steps to enable vSAN
Using Quickstart
The 'Quickstart' feature helps simplify a new cluster set up in fewer steps. Either follow this section to configure the cluster or use the next two sections to do so manually.
After creating a new cluster, the user is presented with a dialog to edit settings. Provide a name for the cluster and select vSAN from the list of services:
.png)
The Quickstart screen is then displayed.
.png)
The next step is to add hosts. Clicking on the 'Add' button on the 'Add hosts' section gives us the dialog below. Multiple hosts can then be added at the same time (by IP or FDQN). Additionally, if the credentials of every host are the same, tick the checkbox above the list to quickly complete the form:
.png)
Once the host details have been entered, click next. We are then presented with a dialog showing the thumbprints of the hosts. If these are as expected, tick the checkbox(es) and then click next:
.png)
A summary will be displayed, showing the vSphere version on each host and other details. Check the details are correct and click next:
.png)
Finally, review and click next if everything is in order:
.png)
After the hosts have been added, validation will be performed automatically on the cluster. Check for any errors and inconsistencies and re-validate if necessary:
.png)
The final step is to configure the cluster. After clicking on 'Configure' on step 3, the following dialog allows for the configuration of the distributed switch(es) for the cluster. Leave the default 'Number of distributed switches' set to 1 and assign a name to the switch:
.png)
Scroll down and configure the port groups and physical adapters as needed, then click next:
.png)
On the next screen, set the VLAN and IP addresses to be used, then click next:
.png)
Select the type of deployment: standard or stretched cluster. Enable any extra features, such as deduplication and compression. Check everything is correct and click next:
.png)
If possible, disks will be automatically selected as cache or capacity. Check the selection and click next:
.png)
Configure the fault domains, as required, then click next:
.png)
If stretched cluster was selected, the fault domain selection will look slightly different. Select the appropriate hosts for each fault domain and click next:
.png)
For stretched cluster, chose the witness host, then click next:
.png)
Select the disks for the witness host. Check and click next:
.png)
Finally, check everything is as expected and click finish:
.png)
Wait for the cluster and hosts to be configured correctly then proceed to the next chapter.
Enabling vSAN
Enabling vSAN on the Cluster
Once all the pre-requisites have been met, vSAN can be configured. To enable vSAN complete the following steps:
- Open the vSphere HTML5 Client at https://<vcenter-ip>/ui.
- Click Menu > Hosts and Clusters.
- Select the cluster on which you wish to enable vSAN.
- Click the Configure tab.
- Under vSAN, Select Services and click the CONFIGURE button to start the configuration wizard.

- If desired, Stretched Cluster or 2-Node cluster options can be created as part of the workflow. As part of the basic configuration keep the default selection of Single site cluster and click NEXT.
- When using an All-Flash configuration, you have the option to enable Deduplication and Compression. Deduplication and Compression are covered in a later section of this guide.
- If Encryption of data at rest is a requirement, here is where Encryption can be enabled from the start. We will address encryption later in this POC guide.
- Note: The process of later enabling Deduplication and Compression or Encryption of data at rest can take quite some time, depending on the amount of data that needs to be migrated during the rolling reformat. In a production environment, if Deduplication and Compression is a known requirement, it is advisable to enable this while enabling vSAN to avoid multiple occurrences of rolling reformat.
- Click NEXT
- In the next screen, you can claim all the disks of the same type at once for either vSAN caching tier or capacity tier. For each listed disk make sure it is listed correctly as a flash, HDD, caching device or capacity drive. Click NEXT
- If desired, created fault domains
- Verify the configuration and click FINISH

.png)

.png)

.png)
Once the configuration process is complete, return to the Configure > vSAN > Services view. It may take a few minutes for the cluster to complete all its updates, and you may see some alerts in vCenter until vSAN has settled. After that, you should see the Health and Performance services are enabled by default.
Check Your Network Thoroughly
Once the vSAN network has been created and vSAN is enabled, you should check that each ESXi host in the vSAN Cluster is able to communicate to all other ESXi hosts in the cluster. The easiest way to achieve this is via the vSAN Health Check.
Why Is This Important?
vSAN is dependent on the network: its configuration, reliability, performance, etc. One of the most frequent causes of requesting support is either an incorrect network configuration or the network not performing as expected.
Use Health Check to Verify vSAN Functionality
Running individual commands from one host to all other hosts in the cluster can be tedious and time-consuming. Fortunately, since vSAN 6.0, vSAN has a health check system, part of which tests the network connectivity between all hosts in the cluster. One of the first tasks to do after setting up any vSAN cluster is to perform a vSAN Health Check. This will reduce the time to detect and resolve any networking issue, or any other vSAN issues in the cluster.
To run a vSAN Health Check, navigate to [vSAN cluster] > Monitor > vSAN > Health and click the RETEST button.
In the screenshot below, one can see that each of the health checks for networking has successfully passed.
.png)
If any of the network health checks fail, select the appropriate check and examine the details pane on the right for information on how to resolve the issue. Each detailed view under the Info tab also contains an AskVMware button where appropriate, which will take you to a VMware Knowledge Base article detailing the issue, and how to troubleshoot and resolve it.
Before going any further with this POC, download the latest version of the HCL database and run a RETEST on the Health check screen. Do this by selecting vSAN HCL DB up-to-date health check under the "Hardware compatibility" category, and choosing GET LATEST VERSION ONLINE or UPDATE FROM FILE... if there is no internet connectivity.
.png)
The Performance Service is enabled by default. You can check its status from [vSAN cluster] > Configure > vSAN > Services. If it needs to be enabled, click the EDIT button next to Performance Service and turn it on using the defaults. The Performance Service provides vSAN performance metrics to vCenter and other tools like vRealize Operations Manager.
.png)
To ensure everything in the cluster is optimal, the Health service will also check the hardware against the VMware Compatibility Guide (VCG) for vSAN. Verify that the networking is functional, that there are no underlying disk problems or vSAN integrity issues. The desired goal is to have all the health checks succeed.
At this point, vSAN is successfully deployed. The remainder of this POC guide will involve various tests and error injections to show how vSAN will behave under these circumstances.
Basic vSphere Functionality on vSAN
Basic functionality
Deploy Your First VM
This initial test will highlight the fact that general virtual machine operations are unchanged in vSAN environments.
In this section, a VM is deployed to the vSAN datastore using the default storage policy. This default policy is preconfigured and does not require any intervention unless you wish to change the default settings, which we do not recommend.
To examine the default policy settings, navigate to Menu > Shortcuts > VM Storage Policies .
.png)
From there, select vSAN Default Storage Policy. Look under the Rules tab to see the settings on the policy:
.png)
We will return to VM Storage Policies in more detail later, but suffice to say that when a VM is deployed with the default policy, it should have a mirror copy of the VM data created. This second copy of the VM data is placed on storage on a different host to enable the VM to tolerate any single failure. Also note that object space reservation is set to 'Thin provisioning', meaning that the object should be deployed as “thin”. After we have deployed the VM, we will verify that vSAN adheres to both of these capabilities.
One final item to check before we deploy the VM is the current free capacity on the vSAN datastore. This can be viewed from the [vSAN cluster] > Monitor > vSAN > Capacity view. In this example, it is 4.37 TB.
.png)
Make a note of the free capacity in your POC environment before continuing with the deploy VM exercise.
To deploy the VM, simply follow the steps provided in the wizard.
Select New Virtual Machine from the Actions Menu.
Select Create a new virtual machine .
At this point, a name for the VM must be provided, and then the vSAN Cluster must be selected as a compute resource.
Enter a Name for the VM and select a folder:
.png)
Select a compute resource:
Up to this point, the virtual machine deployment process is identical to all other virtual machine deployments that you have done on other storage types. It is the next section that might be new to you. This is where a policy for the virtual machine is chosen.
From the next menu, "4. Select storage", select the vSAN datastore, and the Datastore Default policy will actually point to the vSAN Default Storage Policy.
Once the policy has been chosen, datastores are split into those that are either compliant or non-compliant with the selected policy. As seen below, only the vSAN datastore can utilize the policy settings in the vSAN Default Storage Policy, so it is the only one that shows up as Compatible in the list of datastores.
.png)
The rest of the VM deployment steps in the wizard are quite straightforward, and simply entail selecting ESXi version compatibility (leave at default), a guest OS (leave at default) and customize hardware (no changes). Essentially you can click through the remaining wizard screens without making any changes.
Verifying Disk Layout of a VM stored in vSAN
Once the VM is created, select the new VM in the inventory, navigate to the Configure tab, and then select Policies. There should be two objects shown, "VM home" and "Hard disk 1". Both of these should show a compliance status of Compliant meaning that vSAN was able to deploy these objects in accordance with the policy settings.
.png)
To verify this, navigate to the Cluster's Monitor tab, and then select Virtual Objects. Once again, both the “VM home” and “Hard disk 1” should be displayed. Select “Hard disk 1” followed by View Placement Details. This should display a physical placement of RAID 1 configuration with two components, each component representing a mirrored copy of the virtual disk. It should also be noted that different components are located on different hosts. This implies that the policy setting to tolerate 1 failure is being adhered to.
.png)
.png)
The witness item shown above is used to maintain a quorum on a per-object basis. For more information on the purpose of witnesses, and objects and components in general, refer to the VMware vSAN Design and Sizing Guide on https://storagehub.vmware.com.
The “object space reservation” policy setting defines how much space is initially reserved on the vSAN datastore for a VM's objects. By default, it is set to "Thin provisioning", implying that the VM’s storage objects are entirely “thin” and consume no unnecessary space. Note the free capacity in the vSAN datastore after deploying the VM, we see that the free capacity is very close to what it was before the VM was deployed, as displayed :
.png)
Of course we have not installed anything in the VM (such as a guest OS) - it shows that only a tiny portion of the vSAN datastore has so far been used, verifying that the object space reservation setting of "Thin provisioning" is working correctly (observe that the "Virtual disks" and "VM home objects" consume less than 1GB in total, as highlighted in the "Used Capacity Breakdown" section).
Do not delete this VM as we will use it for other POC tests going forward.
Creating A Snapshot
Using the virtual machine created previously, take a snapshot of it. The snapshot can be taken when the VM is powered on or powered off. The objectives are to see that:
- no setup is needed to make vSAN handle snapshots
- the process for creating a VM snapshot is unchanged with vSAN
- a successful snapshot delta object is created
- the policy settings of the delta object are inherited directly from the base disk object
From the VM object in vCenter, click Actions > Snapshots > Take Snapshot...
.png)
Take a Snapshot of the virtual machine created in the earlier step.

Provide a name for the snapshot and optional description.
Once the snapshot has been requested, monitor tasks and events to ensure that it has been successfully captured. Once the snapshot creation has completed, additional actions will become available in the snapshot drop-down window. For example, there is a new action to Revert to Latest Snapshot and another action to Manage Snapshots.
.png)
Choose the Manage Snapshots option. The following is displayed. It includes details regarding all snapshots in the chain, the ability to delete one or all of them, as well as the ability to revert to a particular snapshot.
.png)
To see snapshot delta object information from the UI, navigate to [vSAN Cluster] > Monitor > vSAN > Virtual Objects .
.png)
There are now three objects that are associated with that virtual machine. First is the "VM Home" namespace. "Hard disk 1" is the base virtual disk, and "Hard disk 1 - poc-test-vm1.vmdk" is the snapshot delta. Notice the snapshot delta inherits its policy settings from the base disk that needs to adhere to the vSAN Default Storage Policy.
The snapshot can now be deleted from the VM. Monitor the VM’s tasks and ensure that it deletes successfully. When complete, snapshot management should look similar to this.
.png)
This completes the snapshot section of this POC. Snapshots in a vSAN datastore are very intuitive because they utilize vSphere native snapshot capabilities. Starting with vSAN 6.0, they are stored efficiently using “vsansparse” technology that improves the performance of snapshots compared to vSAN 5.5. In vSAN 6.1, snapshot chains can be up to 16 snapshots deep.
Clone A Virtual Machine
The next POC test is cloning a VM. We will continue to use the same VM as before. This time make sure the VM is powered on first. There are a number of different cloning operations available in vSphere 6.7. These are shown here.
.png)
The one that we will be running as part of this POC is the “Clone to Virtual Machine”. The cloning operation is a fairly straightforward click-through operation. This next screen is the only one that requires human interaction. One simply provides the name for the newly cloned VM, and a folder if desired.
.png)
We are going to clone the VM in the vSAN cluster, so this must be selected as the compute resource.
.png)
The storage will be the same as the source VM, namely the vsanDatastore. This will all be pre-selected for you if the VM being cloned also resides on the vsanDatastore.
Select Storage
.png)
Select from the available options (leave unchecked - default)
This will take you to the “Ready to complete” screen. If everything is as expected, click FINISH to commence the clone operation. Monitor the VM tasks for the status of the clone operation.
.png)
Do not delete the newly cloned VM. We will be using it in subsequent POC tests.
This completes the cloning section of this POC.
vMotion A Virtual Machine Between Hosts
The first step is to power-on the newly cloned virtual machine. We shall migrate this VM from one vSAN host to another vSAN host using vMotion.
Note: Take a moment to revisit the network configuration and ensure that the vMotion network is distinct from the vSAN network. If these features share the same network, performance will not be optimal.
First, determine which ESXi host the VM currently resides on. Selecting the Summary tab of the VM shows this. In this POC task, the VM that we wish to migrate is on host poc2.vsanpe.vmware.com.
.png)
Right-click on the VM and select Migrate.
.png)
"Migrate" allows you to migrate to a different compute resource (host), a different datastore or both at the same time. In this initial test, we are simply migrating the VM to another host in the cluster, so this initial screen should be left at the default of “Change compute resource only”. The rest of the screens in the migration wizard are pretty self-explanatory.
.png)
Select Change compute resource only
.png)
Select a destination host.
.png)
Select a destination network.
.png)
The vMotion priority can be left as high(default)
At the “Ready to complete” window, click on FINISH to initiate the migration. If the migration is successful, the summary tab of the virtual machine should show that the VM now resides on a different host.
.png)
Verify that the VM has been migrated to a new host.
Do not delete the migrated VM. We will be using it in subsequent POC tests.
This completes the “VM migration using vMotion” section of this POC. As you can see, vMotion works just great with vSAN.
Storage vMotion A VM Between Datastores
This test will only be possible if you have another datastore type available to your hosts, such as NFS/VMFS. If so, then the objective of this test is to successfully migrate a VM from another datastore type into vSAN and vice versa. The VMFS datastore can even be a local VMFS disk on the host.
Mount an NFS Datastore to the Hosts
The steps to mount an NFS datastore to multiple ESXi hosts are described in the vSphere 6.7 Administrators Guide. See the Create NFS Datastore in the vSphere Client topic for detailed steps.
Storage vMotion a VM from vSAN to another Datastore Type
Currently, the VM resides on the vSAN datastore. Launch the migrate wizard, similar to the previous exercise. However, on this occasion move the VM from the vSAN datastore to another datastore type by selecting Change storage only.
.png)
In this POC environment, we have an NFS datastore presented to each of the ESXi hosts in the vSAN cluster. This is the intended destination datastore for the virtual machine.
.png)
Select destination storage.
One other item of interest in this step is that the VM Storage Policy should also be changed to Datastore Default as the NFS datastore will not understand the vSAN policy settings.
At the “Ready to complete” screen, click FINISH to initiate the migration:
.png)
Once the migration completes, the VM Summary tab can be used to examine the datastore on which the VM resides.
.png)
Verify that the VM has been moved to the new storage.
Scale Out vSAN
Scaling out vSAN
Scale Out vSAN By Adding A Host To The Cluster
One of the really nice features is the simplistic scale-out nature of vSAN. If you need more compute or storage resources in the cluster, simply add another host to the cluster.
Before initiating the task, revisit the current state of the cluster. There are currently three hosts in the cluster, and there is a fourth host not in the cluster. We also created two VMs in the previous exercises.
.png)
Let us also remind ourselves of how big the vSAN datastore is.
.png)
In the current state, the size of the vSAN datastore is 3.52TB with a free capacity of 3.47TB free.
Add the Fourth Host to vSAN Cluster
We will now proceed with adding a fourth host to the vSAN Cluster.
Note: Back in section 2 of this POC guide, you should have already set up a vSAN network for this host. If you have not done that, revisit section 2, and set up the vSAN network on this fourth host.
Having verified that the networking is configured correctly on the fourth host, select the new host in the inventory, right-click on it and select the option Move To… as shown below.
.png)
You will then be prompted to select the location to which the host will be moved. In this POC environment, there is only one vSAN cluster. Select that cluster.

Select a cluster as the destination for the host to move into.
The next screen is related to resource pools. You can leave this at the default, which is to use the cluster’s root resource pool, then click OK .
.png)
This moves the host into the cluster. Next, navigate to the Hosts and Clusters view and verify that the cluster now contains the new node.
.png)
As you can see, there are now 4 hosts in the cluster. However, you will also notice from the Capacity view that the vSAN datastore has not changed with regards to total and free capacity. This is because vSAN does not claim any of the new disks automatically. You will need to create a disk group for the new host and claim disks manually. At this point, it would be good practice to re-run the health check tests. If there are any issues with the fourth host joining the cluster, use the vSAN Health Check to see where the issue lies. Verify that the host appears in the same network partition group as the other hosts in the cluster.
Note: Beginning in vSAN 6.7 U1, we have added a faster way to create, and scale-out vSAN clusters. Refer to the Quickstart chapter to learn more.
Create A Disk Group On A New Host
Navigate to [vSAN Cluster] > Configure > vSAN > Disk Management, select the new host and then click on the highlighted icon to claim unused disks for a new disk group:
.png)
As before, we select a flash device as cache disk and three flash devices as capacity disks. This is so that all hosts in the cluster maintain a uniform configuration.
.png)
Select flash and capacity devices.
Verify vSAN Disk Group Configuration on New Host
Once the disk group has been created, the disk management view should be revisited to ensure that it is healthy.
.png)
Verify New vSAN Datastore Capacity
The final step is to ensure that the vSAN datastore has now grown in accordance to the capacity devices in the disk group that was just added on the fourth host. Return to the Capacity view and examine the total and free capacity fields.
.png)
As we can clearly see, the vSAN datastore has now grown in size to 4.69TB. Free space is shown as 4.62TB as the amount of space used is minimal. The original datastore capacity with 3 hosts (in the example POC environment) was 3.52TB.
This completes the “Scale-Out” section of this POC. As seen, scale-out on vSAN is simple but very powerful.
Monitoring vSAN
When it comes to monitoring vSAN, there are a number of areas that need particular attention.
These are the key considerations when it comes to monitoring vSAN:
- Overall vSAN Health
- Resynchronization & rebalance operations in the vSAN cluster
- Performance Monitoring through vCenter UI and command-line utility(vsantop)
- Advanced monitoring through integrated vROPS dashboards
Overall vSAN Health
The first item to monitor is the overall health of the cluster. vSAN Health provides a consolidated list of health checks that correlate to the resiliency and performance of a vSAN cluster. From the vCenter, Navigate to the cluster object, then go to [vSAN Cluster] > Monitor > vSAN > Health. This provides a holistic view of the health states pertaining to hardware and software components that constitute a vSAN cluster. There is an exhaustive validation of components states, configuration, and compatibility.
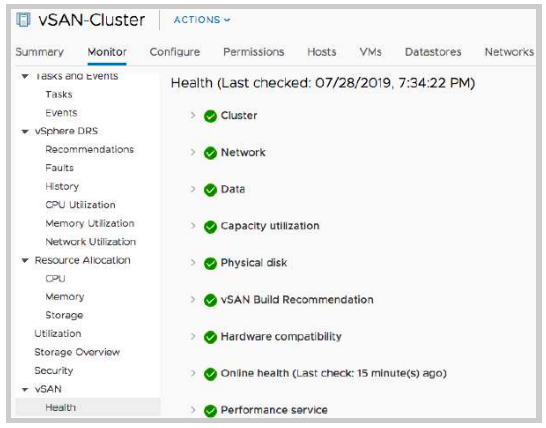
More information about this is available here - Working with vSAN Health checks.
Resync Operations
Another very useful view is [vSAN Cluster] > Monitor > vSAN > Resyncing Objects view. This will display any resyncing or rebalancing operation that might be taking place on the cluster. For example, if there was a device failure, resyncing or rebuilding activity could be observed here. Resync can also happen if a device was removed or a host failed, and the CLOMd (Cluster Logical Object Manager daemon) timer expired. Resyncing objects dashboard provides details of the resync status, amount of data in transit and estimated time to completion.
With regards to rebalancing, vSAN attempts to keep all physical disks at less than 80% capacity. If any physical disks’ capacity passes this threshold, vSAN will move components from this disk to other disks in the cluster in order to rebalance the physical storage.
In an ideal state, no resync activity should be observed, as shown below.
.png)
Resyncing activity usually indicates:
- a failure of a device or host in the cluster
- a device has been removed from the cluster
- a physical disk has greater than 80% of its capacity consumed
- a policy change has been implemented which necessitates a rebuilding of a VM’s object layout. In this case, a new object layout is created, synchronized with the source object, and then discards the source object
Performance Monitoring through vCenter UI
The Performance monitoring service has existed since vSAN 6.2. The performance service can be used for verification of performance as well as quick troubleshooting of performance-related issues. Performance charts are available for many different levels.
- Cluster
- Hosts
- Virtual Machines and Virtual Disks
- Disk groups
- Physical disks
A detailed list of performance graphs and descriptions can be found here.
The performance monitoring service is enabled by default starting in vSAN 6.7. If in case it was disabled, it can be re-enabled through the following steps:
Navigate to the vSAN Cluster.
- Click the Configure tab.
- Select Services from the vSAN Section
- Navigate to Performance Service, Click EDIT to edit the performance settings.
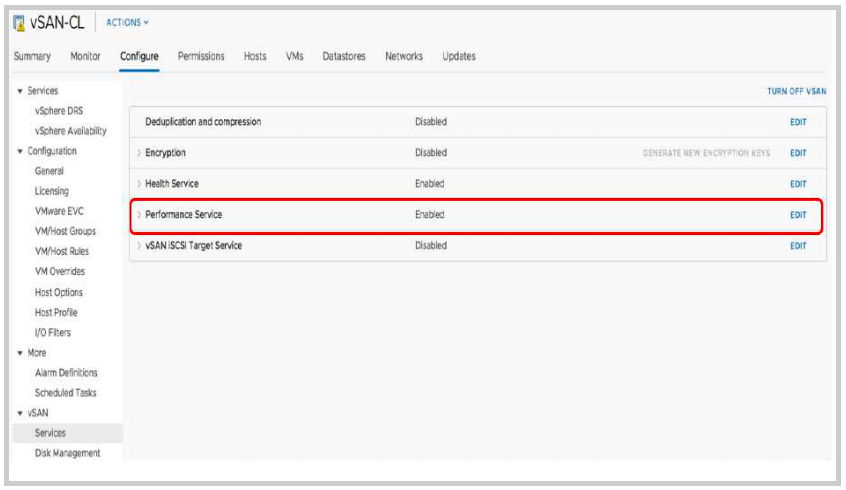
Once the service has been enabled performance statistics can be viewed from the performance menus in vCenter. The following example is meant to provide an overview of using the performance service. For purposes of this exercise, we will examine IOPS, throughput and latency from the Virtual Machine level and the vSAN Backend level.
The cluster level shows performance shows metrics from a cluster level. This includes all virtual machines. Let’s take a look at IOPS from a cluster level. To access cluster-level performance graphs:
- From the Cluster level in vCenter, Click on the Monitor tab.
- Navigate to the vSAN section and click on Performance
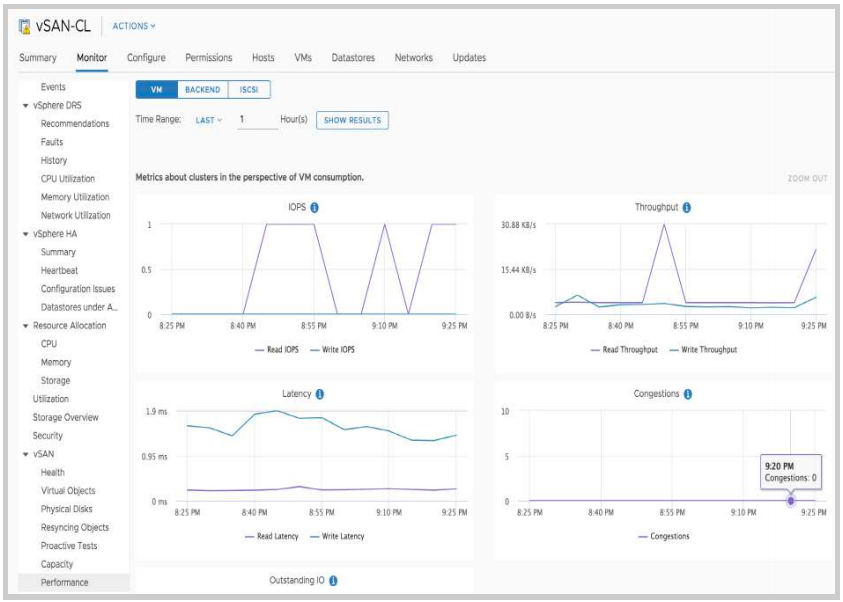
For this portion of the example, we will step down a level and the performance statistics for the vSAN Backend. To access the vSAN - Backend performance metrics select the BACKEND tab from the menu on the left.
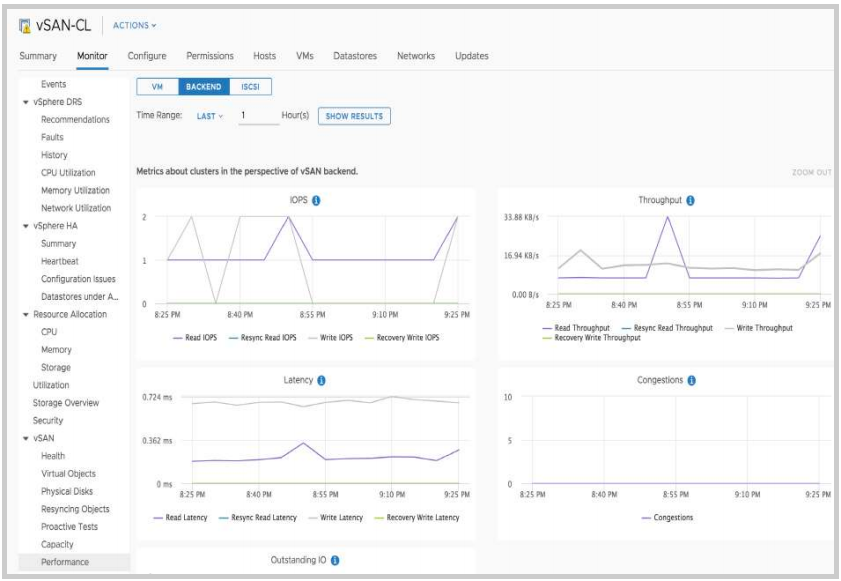
The performance service allows administrators to view not only real-time data but historical data as well. By default, the performance service looks at the last hour of data. This time window can be increased or changed by specifying a custom range.
Performance monitoring through vsantop utility
With vSphere 6.7 Update 3 a new command-line utility: vsantop has been introduced. This utility is focused on monitoring vSAN performance metrics at an individual host level. Traditionally with ESXi, an embedded utility called esxtop was used to view real-time performance metrics. This utility helped in ascertaining resource utilization and performance of the system. However, vSAN required a custom utility aware of its distributed architecture. vsantop is built with an awareness of vSAN architecture to retrieve focused metrics at a granular interval. vsantop is embedded in the hypervisor. It collects and persists statistical data in a RAM disk. Based on the configured interval rate, the metrics are displayed on the secure shell console. This interval is configurable and can be reduced or increased depending on the amount of detail required. The workflow is illustrated below for a better understanding.
.png)
To initiate vsantop, Log in to the ESXi host through a secure shell(ssh) with root user privileges and run the command vsantop on the ssh console.
vsantop provides detailed insights into vSAN component level metrics at a low interval rate. This helps in understanding resource consumption and utilization pattern. vsantop is primarily intended for advanced vSAN users and VMware support personnel.
Monitoring vSAN through integrated vRealize Operations Manager in vCenter
Monitoring vSAN has become simpler and accessible from the vCenter UI. This is made possible through the integration of vRealize Operations Manager plugin in vCenter.
The feature is enabled through the HTML5 based vSphere client and allows an administrator to either install a new instance or integrate with an existing vRealize Operations Manager.
You can initiate the workflow by navigating to Menu > vRealize Operations as shown below:
.png)
Once the integration is complete, you can access the predefined dashboards as shown below:
.png)
The following out-of-the-box dashboards are available for monitoring purposes,
- vCenter - Overview
- vCenter - Cluster View
- vCenter - Alerts
- vSAN- Overview
- vSAN - Cluster View
- vSAN - Alerts
From a vSAN standpoint, the Overview, Cluster View and Alerts dashboards allow an administrator to have a snapshot of the vSAN cluster. Specific performance metrics such as IOPs, Throughput, Latency, and Capacity related information are available as depicted below,
.png)
VM Storage Policies and Storage
Storage Policies
VM Storage Policies form the basis of VMware’s Software-Defined Storage vision. Rather than deploying VMs directly to a datastore, a VM Storage Policy is chosen during initial deployment. The policy contains the characteristics and capabilities of the storage required by the virtual machine. Based on the policy contents, the correct underlying storage is chosen for the VM.
If the underlying storage meets the VM storage Policy requirements, the VM is said to be in a compatible state.
If the underlying storage fails to meet the VM storage Policy requirements, the VM is said to be in an incompatible state.
In this section of the POC Guide, we shall look at various aspects of VM Storage Policies. The virtual machines that have been deployed thus far have used the vSAN Default Storage Policy, which has the following settings:
| Storage Type | vSAN |
| Site disaster tolerance | None(standard cluster) |
| Failures to tolerate | 1 failure - RAID-1 (Mirroring) |
| Number of disk stripes per object | 1 |
| IOPS limit for object | 0 |
| Object space reservation | Thin provisioning |
| Flash read cache reservation | 0% |
| Disable object checksum | No |
| Force provisioning | No |
In this section of the POC, we will walk through the process of creating additional storage policies.
Create A New VM Storage Policy
In this part of the POC, we will build a policy that creates a stripe width of two for each storage object deployed with this policy. The VM Storage Policies can be accessed from the 'Shortcuts' page on the vSphere client (HTML 5) as shown below.

There will be some existing policies already in place, such as the vSAN Default Storage policy (which we’ve already used to deploy VMs in section 4 of this POC guide). In addition, there is another policy called “VVol No Requirements Policy”, which is used for Virtual Volumes and is not applicable to vSAN.
To create a new policy, click on Create VM Storage Policy .

The next step is to provide a name and an optional description for the new VM Storage Policy. Since this policy will contain a stripe width of 2, we have given it a name to reflect this. You may also give it a name to reflect that it is a vSAN policy.

The next section sets the policy structure. We select Enable rules for "vSAN" Storage to set a vSAN specific policy

Now we get to the point where we create a set of rules. The first step is to select the Availability of the objects associated with this rule, i.e. the failures to tolerate.

We then set the Advanced Policy Rules. Once this is selected, the six customizable capabilities associated with vSAN are exposed. Since this VM Storage Policy is going to have a requirement where the stripe width of an object is set to two, this is what we select from the list of rules. It is officially called “ Number of disk stripes per object ”.

Clicking NEXT moves on to the Storage Compatibility screen. Note that this displays which storage “understands” the policy settings. In this case, the vsanDatastore is the only datastore that is compatible with the policy settings.
Note: This does not mean that the vSAN datastore can successfully deploy a VM with this policy; it simply means that the vSAN datastore understands the rules or requirements in the policy.
.png)
At this point, you can click on NEXT to review the settings. On clicking FINISH, the policy is created.

Let’s now go ahead and deploy a VM with this new policy, and let’s see what effect it has on the layout of the underlying storage objects.
Deploy A New VM With The New Storage Policy
The workflow to deploy a New VM remains the same until we get to the point where the VM Storage Policy is chosen. This time, instead of selecting the default policy, select the newly created StripeWidth=2 policy as shown below.
.png)
As before, the vsanDatastore should show up as the compatible datastore, and thus the one to which this VM should be provisioned.
.png)
Now let's examine the layout of this virtual machine, and see if the policy requirements are met; i.e. do the storage objects of this VM have a stripewidth of 2? First, ensure that the VM is compliant with the policy by navigating to [VM] > Configure > Policies, as shown here.
.png)
The next step is to select the [vSAN Cluster] > Monitor > vSAN > Virtual Objects and check the layout of the VM’s storage objects. The first object to check is the "VM Home" namespace. Select it, and then click on the View Placement Details icon.
.png)
This continues to show that there is only one mirrored component, but no stripe width (which is displayed as a RAID 0 configuration). Why? The reason for this is that the "VM home" namespace object does not benefit from striping so it ignores this policy setting. Therefore this behavior is normal and to be expected.
.png)
Now let’s examine “Hard disk 1” and see if that layout is adhering to the policy. Here we can clearly see a difference. Each replica or mirror copy of the data now contains two components in a RAID 0 configuration. This implies that the hard disk storage objects are indeed adhering to the stripe width requirement that was placed in the VM Storage Policy.
.png)
Note that each striped component must be placed on its own physical disk. There are enough physical disks to meet this requirement in this POC. However, a request for a larger stripe width would not be possible in this configuration. Keep this in mind if you plan a POC with a large stripe width value in the policy.
It should also be noted that snapshots taken of this base disk continue to inherit the policy of the base disk, implying that the snapshot delta objects will also be striped.
Edit VM Storage Policy Of An Existing VM
You can choose to modify the VM Storage Policy of an existing VM deployed on the vSAN datastore. The configuration of the objects associated with the VM will be modified to comply with the newer policy. For example if NumberOfFailuresToTolerate is increased, newer components would be created, synchronized with the existing object, and subsequently, the original object is discarded. VM Storage policies can also be applied to individual objects.
In this case, we will add the new StripeWidth=2 policy to one of the VMs which still only has the default policy (NumberOfFailuresToTolerate =1, NumberOfDiskStripesPerObject =1, ObjectSpaceReservation =0) associated with it.
To begin, select the VM that is going to have its policy changed from the vCenter inventory, then select the Configure > Policies view. This VM should currently be compliant with the vSAN Default Storage Policy. Now click on the EDIT VM STORAGE POLICIES button as highlighted below.
.png)
This takes you to the edit screen, where the policy can be changed.
.png)
Select the new VM Storage Policy from the drop-down list. The policy that we wish to add to this VM is the StripeWidth=2 policy.

Once the policy is selected, click OK button as shown above to ensure the policy gets applied to all storage objects. The VM Storage Policy should now appear updated for all objects.
Now when you revisit the Configure > Policies view, you should see the changes in the process of taking effect (Reconfiguring) or completed, as shown below.
.png)
This is useful when you only need to modify the policy of one or two VMs, but what if you need to change the VM Storage Policy of a significant number of VMs.
That can be achieved by simply changing the policy used by those VMs. All VMs using those VMs can then be “brought to compliance” by reconfiguring their storage object layout to make them compliant with the policy. We shall look at this next.
Note that modifying or applying a new VM Storage Policy causes additional backend IO while the objects are being synchronized.
Modify A VM Storage Policy
In this task, we shall modify an existing VM Storage policy to include an ObjectSpaceReservation =25%. This means that each storage object will now reserve 25% of the VMDK size on the vSAN datastore. Since all VMs were deployed with 40GB VMDKs with Failures to tolerate="1 failure - RAID-1 (Mirroring)", the reservation value will be 20 GB.
As the first step, note the amount of free space in the vSAN datastore. This would help ascertain the impact of the change in the policy.

Select StripeWidth=2 policy from the list of available policies, and then the Edit Settings option. Navigate to vSAN > Advanced Policy Rules and modify the Object space reservation setting to 25%, as shown below
.png)
Proceed to complete the wizard with default values and click FINISH. A pop-up message requiring user input appears with details of the number of VMs using the policy being modified. This is to ascertain the impact of the policy change. Typically such changes are recommended to be performed during a maintenance window. You can choose to enforce a policy change immediately or defer it to be changed manually at a later point. Leave it at the default, which is “Manually later”, by clicking Yes as shown below:
.png)
Next, Select the Storage policy - StripeWidth=2 and click on the VM Compliance tab in the bottom pane. It will display the two VMs along with with their storage objects, and the fact that they are no longer compliant with the policy. They are in an “Out of Date” compliance state as the policy has now been changed.
You can now enforce a policy change by navigating to [VM Storage Policies] and clicking on Reapply VM Storage Policy

When this button is clicked, the following popup appears.
.png)
When the reconfigure activity completes against the storage objects, and the compliance state is once again checked, everything should show as "Compliant".
.png)
Since we have now included an ObjectSpaceReservation value in the policy, you may notice corresponding capacity reduce from the vSAN datastore.
For example, the two VMs with the new policy change have 40GB storage objects. Therefore, there is a 25% ObjectSpaceReservation implying 10GB is reserved per VMDK. So that's 10GB per VMDK, 1 VMDK per VM, 2 VMs equals 20 GB reserved space, right? However, since the VMDK is also mirrored, so there is a total of 40GB reserved on the vSAN datastore.
Adding IOPS Limits and Checksum
vSAN incorporates a quality of service feature that can limit the number of IOPS an object may consume. IOPS limits are enabled and applied via a policy setting. The setting can be used to ensure that a particular virtual machine does not consume more than its fair share of resources or negatively impact the performance of the cluster as a whole.
IOPS Limit
To create a new policy with an IOPS limit complete the following steps:
- Create a new Storage Policy similar as done previously
- In the Advanced Policy Rules set IOPS limit for object.
- Enter a value in the "IOPS limit for object" box.
.png)
- Note that this value is calculated as the number of IOs using a weighted size of 32KB. In this example, we will use a value of 1000. Applying this rule to an object will result in an IOPS limit of 1000x32KB=32MB being set.
It is important to note that not only is read and write I/O counted in the limit but any I/O incurred by a snapshot is counted as well. If I/O against this VM or VMDK should rise above the 1000 threshold, the additional I/O will be throttled.
Checksum
In addition, by default end-to-end software checksum is enabled to ensure data integrity. In certain scenarios, an application or operating system within the VM has an inbuilt checksum mechanism. In such instances, you may choose to disable Object Checksum at the vSAN layer.
Follow these steps to disable Object Checksum,
- From the vSphere Client, navigate to Menu > Policies and Profiles and select VM Storage Policies.
- Select a Storage Policy to modify.
- Select Edit Settings
- Click NEXT and Navigate to Advanced Policy Rules
- Toggle Disable object checksum option as shown below:
.png)
vSAN Performance Testing
Performance Testing Overview
Performance testing is an important part of evaluating any storage solution. However, setting up a suitable and consistent test environment can be challenging - there are many tools that simulate workloads, and many ways to collect the generated data and logs. This adds complexity in troubleshooting performance issues and lengthens the evaluation process.
vSAN Performance will primarily depend on: the storage devices that are in the hosts (SSD, magnetic disks); the storage policies configured on the VMs (how widely the data is spread across the devices); the size of the working set and the type of workload, and so on. Moreover, a major factor for VM performance is how the virtual hardware is configured: how many virtual SCSI controllers, VMDKs, outstanding I/O and how many vCPUs that are pushing I/O.
vSAN’s distributed architecture dictates that reasonable performance is achieved when the pooled compute and storage resources in the cluster are well utilized: this usually means VM workloads should be distributed throughout the cluster to achieve consistent aggregated performance. In this context, detailed performance monitoring and analysis becomes ever important.
From version 6.7, the vSAN performance service is automatically enabled when a vSAN cluster is created from the vCenter HTML5 UI. Performance graphs, which provide a valuable first insight into resource consumption and bottlenecks, can be conveniently viewed in vCenter without any additional setup requirements. Moreover, performance benchmarks run from HCIbench are captured and available for viewing within the same UI. More information on HCIbench can be found in the section 'Performance Testing Using HCIbench'.
To view the performance graphs navigate to [vSAN cluster] > Monitor > Performance . Here, one can visualize VM, Backend and ISCSI performance stats over a 24 hour period.
With vSphere 6.7 Update 3 a new command-line utility: vsantop has been introduced. This utility is focused on monitoring vSAN performance metrics at an individual host level. vsantop can be accessed through a secure shell to the ESXi hosts in a vSAN cluster. It is embedded in the hypervisor, collects and persists statistical data in a RAM disk.
More details of the performance service and vsantop can be found in chapter 7, under 'vSAN Monitoring'.
Performance Considerations
Single vs. Multiple Workers
vSAN is designed to support good performance when many VMs are distributed and running simultaneously across the hosts in the cluster. Running a single storage test in a single VM won’t reflect on the aggregate performance of a vSAN-enabled cluster. Regardless of what tool you are using – IOmeter, VDbench or something else – plan on using multiple “workers” or I/O processors to multiple virtual disks to get representative results.
Working Set
For the best performance, a virtual machine’s working set should be mostly in the cache. Care will have to be taken when sizing your vSAN flash to account for all of your virtual machines’ working sets residing in the cache. A general rule of thumb for Hybrid clusters is to size cache as 10% of your consumed virtual machine storage (not including replica objects). While this is adequate for most workloads, understanding your workload’s working set before sizing is a useful exercise. Consider using VMware Infrastructure Planner (VIP) tool to help with this task – http://vip.vmware.com.
Sequential Workloads versus Random Workloads
Sustained sequential write workloads (such as VM cloning operations) that run on vSAN could fill the cache, and future writes will need to wait for the cache to be destaged to the spinning magnetic disk layer before more I/Os can be written to cache, so performance will be a reflection of the spinning disk(s) and not of flash. The same is true for sustained sequential read workflows. If the block is not in the cache, it will have to be fetched from the spinning disk. Mixed workloads will benefit more from vSAN’s caching design.
Outstanding IOs
Most testing tools have a setting for Outstanding IOs, or OIO for short. It shouldn’t be set to 1, nor should it be set to match a device queue depth. Consider a setting between 2 and 8, depending on the number of virtual machines and VMDKs that you plan to run. For a small number of VMs and VMDKs, use 8. For a large number of VMs and VMDKs, consider setting it lower.
Block Size
The block size that you choose is really dependent on the application/workload that you plan to run in your VM. While the block size for a Windows Guest OS varies between 512 bytes and 1MB, the most common block size is 4KB. But if you plan to run SQL Server, or MS Exchange workloads, you may want to pick block sizes appropriate to those applications (they may vary from application version to application version). Since it is unlikely that all of your workloads will use the same block size, consider a number of performance tests with differing, but commonly used, block sizes.
Cache Warming Considerations
Flash as cache helps performance in two important ways. First, frequently read blocks end up in the cache, dramatically improving performance. Second, all writes are committed to the cache first, before being efficiently destaged to disks – again, dramatically improving performance.
However, data still has to move back and forth between disks and cache. Most real-world application workloads take a while for cache to “warm-up” before achieving steady-state performance.
Number of Magnetic Disk Drives in Hybrid Configurations
In the getting started section, we discuss how disk groups with multiple disks perform better than disk groups with fewer, as there are more disk spindles to destage to as well as more spindles to handle read cache misses. Let’s look at a more detailed example of this.
Consider a vSAN environment where you wish to clone a number of VMs to the vSAN datastore. This is a very sequential I/O intensive operation. We may be able to write into the SSD write buffer at approximately 200-300 MB per second. A single magnetic disk can maybe do 100MB per second. So assuming no read operations are taking place at the same time, we would need 2-3 magnetic disks to match the SSD speed for destaging purposes.
Now consider that there might also be some operations going on in parallel. Let’s say that we have another vSAN requirement to achieve 2000 read IOPS. vSAN is designed to achieve a 90% read cache hit rate (approximately). That means 10% of all reads are going to be read cache misses; for example, that is 200 IOPS based on our requirement. A single magnetic disk can perhaps achieve somewhere in the region of 100 IOPS. Therefore, an additional 2 magnetic disks will be required to meet this requirement.
If we combine the destaging requirements and the read cache misses described above, your vSAN design may need 4 or 5 magnetic disks per disk group to satisfy your workload.
Striping Considerations
One of the VM Storage Policy settings is NumberOfDiskStripesPerObject. That allows you to set a stripe width on a VM’s VMDK object. While setting disk striping values can sometimes increase performance, that isn’t always the case.
As an example, if a given test is cache-friendly (e.g. most of the data is in cache), striping won’t impact performance significantly. As another example, if a given VMDK is striped across disks that are busy doing other things, not much performance is gained, and may actually be worse.
Guest File Systems Considerations
Many customers have reported significant differences in performance between different guest file systems and their settings; for example, Windows NTFS and Linux. If you are not getting the performance you expect, consider investigating whether it could be a guest OS file system issue.
Performance during Failure and Rebuild
When vSAN is rebuilding one or more components, application performance can be impacted. For this reason, always check to make sure that vSAN is fully rebuilt and that there are no underlying issues prior to evaluating performance. Verify there are no rebuilds occurring before testing with the Resyncing objects dashboard. The dashboard can be accessed by navigating to [vSAN Cluster] > Monitor > vSAN > Resyncing objects as depicted below:
.png)
Performance Testing Using HCIBench
HCIbench aims to simplify and accelerate customer Proof of Concept (POC) performance testing in a consistent and controlled way. The tool fully automates the end-to-end process of deploying test VMs, coordinating workload runs, aggregating test results, and collecting necessary data for troubleshooting purposes. Evaluators choose the profiles they are interested in and HCIbench does the rest quickly and easily.
This section provides an overview and recommendations for successfully using HCIbench. For complete documentation, refer to the HCIbench User Guide.
Where to Get HCIbench
HCIbench and complete documentation can be downloaded from https://labs.vmware.com/flings/hcibench
This tool is provided free of charge and with no restrictions. Support will be provided solely on a best-effort basis as time and resources allow, by the VMware vSAN Community Forum.
Deploying HCIbench
Step 1 – Deploy the OVA
Firstly, download and deploy the HCIbench appliance. The process for deploying the HCIbench appliance is no different from deploying any other appliance in vSphere platform.
Step 2 – HCIbench Configuration
After deployment, navigate to http://<Controller VM IP>:8080/ to configure the appliance
There are three main sections to consider:
- vSAN cluster and host information
- Guest VM Specification
- Workload Definitions
For detailed steps on configuring and using HCIbench refer to the HCIbench User Guide.
Considerations for Defining Test Workloads
Either FIO or vdbench can be chosen as the testing engine. Here, we recommend using FIO, due to the exhaustive list of parameters that can be set. Pre-defined parameter files can be uploaded to HCIbench to be executed (a wider variety of options are available, such as different read/write block sizes outside of what can be defined within the configuration page, for a full list of FIO options, consult the FIO documentation, e.g. https://www.mankier.com/1/fio)
Although 'Easy Run' can be selected, we recommend explicitly defining a workload pattern to ensure that tests are tailored to the performance requirements of the PoC. Below, we walk through some of the important considerations.
Working set
Defining the appropriate working set is one of the most important factors for correctly running performance tests and obtaining accurate results. For the best performance, a virtual machine’s working set should be mostly in the cache. Care should be taken when sizing your vSAN caching tier to account for all of the virtual machines’ working sets residing in the cache. A general rule of thumb, in hybrid environments, is to size cache as 10% of your consumed virtual machine storage (not including replica objects). While this is adequate for most workloads, understanding your workload’s working set before sizing is a useful exercise. For all-flash environments, consult the table below
.png)
The following process is an example of sizing an appropriate working set for performance testing with HCIbench:
Consider a four-node cluster with one 400GB SSD per node. This gives the cluster a total cache size of 1.6TB. For a Hybrid cluster, the total cache available in vSAN is split 70% for read cache and 30% for write cache. This gives the cluster in our example 1120GB of available read cache and 480GB of available write cache. In order to correctly fit the HCIbench within the available cache, the total capacity of all VMDKs used for I/O testing should not exceed 1,120GB. For All-Flash, 100% of the cache is allocated for writes (thus the total capacity of all VMDKs is 1.6TB). We create a test scenario with four VMs per host, each VM having 5 X 10GB VMDKs, resulting in a total size of 800GB -- this will allow the test working set to fit within the cache.
The number and size of the data disk, along with the number of threads should be adjusted so that the product of the test set is less than the total size of the cache tier.
Thus: # of VMs x # of Data Disk x Size of Data Disk x # of Threads < Size of Cache Disk x Disk Groups per Host x Number of Hosts x [70% read cache (hybrid)]
For example:
4 VMs x 5 Data Disks x 10GB x 1 Thread = 800GB,
400GB SSDs x 70% x 1 Disk Group per Host x 4 Hosts = 1,120GB
Therefore, 800GB working set size is less than the 1,120GB read cache in cluster, i.e there is more read cache available than our defined working set size. Therefore this is an acceptable working set size.
Note: the maximum working set size per cache disk is 600GB. If your cache disk size is greater than this, use this value in the above calculations.
Sequential workloads versus random workloads
Before doing performance tests, it is important to understand the performance characteristics of the production workload to be tested: different applications have different performance characteristics. Understanding these characteristics is crucial to successful performance testing. When it is not possible to test with the actual application or application-specific testing tool it is important to design a test that matches the production workload as closely as possible. Different workload types will perform differently on vSAN.
- Sustained sequential write workloads (such as VM cloning operations) run on vSAN will simply fill the cache and future writes will need to wait for the cache to be destaged to the capacity tier before more I/Os can be written to the cache. Thus, in a hybrid environment, performance will be a reflection of the spinning disk(s) and not of flash. The same is true for sustained sequential reads. If the block is not in the cache, it will have to be fetched from the spinning disk. Mixed workloads will benefit more from vSAN’s caching design.
- HCIbench allows you to change the percentage read and the percentage random parameters; a good starting point here is to set the percentage read parameter to 70% and the percentage random parameter to 30%.
Prepare Virtual Disk Before Testing
To achieve a 'clean' performance run, the disks should be wiped before use. To achieve this, select a value for the 'Prepare Virtual Disk Before Testing'. This option will either zero or randomize the data (depending on the selection) on the disks for each VM being used in the test, helping to alleviate a first write penalty during the performance testing phase. We recommend that the disks are randomized if using the Deduplication & Compression feature.
Warm up period
As a best practice, performance tests should include at least a 15-minute warm-up period. Also, keep in mind that the longer testing runs the more accurate the results will be. In addition to the cache warming period,
Testing Runtime
HCIbench tests should be configured for at least an hour to observe the effects of destaging from the cache to the capacity tier.
Blocksize
It is important to match the block size of the test to that of the workload being simulated, as this will directly affect the throughput and latency of the cluster. Therefore, it is paramount that this information be gathered before the start of the tests (for instance, from a Live Optics assessment).
Results
After testing is completed, you can view the results at http://<Controller VM IP>:8080/results in a web browser. A summary file of the tests will be present inside the subdirectory corresponding to the test run. To export the results to a ZIP file, click on the 'save result' option on the HCIbench configuration page (and wait for the ZIP file to be fully populated).
As HCIbench is integrated with the vSAN performance service, the performance data can also be reviewed within the vCenter HTML5 UI, under [vSAN cluster] > Monitor > vSAN > Performance.
Testing Hardware Failures
Understanding Expected Behaviours
When conducting any kind failure testing, it is important to consider the expected outcome before the test is conducted. With each test described in this section, you should first read the preceding description to first understand how the test will affect the system.
Important: Test one Thing at a Time
By default, VMs deployed on vSAN inherit the default storage policy, with the ability to tolerate one failure. If you do not wait for the first failure to be resolved, and then try to test another failure, you will have introduced two failures to the cluster. The VMs will not be able to tolerate the second failure and will become inaccessible.
VM Behavior when Multiple Failures Encountered
Previously we discussed VM operational states and availability. To recap, a VM remains accessible when the full mirror copy of the objects are available, as well as greater than 50% of the components that make up the VM; the witness components are there to assist with the latter requirement.
Let’s talk a little about VM behavior when there are more failures in the cluster than the NumberOfFailuresToTolerate setting in the policy associated with the VM.
VM Powered on and VM Home Namespace Object Goes Inaccessible
If a running VM has its VM Home Namespace object go inaccessible due to failures in the cluster, a number of different things may happen. Once the VM is powered off, it will be marked "inaccessible" in the vSphere web client UI. There can also be other side effects, such as the VM getting renamed in the UI to its “.vmx” path rather than VM name, or the VM being marked "orphaned".
VM Powered on and Disk Object is inaccessible
If a running VM has one of its disk objects become inaccessible, the VM will keep running, but its VMDK’s I/O is stalled. Typically, the Guest OS will eventually time out I/O. Some operating systems may crash when this occurs. Other operating systems, for example, some Linux distributions, may downgrade the filesystems on the impacted VMDK to read-only. The Guest OS behavior and even the VM behavior is not vSAN specific. It can also be seen on VMs running on traditional storage when the ESXi host suffers an APD(All Paths Down).
Once the VM becomes accessible again, the status should resolve, and things go back to normal. Of course, data remains intact during these scenarios.
What happens when a server fails or is rebooted?
A host failure can occur in a number of ways. It could be a crash, or it could be a network issue (which is discussed in more detail in the next section). However, it could also be something as simple as a reboot, and that the host will be back online when the reboot process completes. Once again, vSAN needs to be able to handle all of these events.
If there are active components of an object residing on the host that is detected to be failed (due to any of the stated reasons) then those components are marked as ABSENT. I/O flow to the object is restored within 5-7 seconds by removing the ABSENT component from the active set of components in the object.
The ABSENT state is chosen rather than the DEGRADED state because in many cases a host failure is a temporary condition. A host might be configured to auto-reboot after a crash, or the host’s power cable was inadvertently removed, but plugged back in immediately. vSAN is designed to allow enough time for a host to reboot before starting to rebuild objects on other hosts so as not to waste resources. Because vSAN cannot tell if this is a host failure, a network disconnect or a host reboot, the 60-minute timer is once again started. If the timer expires, and the host has not rejoined the cluster, a rebuild of components on the remaining hosts in the cluster commences.
If a host fails or is rebooted, this event will trigger a "Host connection and power state" alarm, and if vSphere HA is enabled on the cluster. It will also cause a" vSphere HA host status" alarm and a “Host cannot communicate with all other nodes in the vSAN Enabled Cluster” message.
If NumberOfFailuresToTolerate=1 or higher in the VM Storage Policy, and an ESXi host goes down, VMs not running on the failed host continue to run as normal. If any VMs with that policy were running on the failed host, they will get restarted on one of the other ESXi hosts in the cluster by vSphere HA, as long as it is configured on the cluster.
Caution: If VMs are configured in such a way as to not tolerate failures, ( NumberOfFailuresToTolerate=0 ), a VM that has components on the failing host will become inaccessible through the vSphere web client UI.
Simulating Failure Scenarios
It can be useful to run simulations on the loss of a particular host or disk, to see the effects of planned maintenance or hardware failure. The Data Migration Pre-Check feature can be used to check object availability for any given host or disk. These can be run at any time without affecting VM traffic.
Loss of a Host
Navigate to:
[vSAN Cluster] → Monitor → vSAN → Data Migration Pre-check
.png)
From here, you can select the host to run the simulations on. After a host is selected, the pre-check can be run against three available options, i.e., Full data migration, Ensure accessibility, No data migration:
.png)
Select the desired option and click the Pre-Check button. This gives us the results of the simulation. From the results, three sections are shown, i.e.: Object Compliance and Accessibility, Cluster Capacity and Predicted Health.
The Object Compliance and Accessibility view show how the individual objects will be affected:
.png)
Cluster Capacity shows how the capacity of the other hosts will be affected. Below we see the effects of the 'Full data migration' option:
.png)
Predicted Health shows how the health of the cluster will be affected:
.png)
Loss of a Disk
Navigate to:
[vSAN Cluster] → Configure → vSAN → Disk Management
From here, select a host or disk group to bring up a list of disks. Simulations can then be run on a selected disk or the entire disk group:
.png)
Once the Pre-Check Data Migration button option is selected, we can run different simulations to see how the objects on the disk are affected. Again, the options are Full data migration, Ensure accessibility (default) and No data migration:
.png)
Selecting 'Full data migration' will run a check to ensure that there is sufficient capacity on the other hosts:
.png)
Host Failures
Simulate Host Failure without vSphere HA
Without vSphere HA, any virtual machines running on the host that fails will not be automatically started elsewhere in the cluster, even though the storage backing the virtual machine in question is unaffected.
Let’s take an example where a VM is running on a host (10.159.16.118):
.jpg)
It would also be a good test if this VM also had components located on the local storage of this host. However, it does not matter as the test will still highlight the benefits of vSphere HA.
Next, the host, namely 10.159.16.118 is rebooted. As expected, the host is not responding in vCenter, and the VM becomes disconnected. The VM will remain in a disconnected state until the ESXi host has fully rebooted, as there is no vSphere HA enabled on the cluster, so the VM cannot be restarted on another host in the cluster.
.png)
If you now examine the policies of the VM, you will see that it is non-compliant. This VM should be able to tolerate one failure but due to the failure currently in the cluster (i.e. the missing ESXi host that is rebooting) this VM cannot tolerate another failure, thus it is non-compliant with its policy.
What can be deduced from this is that, not only was the VM’s compute running on the host which was rebooted, but that it also had some components residing on the storage of the host that was rebooted. We can see the effects of this on the other VMs in the cluster, that show reduced availability:
.png)
Once the ESXi host has rebooted, we see that the VM is no longer disconnected but left in a powered off state.
.png)
If the physical disk placement is examined, we can clearly see that the storage on the host that was rebooted, i.e. 10.159.16.118, was used to store components belonging to the VM.
.png)
Simulate Host Failure With vSphere HA
Let’s now repeat the same scenario, but with vSphere HA enabled on the cluster. First, power on the VM from the last test.
Next, navigate to [vSAN cluster] > Configure > Services > vSphere Availability . vSphere HA is turned off currently.
.png)
Click on the EDIT button to enable vSphere HA. When the wizard pops up, toggle the vSphere HA option as shown below, then click OK.
.png)
Similarly, enable DRS under Services > vSphere DRS .
This will launch a number of tasks on each node in the cluster. These can be monitored via the "Recent Tasks" view near the bottom. When the configuring of vSphere HA tasks are complete, select [vSAN cluster] > Summary and expand the vSphere HA window and ensure it is configured and monitoring. The cluster should now have vSAN, DRS and vSphere HA enabled.
.png)
Verify the host the test VM is residing on. Now repeat the same test as before by rebooting the host. Examine the differences with vSphere HA enabled.
.png)
On this occasion, a number of HA related events should be displayed on the "Summary" tab of the host being rebooted (you may need to refresh the UI to see these):

This time, rather than the VM becoming disconnected for the duration of the host reboot like was seen in the last test, the VM is instead restarted on another host, in this case, 10.159.16.115:
.png)
Earlier we saw that there were some components belonging to the objects of this VM residing a disk of the host that was rebooted. These components now show up as “Absent” under [vSAN Cluster] > Monitor > vSAN > Virtual Objects > View Placement Details, as shown below:
.png)
Once the ESXi host completes rebooting, assuming it is back within 60 minutes, these components will be rediscovered, resynchronized and placed back in an "Active" state.
Should the host be disconnected for longer than 60 minutes (the CLOMD timeout delay default value), the “Absent” components will be rebuilt elsewhere in the cluster.
Unexpected Removal of Drive From vSAN Host
When a drive contributing storage to vSAN is removed from an ESXi host without decommissioning, all the vSAN components residing on the disk go ABSENT and are inaccessible.
The ABSENT state is chosen over DEGRADED because vSAN knows the disk is not lost, but just removed. If the disk is placed back in the server before a 60-minute timeout, no harm is done and vSAN syncs it back up. In this scenario, vSAN is back up with full redundancy without wasting resources on an expensive rebuild task.
Expected Behaviors
- If the VM has a policy that includes NumberOfFailuresToTolerate=1 or greater, the VM’s objects will still be accessible from another ESXi host in the vSAN Cluster.
- The disk state is marked as ABSENT and can be verified via vSphere client UI.
- At this point, all in-flight I/O is halted while vSAN reevaluates the availability of the object (e.g. VM Home Namespace or VMDK) without the failed component as part of the active set of components.
- If vSAN concludes that the object is still available (based on a full mirror copy and greater than 50% of the components being available), all in-flight I/O is restarted.
- The typical time from physical removal of the disk, vSAN processing this event, marking the component ABSENT, halting and restoring I/O flow is approximately 5-7 seconds.
- If the same disk is placed back on the same host within 60 minutes, no new components will be rebuilt.
- If 60 minutes pass and the original disk has not been reinserted in the host, components on the removed disk will be built elsewhere in the cluster (if capacity is available) including any newly inserted disks claimed by vSAN.
- If the VM Storage Policy has NumberOfFailuresToTolerate=0, the VMDK will be inaccessible if one of the VMDK components (think one component of a stripe or a full mirror) resides on the removed disk. To restore the VMDK, the same disk has to be placed back in the ESXi host. There is no other option for recovering the VMDK.
SSD is Pulled Unexpectedly from ESXi Host
When a solid-state disk drive is pulled without decommissioning it, all the vSAN components residing in that disk group will go ABSENT and are inaccessible. In other words, if an SSD is removed, it will appear as a removal of the SSD as well as all associated magnetic disks backing the SSD from a vSAN perspective.
Expected Behaviors
- If the VM has a policy that includes NumberOfFailuresToTolerate=1 or greater, the VM’s objects will still be accessible.
- Disk group and the disks under the disk group states will be marked as ABSENT and can be verified via the vSphere web client UI.
- At this point, all in-flight I/O is halted while vSAN reevaluates the availability of the objects without the failed component(s) as part of the active set of components.
- If vSAN concludes that the object is still available (based on a full mirror copy and greater than 50% of components being available), all in-flight I/O is restarted.
- The typical time from physical removal of the disk, vSAN processing this event, marking the components ABSENT, halting and restoring I/O flow is approximately 5-7 seconds.
- When the same SSD is placed back on the same host within 60 minutes, no new objects will be re-built.
- When the timeout expires (default 60 minutes), components on the impacted disk group will be rebuilt elsewhere in the cluster, providing enough capacity and is available.
- If the VM Storage Policy has NumberOfFailuresToTolerate=0, the VMDK will be inaccessible if one of the VMDK components (think one component of a stripe or a full mirror) exists on disk group whom the pulled SSD belongs to. To restore the VMDK, the same SSD has to be placed back in the ESXi host. There is no option to recover the VMDK.
What Happens When a Disk Fails?
If a disk drive has an unrecoverable error, vSAN marks the disk as DEGRADED as the failure is permanent.
Expected Behaviors
- If the VM has a policy that includes NumberOfFailuresToTolerate=1 or greater, the VM’s objects will still be accessible.
- The disk state is marked as DEGRADED and can be verified via vSphere web client UI.
- At this point, all in-flight I/O is halted while vSAN reevaluates the availability of the object without the failed component as part of the active set of components.
- If vSAN concludes that the object is still available (based on a full mirror copy and greater than 50% of components being available), all in-flight I/O is restarted.
- The typical time from physical removal of the drive, vSAN processing this event, marking the component DEGRADED, halting and restoring I/O flow is approximately 5-7 seconds.
- vSAN now looks for any hosts and disks that can satisfy the object requirements. This includes adequate free disk space and placement rules (e.g. 2 mirrors may not share the same host). If such resources are found, vSAN will create new components on there and start the recovery process immediately.
- If the VM Storage Policy has NumberOfFailuresToTolerate=0, the VMDK will be inaccessible if one of the VMDK components (think one component of a stripe) exists on the pulled disk. This will require a restore of the VM from a known good backup.
What Happens When an SSD Fails?
An SSD failure follows a similar sequence of events to that of a disk failure with one major difference; vSAN will mark the entire disk group as DEGRADED. vSAN marks the SSD and all disks in the disk group as DEGRADED as the failure is permanent (disk is offline, no longer visible, and others).
Expected Behaviors
- If the VM has a policy that includes NumberOfFailuresToTolerate=1 or greater, the VM’s objects will still be accessible from another ESXi host in the vSAN cluster.
- Disk group and the disks under the disk group states will be marked as DEGRADED and can be verified via the vSphere web client UI.
- At this point, all in-flight I/O is halted while vSAN reevaluates the availability of the objects without the failed component(s) as part of the active set of components.
- If vSAN concludes that the object is still available (based on available full mirror copy and witness), all in-flight I/O is restarted.
- The typical time from physical removal of the drive, vSAN processing this event, marking the component DEGRADED, halting and restoring I/O flow is approximately 5-7 seconds.
- vSAN now looks for any hosts and disks that can satisfy the object requirements. This includes adequate free SSD and disk space and placement rules (e.g. 2 mirrors may not share the same hosts). If such resources are found, vSAN will create new components on there and start the recovery process immediately.
- If the VM Storage Policy has NumberOfFailuresToTolerate=0, the VMDK will be inaccessible if one of the VMDK components (think one component of a stripe) exists on disk group whom the pulled SSD belongs to. There is no option to recover the VMDK. This may require a restore of the VM from a known good backup.
Warning: Test one thing at a time during the following POC steps. Failure to resolve the previous error before introducing the next error will introduce multiple failures into vSAN which it may not be equipped to deal with, based on the NumberOfFailuresToTolerate setting, which is set to 1 by default.
vSAN Disk Fault Injection Script for POC Failure Testing
A python script to help with POC disk failure testing is available on all ESXi hosts. The script is called vsanDiskFaultInjection.pyc and can be found on the ESXi hosts in the directory /usr/lib/vmware/vsan/bin. To display the usage, run the following command:
[root@cs-ie-h01:/usr/lib/vmware/vsan/bin] python ./vsanDiskFaultInjection.pyc -hUsage:
injectError.py -t -r error_durationSecs -d deviceName injectError.py -p -d deviceName injectError.py -z -d deviceName injectError.py -c -d deviceName
Options:
-h, --help show this help message and exit -u Inject hot unplug -t Inject transient error -p Inject permanent error -z Inject health error -c Clear injected error -r ERRORDURATION Transient error duration in seconds -d DEVICENAME, --deviceName=DEVICENAME
[root@cs-ie-h01:/usr/lib/vmware/vsan/bin]Warning: This command should only be used in pre-production environments during a POC. It should not be used in production environments. Using this command to mark disks as failed can have a catastrophic effect on a vSAN cluster.
Readers should also note that this tool provides the ability to do “hot unplug” of drives. This is an alternative way of creating a similar type of condition. However, in this POC guide, this script is only being used to inject permanent errors.
Pull Magnetic Disk/Capacity Tier SSD and Replace before Timeout Expires
In this first example, we shall remove a disk from the host using the vsanDiskFaultInjection.pyc python script rather than physically removing it from the host.
It should be noted that the same tests can be run by simply removing the disk from the host. If physical access to the host is convenient, literally pulling a disk would test exact physical conditions as opposed to emulating it within the software.
Also, note that not all I/O controllers support hot unplugging drives. Check the vSAN Compatibility Guide to see if your controller model supports the hot unplug feature.
We will then examine the effect this operation has on vSAN, and virtual machines running on vSAN. We shall then replace the component before the CLOMD timeout delay expires (default 60 minutes), which will mean that no rebuilding activity will occur during this test.
Pick a running VM. Next, navigate to [vSAN Cluster] > Monitor > Virtual Objects and find the running VM from the list shown and select a Hard Disk.
.png)
Select View Placement Details:
.png)
Identify a Component object. The column that we are most interested in is HDD Disk Name, as it contains the NAA SCSI identifier of the disk. The objective is to remove one of these disks from the host (other columns may be hidden by right-clicking on them).
.png)
From the figure above, let us say that we wish to remove the disk containing the component residing on 10.159.16.117. That component resides on physical disk with an NAA ID string of naa.5000cca08000d99c Make a note of your NAA ID string. Next, SSH into the host with the disk to pull. Inject a hot unplug event using the vsanDiskFaultInjection.pyc python script:
[root@10.159.16.117:~] python /usr/lib/vmware/vsan/bin/vsanDiskFaultInjection.pyc –u –d naa.5000cca08000d99c Injecting hot unplug on device vmhba2:C0:T5:L0 vsish -e set /reliability/vmkstress/ScsiPathInjectError 0x1 vsish -e set /storage/scsifw/paths/vmhba2:C0:T5:L0/injectError 0x004C0400000002
Let’s now check out the VM’s objects and components and as expected, the component that resided on that disk on host 10.159.16.117 shows up as absent:
.png)
To put the disk drive back in the host, simply rescan the host for new disks. Navigate to the [vSAN host] > Configure > Storage > Storage Adapters and click the Rescan Storage button.
.png)
Look at the list of storage devices for the NAA ID that was removed. If for some reason, the disk doesn’t return after refreshing the screen, try rescanning the host again. If it still doesn’t appear, reboot the ESXi host. Once the NAA ID is back, clear any hot unplug flags set previously with the –c option:
[root@10.159.16.117:~] python /usr/lib/vmware/vsan/bin/vsanDiskFaultInjection.pyc –c –d naa.5000cca08000d99c Clearing errors on device vmhba2:C0:T5:L0 vsish -e set /storage/scsifw/paths/vmhba2:C0:T5:L0/injectError 0x00000 vsish -e set /reliability/vmkstress/ScsiPathInjectError 0x00000
Pull Magnetic Disk/Capacity Tier SSD and Do not Replace before Timeout Expires
In this example, we shall remove the magnetic disk from the host, once again using the vsanDiskFaultInjection.pyc script. However, this time we shall wait longer than 60 minutes before scanning the HBA for new disks. After 60 minutes, vSAN will rebuild the components on the missing disk elsewhere in the cluster.
The same process as before can now be repeated. However this time we will leave the disk drive out for more than 60 minutes and see the rebuild activity take place. Begin by identifying the disk on which the component resides.
.png)
[root@10.159.16.117:~] date Thu Apr 19 11:17:58 UTC 2018 [root@cs-ie-h01:~] python /usr/lib/vmware/vsan/bin/vsanDiskFaultInjection.pyc –u –d naa.5000cca08000d99c Injecting hot unplug on device vmhba2:C0:T5:L0 vsish -e set /reliability/vmkstress/ScsiPathInjectError 0x1 vsish -e set /storage/scsifw/paths/vmhba2:C0:T5:L0/injectError 0x004C0400000002
At this point, we can once again see that the component has gone "Absent ". After 60 minutes have elapsed, the component should now be rebuilt.
.png)
After 60 minutes have elapsed, the component should be rebuilt on a different disk in the cluster. That is what is observed. Note the component resides on a new disk (NAA id is different).
.png)
The removed disk can now be re-added by scanning the HBA:
Navigate to the [vSAN host] > Configure > Storage Adapters and click the Rescan Storage button.
Look at the list of storage devices for the NAA ID that was removed. If for some reason, the disk doesn’t return after refreshing the screen, try rescanning the host again. If it still doesn’t appear, reboot the ESXi host. Once the NAA ID is back, clear any hot unplug flags set previously with the –c option:
[root@10.159.16.117:~] python /usr/lib/vmware/vsan/bin/vsanDiskFaultInjection.pyc –c –d naa.5000cca08000d99c Clearing errors on device vmhba2:C0:T5:L0 vsish -e set /storage/scsifw/paths/vmhba2:C0:T5:L0/injectError 0x00000 vsish -e set /reliability/vmkstress/ScsiPathInjectError 0x00000
Pull Cache Tier SSD and Do Not Reinsert/Replace
For the purposes of this test, we shall remove an SSD from one of the disk groups in the cluster. Navigate to the [vSAN cluster] > Configure > vSAN > Disk Management . Select a disk group from the top window and identify its SSD in the bottom window. If All-Flash, make sure it’s the Flash device in the “Cache” Disk Role. Make a note of the SSD’s NAA ID string.
.png)
In the above screenshot, we have located an SSD on host 10.159.16.116 with an NAA ID string of naa.5000cca04eb0a4b4. Next, SSH into the host with the SSD to pull. Inject a hot unplug event using the vsanDiskFaultInjection.pyc python script:
[root@10.159.16.116:~] python /usr/lib/vmware/vsan/bin/vsanDiskFaultInjection.pyc -u -d naa.5000cca04eb0a4b4 Injecting hot unplug on device vmhba2:C0:T0:L0 vsish -e set /reliability/vmkstress/ScsiPathInjectError 0x1 vsish -e set /storage/scsifw/paths/vmhba2:C0:T0:L0/injectError 0x004C0400000002
Now we observe the impact that losing an SSD (flash device) has on the whole disk group.
.png)
And finally, let’s look at the components belonging to the virtual machine. This time, any components that were residing on that disk group are "Absent".
.png)
If you search all your VMs, you will see that each VM that had a component on the disk group 10.159.16.116 now has absent components. This is expected since an SSD failure impacts the whole of the disk group.
After 60 minutes have elapsed, new components should be rebuilt in place of the absent components. If you manage to refresh at the correct moment, you should be able to observe the additional components synchronizing with the existing data.
.png)
To complete this POC, re-add the SSD logical device back to the host by rescanning the HBA:
Navigate to the [vSAN host] > Configure > Storage > Storage Adapters and click the Rescan Storage button.
Look at the list of storage devices for the NAA ID of the SSD that was removed. If for some reason, the SSD doesn’t return after refreshing the screen, try rescanning the host again. If it still doesn’t appear, reboot the ESXi host. Once the NAA ID is back, clear any hot unplug flags set previously with the –c option:
[root@10.159.16.116:~] python /usr/lib/vmware/vsan/bin/vsanDiskFaultInjection.pyc –c –d naa.5000cca04eb0a4b4 Clearing errors on device vmhba2:C0:T0:L0 vsish -e set /storage/scsifw/paths/vmhba2:C0:T0:L0/injectError 0x00000 vsish -e set /reliability/vmkstress/ScsiPathInjectError 0x00000
Warning: If you delete an SSD drive that was marked as an SSD, and a logical RAID 0 device was rebuilt as part of this test, you may have to mark the drive as an SSD once more.
Checking Rebuild/Resync Status
To display details on resyncing components, navigate to [vSAN cluster] > Monitor > vSAN > Resyncing Objects.
.png)
Injecting a Disk Error
The first step is to select a host and then select a disk that is part of a disk group on that host. The –d DEVICENAME argument requires the SCSI identifier of the disk, typically the NAA id. You might also wish to verify that this disk does indeed contain VM components. This can be done by selecting the [vSAN Cluster] > Monitor > Virtual Objects > [select VMs/Objects] > View Placement Details > Group components by host placement button.
.png)
The objects on each host can also be seen via [vSAN Cluster] > Monitor > vSAN > Physical Disks and selecting a host:
.png)
The error can only be injected from the command line of the ESXi host. To display the NAA ids of the disks on the ESXi host, you will need to SSH to the ESXi host, log in as the root user, and run the following command:
[root@10.159.16.117:~] esxcli storage core device list| grep ^naa naa.5000cca08000ab0c naa.5000cca04eb03560 naa.5000cca08000848c naa.5000cca08000d99c naa.5000cca080001b14
Once a disk has been identified, and has been verified to be part of a disk group, and that the disk contains some virtual machine components, we can go ahead and inject the error as follows:
[root@10.159.16.117:~] python /usr/lib/vmware/vsan/bin/vsanDiskFaultInjection.pyc -p -d naa.5000cca08000848c Injecting permanent error on device vmhba2:C0:T2:L0 vsish -e set /reliability/vmkstress/ScsiPathInjectError 0x1 vsish -e set /storage/scsifw/paths/vmhba2:C0:T2:L0/injectError 0x03110300000002
Before too long, the disk should display an error and the disk group should enter an unhealthy state, as seen in [vSAN cluster] > Configure > vSAN > Disk Management
.png)
Notice that the disk group is in an "Unhealthy" state and the status of the disk is “Permanent disk failure”. This should place any components on the disk into a degraded state (which can be observed via the "Physical Placement" window, and initiate an immediate rebuild of components. Navigating to [vSAN cluster] > Monitor > vSAN > Resyncing Components should reveal the components resyncing.
.png)
Clear a Permanent Error
At this point, we can clear the error. We use the same script that was used to inject the error, but this time we provide a –c (clear) option:
[root@10.159.16.117:~] python /usr/lib/vmware/vsan/bin/vsanDiskFaultInjection.pyc -c -d naa.5000cca08000848c vsish -e get /reliability/vmkstress/ScsiPathInjectError vsish -e set /storage/scsifw/paths/vmhba2:C0:T2:L0/injectError 0x00000 vsish -e set /reliability/vmkstress/ScsiPathInjectError 0x00000
Note however that since the disk failed, it will have to be removed, and re-added from the disk group. This is very simple to do. Simply select the disk in the disk group, and remove it by clicking on the icon highlighted below.
.png)
This will display a pop-up window regarding which action to take regarding the components on the disk. You can choose to migrate the components or not. By default, it is shown as Evacuate all data to other hosts.
.png)
For the purposes of this POC, you can select the No data evacuation option as you are adding the disk back in the next step. When the disk has been removed and re-added, the disk group will return to a healthy state. That completes the disk failure test.
When Might a Rebuild of Components Not Occur?
There are a couple of reasons why a rebuild of components might not occur. Start by looking at vSAN Health Check UI [vSAN cluster] > Monitor > vSAN > Health for any alerts indicative of failures.
You could also check specifically for resource constraints or failures through RVC as described below.
Lack of Resources
Verify that there are enough resources to rebuild components before testing with the following RVC command:
- vsan.whatif_host_failures
Of course, if you are testing with a 3-node cluster, and you introduce a host failure, there will be no rebuilding of objects. Once again, if you have the resources to create a 4-node cluster, then this is a more desirable configuration for evaluating vSAN.
Underlying Failures
Another cause of a rebuild not occurring is due to an underlying failure already present in the cluster. Verify there are none before testing with the following RVC command:
- vsan.hosts_info
- vsan.check_state
- vsan.disks_stats
If these commands reveal underlying issues (ABSENT or DEGRADED components for example), rectify these first or you risk inducing multiple failures in the cluster, resulting in inaccessible virtual machines.
Air-Gapped Network Features
Air-gapped vSAN network design is built around the idea of redundant, yet completely isolated storage networks. It is used in conjunction with multiple vmknics tagged for vSAN traffic, while each vmknic is segregated on different subnets. There is physical and/or logical separation of network switches. A primary use case is to have two segregated uplink paths and non-routable VLANs to separate the IO data flow onto redundant data paths.
Note: This feature does not guarantee the load-balancing of network traffic between vmkernel ports. Its sole function is to tolerate link failure across redundant data paths.
Air-gapped vSAN Networking and Graphical Overview
The figure below shows all the vmnic uplinks per hosts, including mapped vmkernel ports that are completely separated by physical connectivity and have no communication across each data path. VMkernel ports are logically separated either by different IP segments and/or separate VLANs in different port groups.
.png)
Distributed switch configuration for the failure scenarios
With air-gapped network design, we need to place each of the two discrete IP subnets on a separate VLAN. With this in mind, we would need the two highlighted VLANs/port groups created in a standard vSwitch or distributed vSwitch as shown below before the failover testing.
.png)
Separating IP segments on different VLANs
The table below shows the detailed vmknic/portgroup settings to allow for two discrete IP subnets to reside on two separate VLANs (201 and 202). Notice each vmknic port group is configured with two uplinks and only one of which is set to active.
| VMkernel interface tagged for vSAN traffic | IP address segment and subnet mask | Port group name |
VLAN ID
|
Port group uplinks |
|---|---|---|---|---|
| vmk1 | 192.168. 201 .0 / 255.255.255.0 | VLAN-201-vSAN-1 | 201 | UPLINK 1 - Active UPLINK 2 - Unused |
| vmk2 | 192.168. 202 .0 / 255.255.255.0 | VLAN-202-vSAN-2 | 202 | UPLINK 1 - Unused UPLINK 2 - Active |
Failover test scenario using DVS portgroup uplink priority
Before we initiate a path failover, we need to generate some background workload to maintain a steady network flow through the two VMkernel adapters. You may choose your own workload tool or simply refer to the previous section to execute an HCIbench workload.
Using the functionality in DVS, we can simulate a physical switch failure or physical link down by moving an "Active" uplink for a port group to "Unused" as shown below. This affects all vmk ports that are assigned to the port group.
.png)
Expected outcome on vSAN IO traffic failover
Prior to vSAN 6.7, when a data path is down in air-gapped network topology, VM IO traffic could pause up to 120 seconds to complete the path failover while waiting for the TCP timeout signal. Starting in vSAN 6.7, failover time improves significantly to no more than 15 seconds as vSAN proactively monitors failed data path and takes corrective action as soon as a failure is detected.
Monitoring network traffic failover
To verify the traffic failover from one vmknic to another and capture the timeout window, we can start esxtop on each ESXi host and press "n" to actively monitor host network activities before and after a failure is introduced. The screenshot below illustrates that the data path through vmk2 is down when the "Unused" state is set for the corresponding uplink and "void" status is reported for that physical uplink. TCP packet flow has suspended on that vmknic as zeroes are reported under the Mb/s transmit (TX) and receive (RX) columns.
.png)
It is expected that vSAN health check reports failed pings on vmk2 as we set the vmnic1 uplink to "Unused".
.png)
To restore the failed data path after a failover test, modify the affected uplink from "Unused" back to "Active". Network traffic should be restored through both vmknics (though not necessarily load-balanced). This completes this section of the POC guide. Before moving on to other sections, remove vmk2 on each ESXi host (as the vmknic is also used for other purposes in Stretched Cluster testing in a later section), and perform a vSAN health check and ensure all tests pass.
vSAN Management Tasks
Common management task in vSAN and how to complete them.
Maintenance Mode
In this section, we shall look at a number of management tasks, such as the behavior when placing a host into maintenance mode, and the evacuation of a disk and a disk group from a host. We will also look at how to turn on and off the identifying LED's on a disk drive.
Putting a Host into Maintenance Mode
There are a number of options available when placing a host into maintenance mode. The first step is to identify a host that has a running VM, as well as components belonging to virtual machine objects.
Select the Summary tab of the virtual machine to verify which host it is running on.
.png)
Then select the [vSAN cluster] > Monitor > Virtual Objects, then select the appropriate VM (with all components) and click View Placement Details. Selecting Group components by host placement will show which hosts have been used. Verify that there are components also residing on the same host.
.png)
From the screenshots shown here, we can see that the VM selected is running on host 10.159.17.3 and also has components residing on that host. This is the host that we shall place into maintenance mode.
Right-click on the host, select Maintenance Mode from the drop-down menu, then select the option Enter Maintenance Mode as shown here.
.png)
There are three options displays when the maintenance mode is selected:
- Full data migration
- Ensure accessibility
- No data migration
.png)
When the default option of "Ensure accessibility" is chosen, a popup is displayed regarding migrating running virtual machines. Since this is a fully automated DRS cluster, the virtual machines should be automatically migrated.
.png)
After the host has entered maintenance mode, we can now examine the state of the components that were on the local storage of this host. What you should observe is that these components are now in an “Absent” state. However, the VM remains accessible as we chose the option “Ensure Accessibility” when entering maintenance mode.
.png)
The host can now be taken out of maintenance mode. Simply right-click on the host as before, select Maintenance Mode > Exit Maintenance Mode.
.png)
After exiting maintenance mode, the “Absent” component becomes "Active" once more. This is assuming that the host exited maintenance mode before the vsan.ClomdRepairDelay expires (default 60 minutes).
.png)
We shall now place the host into maintenance mode once more, but this time instead of Ensure accessibility, we shall choose Full data migration. This means that although components on the host in maintenance mode will no longer be available, those components will be rebuilt elsewhere in the cluster, implying that there is full availability of the virtual machine objects.
Note: This is only possible when NumberOfFailuresToTolerate = 1 and there are 4 or more hosts in the cluster. It is not possible with 3 hosts and NumberOfFailuresToTolerate = 1, as another host needs to be available to rebuild the components. This is true for higher values of NumberOfFailuresToTolerate also.
.png)
Now if the VM components are monitored, you will see that no components are placed in an “Absent” state, but rather they are rebuilt on the other hosts in the cluster. When the host enters maintenance mode, you will notice that all components of the virtual machines are "Active", but none resides on the host placed into maintenance mode.
.png)
Safeguards are in place such that warnings are shown when multiple hosts are placed into maintenance mode (MM) at the same time, or a host is about to enter MM while another host is already in MM or resync activity is in progress to avoid multiple unintended outages that may cause vSAN objects to become inaccessible. The screenshot below illustrates an example of the warnings if we attempt to place host 10.159.16.116 into MM, while 10.159.16.115 had already been in MM. Simply select CANCEL to abort the decommission operation..png)
Ensure that you exit maintenance mode of all the hosts to restore the cluster to a fully functional state. This completes this part of the POC.
Evacuate And Remove Disk
In this example, we show the ability to evacuate a disk prior to removing it from a disk group.
Navigate to [vSAN cluster] > Configure > vSAN > Disk Management, and select a disk group in one of the hosts as shown below. Then select one of the capacity disks from the disk group, also shown below. Note that the disk icon with the red X becomes visible. This is not visible if the cluster is in automatic mode.
.png)
Make a note of the devices in the disk group, as you will need these later to rebuild the disk group. There are a number of icons on this view of disk groups in vSAN. It is worth spending some time understanding what they mean. The following table should help to explain that.
.png) |
Add a disk to the selected disk group |
.png) |
See the expected result of the disk or disk group evacuation |
.png) |
Remove (and optionally evacuate data) from a disk in a disk group |
.png) |
Turn on the locator LED on the selected disk |
.png) |
Turn off the locator LED on the selected disk |
To continue with the option of removing a disk from a disk group and evacuating the data, click on the icon to remove a disk highlighted earlier. This pops up the following window, which gives you the option to Evacuate all data to other hosts (selected automatically). Click DELETE to continue:
.png)
When the operation completes, there should be one less disk in the disk group, but if you examine the components of your VMs, there should be none found to be in an “Absent” state. All components should be “Active”, and any that were originally on the disk that was evacuated should now be rebuilt elsewhere in the cluster.
Evacuate a Disk Group
Let’s repeat the previous task for the rest of the disk group. Instead of removing the original disk, let’s now remove the whole of the disk group. Make a note of the devices in the disk group, as you will need these later to rebuild the disk group.
.png)
As before, you are prompted as to whether or not you wish to evacuate the data from the disk group. The amount of data is also displayed, and the option is selected by default. Click DELETE to continue.
.png)
Once the evacuation process has completed, the disk group should no longer be visible in the "Disk Group" view.
.png)
Once again, if you examine the components of your VMs, there should be none found to be in an “Absent” state. All components should be “Active”, and any that were originally on the disk that was evacuated should now be rebuilt elsewhere in the cluster.
Add Disk Groups Back Again
At this point, we can recreate the deleted disk group. This was already covered in section 5.2 of this POC guide. Simply select the host that the disk group was removed from, and click on the icon to create a new disk group. Once more, select a flash device and the two magnetic disk devices that you previously noted were members of the disk group. Click CREATE to recreate the disk group.
.png)
Turning On and Off Disk LEDs
For turning on and off the disk locator LEDs, utility such as hpssacli is a necessity when using HP controllers. Refer to vendor documentation for information on how to locate and install this utility.
Note: This is not an issue for LSI controllers, and all necessary components are shipped with ESXi for these controllers.
The icons for turning on and off the disk locator LEDs are shown in section 10.2. To turn on a LED, select a disk in the disk group and then click on the icon highlighted below.
.png)
This will launch a task to “Turn on disk locator LEDs”. To see if the task was successful, go to the "Monitor" tab and check the "Events" view. If there is no error, the task was successful. At this point, you can also take a look at the data center and visually check if the LED of the disk in question is lit.
Once completed, the locator LED can be turned off by clicking on the “Turn off disk locator LEDs” as highlighted in the screenshot below. Once again, this can be visually checked in the data center if you wish.
.png)
This completes this section of the POC guide. Before moving on to other sections perform and final check and ensure that all tests pass.
VUM based controller firmware update
Updating controller firmware through VMware Update Manager
Starting from the vSAN 6.6 release, vSAN supported patching of controller firmware as part of the vSAN Configuration Assist feature. With vSphere 6.7 Update 1, this feature is further enhanced and integrated into VMware Update Manager(VUM) to create a component-based firmware baseline. The workflow mimics a typical vSphere build update done through VUM. In the following section, we walkthrough the steps required to download and install a Vendor firmware tool, followed by importing the specific firmware and updating a host with the firmware package.
Note: Prior to updating the firmware, validate the current firmware installed and the recommended version as per VMware Compatibility Guide for the specific controller.
- Navigate to vSAN cluster and click on Updates tab
- VUM Firmware engine prompts that it requires the hardware vendor's firmware tool, Click on Download vendor firmware tool
- Vendor firmware tool can be either downloaded from the Internet or uploaded manually, complete the wizard to finish installation of the vendor firmware tool
- Click on the baseline created Firmware update for vSAN Cluster and Import FirmwareFirmware packages can be imported directly from the internet if vCenter has external network connectivity or can be uploaded offline manually
- VUM verifies the file integrity and imports the firmware packages
- Click on Remediate => Update Firmware only, this ensures that the controller firmware is updated to the latest available and supported version
.png)
 Firmware packages can be imported directly from the internet if vCenter has external network connectivity or can be uploaded offline manually
Firmware packages can be imported directly from the internet if vCenter has external network connectivity or can be uploaded offline manually For additional validation, you can verify that the associated health check Controller firmware is VMware certified has passed. With 6.7 U 1, the health checks provide more granular detail, i.e. apart from checking if the component version is on the HCL or not, it also states if there is a newer version available.
Stretched Cluster Configuration
Basics of a vSAN stretched cluster configuration.
Stretched Cluster Design And Overview
A good working knowledge of how vSAN Stretched Cluster is designed and architected is assumed. Readers unfamiliar with the basics of vSAN Stretched Cluster are urged to review the relevant documentation before proceeding with this part of the proof-of-concept. Details on how to configure a vSAN Stretched Cluster are found in the vSAN Stretched Cluster Guide.
Stretched Cluster Network Topology
As per the vSAN Stretched Cluster Guide, a number of different network topologies are supported for vSAN Stretched Cluster. The network topology deployed in this lab environment is a full layer 3 stretched vSAN network. L3 IP routing is implemented for the vSAN network between data sites, and L3 IP routing is implemented for the vSAN network between data sites and the witness site. VMware also supports stretched L2 between the data sites. The VM network should be a stretched L2 between both data sites.
When it comes to designing stretched cluster topology, there are options to configure layer 2 (same subnet) or layer 3 (routed) connectivity between the three sites (2 active/active sites and a witness site) for different traffic types (i.e. vSAN data, witness, VM traffic) with/without Witness Traffic Separation (WTS) depending on the requirements. You may consider some of the common designs listed below. Options 1a and 1b are configurations without WTS. The only difference between them is whether L2 or L3 is deployed for vSAN data traffic. As option 2 utilizes WTS, that is the only difference compared to option 1a. For simplicity, all options use L2 for VM traffic.
In the next sections, we will cover configurations and failover scenarios using option 1a (without WTS) and option 2 (with WTS). During a POC, you may choose to test one or another, or both options if you wish.
For more information on network design best practices for stretched cluster, refer to the vSAN Stretched Cluster Guide.
Stretched Cluster Hosts
There are four ESXi hosts in this cluster, two ESXi hosts on data site A (the “preferred” site) and two hosts on data site B (the “secondary” site). There is one disk group per host. The witness host/appliance is deployed in a 3 rd remote data center. The configuration is referred to as 2+2+1.
.png)
VMs are deployed on both the “Preferred” and “Secondary” sites of the vSAN Stretched Cluster. VMs are running/active on both sites.
vSAN Stretched Cluster Diagram
Below is a diagram detailing the POC environment used for the Stretched Cluster testing.
.png)
- This configuration uses L3 IP routing for the vSAN network between all sites.
- Static routes are required to enable communication between sites.
- The vSAN network VLAN for the ESXi hosts on the preferred site is VLAN 4. The gateway is 172.4.0.1.
- The vSAN network VLAN for the ESXi hosts on the secondary site is VLAN 3. The gateway is 172.3.0.1.
- The vSAN network VLAN for the witness host on the witness site is VLAN 80.
- The VM network is stretched L2 between the data sites. This is VLAN 30. Since no VMs are run on the witness, there is no need to extend this network to the third site.
Stretched Cluster Network Configuration
As per the vSAN Stretched Cluster Guide, a number of different network topologies are supported for vSAN Stretched Cluster. The options below provide some of the different for stretched cluster network configuration.
Option 1a:
-
L3 for witness traffic (without Witness Traffic Separation)
-
L2 for vSAN data traffic between 2 data sites
-
L2 for VM traffic
.png)
Option 1b:
-
L3 for witness traffic (without WTS)
-
L3 for vSAN data traffic between 2 data sites
-
L2 for VM traffic
.png)
Option 2:
-
L3 for witness traffic with WTS
-
L2 for vSAN data traffic between 2 data sites
-
L2 for VM traffic
.png)
vSAN Stretched Cluster Topology And Configuration (Without WTS)
vSAN Stretched Cluster (without Witness Traffic Separation) Configuration
A good working knowledge of how vSAN Stretched Cluster is designed and architected is assumed. Readers unfamiliar with the basics of vSAN Stretched Cluster are urged to review the relevant documentation before proceeding with this part of the proof-of-concept. Details on how to configure a vSAN Stretched Cluster are found in the vSAN Stretched Cluster Guide.
Stretched Cluster Network Topology
As per the vSAN Stretched Cluster Guide, a number of different network topologies are supported for vSAN Stretched Cluster.
The network topology deployed in this lab environment for our POC test case is layer 2 between the vSAN data sites and L3 between data sites and witness. ESXi hosts and vCenter are in the same L2 subnet for this setup. The VM network should be a stretched L2 between both data sites as the unique IP used by the VM can remain unchanged in a failure scenario.
Stretched Cluster Hosts
There are four ESXi hosts in this cluster, two ESXi hosts on data site A (the “preferred” site) and two hosts on data site B (the “secondary” site). There is one disk group per host. The witness host/appliance is deployed in a 3 rd , remote data center. The configuration is referred to as 2+2+1.
.png)
.png)
VMs are deployed on both the “Preferred” and “Secondary” sites of the vSAN Stretched Cluster. VMs are running/active on both sites.
vSAN Stretched Cluster Diagram
Below is a diagram detailing the POC environment used for the Stretched Cluster testing with L2 across Preferred and Secondary data sites.
.png)
- This configuration uses L2 across data sites for vSAN data traffic, host management, and VM traffic. L3 IP routing is implemented between the witness site and the two data sites.
- Static routes are required to enable communication between data sites and witness appliance.
- The vSAN data network VLAN for the ESXi hosts on the preferred and secondary sites is VLAN 201. The gateway is 192.168.201.162.
- The vSAN network VLAN for the witness host on the witness site is VLAN 203. The gateway is 192.168 203.162
- The VM network is stretched L2 between the data sites. This is VLAN 106. Since no production VMs are run on the witness, there is no need to extend this network to the third site.
Preferred / Secondary Site Details
In vSAN Stretched Clusters, the “preferred” site simply means the site that the witness will ‘bind’ to in the event of an inter-site link failure between the data sites. Thus, this will be the site with the majority of VM components, so this will also be the site where all VMs will run when there is an inter-site link failure between data sites.
In this example, vSAN traffic is enabled on vmk1 on the hosts on the preferred site, which is using VLAN 201. For our failure scenarios, we create two DVS port groups and add the appropriate vmkernel port to each port group to test the failover behavior in a later stage.
.png)
.png)
Static routes need to be manually configured on these hosts. This is because the default gateway is on the management network, and if the preferred site hosts tried to communicate to the secondary site hosts, the traffic would be routed via the default gateway and thus via the management network. Since the management network and the vSAN network are entirely isolated, there would be no route.
L3 routing between vSAN data sites and Witness host requires an additional static route. While default gateway is used for the Management Network on vmk0, vmk1 has no knowledge of subnet 192.168.203.0, which needs to be added manually.
.png)
Commands to Add Static Routes
The command to add static routes is as follows:
esxcli network ip route ipv4 add -g LOCAL-GATEWAY -n REMOTE-NETWORK
To add a static route from a preferred host to the witness host in this POC:
esxcli network ip route ipv4 add -g 192.168.201.162 -n 192.168.203.0/24
Note: Prior to vSAN version 6.6, multicast is required between the data sites but not to the witness site. If L3 is used between the data sites, multicast routing is also required. With the advent of vSAN 6.6, multicast is no longer needed.
Witness Site details
The witness site only contains a single host for the Stretched Cluster, and the only VM objects stored on this host are “witness” objects. No data components are stored on the witness host. In this POC, we are using the witness appliance, which is an “ESXi host running in a VM”. If you wish to use the witness appliance, it should be downloaded from VMware. This is because it is preconfigured with various settings, and also comes with a preinstalled license. Note that this download requires a login to My VMware.
Alternatively, customers can use a physical ESXi host for the witness.
While two VMkernel adapters can be deployed on the Witness Appliance (vmk0 for Management and vmk1 for vSAN traffic), it is also supported to tag both vSAN and Management traffic on a single VMkernel adapter (vmk0), as we use in this case, vSAN traffic would need to be disabled on vmk1, since only one vmk has vSAN traffic enabled.
.png)
.png)
Once again, static routes should be manually configured on vSAN vmk0 to route to “Preferred site” and “Secondary Site" (VLAN 201). The image below shows the witness host routing table with static routes to remote sites.
.png)
Commands to Add Static Routes
The following command to add static routes is as follows:
esxcli network ip route ipv4 add -g LOCAL-GATEWAY -n REMOTE-NETWORK
To add a static route from the witness host to hosts on the preferred and secondary sites in this POC:
esxcli network ip route ipv4 add -g 192.168.203.162 -n 192.168.201.0/24
Note: Witness Appliance is a nested ESXi host and requires the same treatment as a standard ESXi host (i.e, patch updates). Keep all ESXi hosts in a vSAN cluster at the same update level, including the Witness appliance.
vSphere HA Settings
vSphere HA plays a critical part in Stretched Cluster. HA is required to restart virtual machines on other hosts and even the other site depending on the different failures that may occur in the cluster. The following section covers the recommended settings for vSphere HA when configuring it in a Stretched Cluster environment.
Response to Host Isolation
The recommendation is to “Power off and restart VMs” on isolation, as shown below. In cases where the virtual machine can no longer access the majority of its object components, it may not be possible to shut down the guest OS running in the virtual machine. Therefore, the “Power off and restart VMs” option is recommended.
.png)
Admission Control
If a full site fails, the desire is to have all virtual machines run on the remaining site. To allow a single data site to run all virtual machines if the other data site fails, the recommendation is to set Admission Control to 50% for CPU and Memory as shown below.
.png)
Advanced Settings
The default isolation address uses the default gateway of the management network. This will not be useful in a vSAN Stretched Cluster when the vSAN network is broken. Therefore the default isolation response address should be turned off. This is done via the advanced setting das.usedefaultisolationaddress to false.
To deal with failures occurring on the vSAN network, VMware recommends setting at least one isolation address, which is local to each of the data sites. In this POC, we only use Stretched L2 on VLAN 201, which is reachable from the hosts on the preferred and secondary sites. Use advanced settings das.isolationaddress0 to set the isolation address for the IP gateway address to reach the witness host.
.png)
- Since 6.5 there is no need for VM anti-affinity rules or VM to host affinity rules in HA
These advanced settings are added in the Advanced Options > Configuration Parameter section of the vSphere HA UI. The other advanced settings get filled in automatically based on additional configuration steps. There is no need to add them manually.
VM Host Affinity Groups
The next step is to configure VM/Host affinity groups. This allows administrators to automatically place a virtual machine on a particular site when it is powered on. In the event of a failure, the virtual machine will remain on the same site, but placed on a different host. The virtual machine will be restarted on the remote site only when there is a catastrophic failure or a significant resource shortage.
To configure VM/Host affinity groups, the first step is to add hosts to the host groups. In this example, the Host Groups are named Preferred and Secondary, as shown below.
.png)
.png)
The next step is to add the virtual machines to the host groups. Note that these virtual machines must be created in advance.
.png)
Note that these VM/Host affinity rules are “should” rules and not “must” rules. “Should” rules mean that every attempt will be made to adhere to the affinity rules. However, if this is not possible (due lack of resources), the other site will be used for hosting the virtual machine.
Also, note that the vSphere HA rule setting is set to “should”. This means that if there is a catastrophic failure on the site to which the VM has an affinity, HA will restart the virtual machine on the other site. If this was a “must” rule, HA would not start the VM on the other site.
.png)
The same settings are necessary on both the primary VM/Host group and the secondary VM/Host group.
DRS Settings
In this POC, the partially automated mode has been chosen. However, this could be set to Fully Automated if customers wish but note that it should be changed back to partially automated when a full site failure occurs. This is to avoid failback of VMs occurring while rebuild activity is still taking place. More on this later.
.png)
vSAN Stretched Cluster Local Failure Protection
In vSAN 6.6, we build on resiliency by including local failure protection, which provides storage redundancy within each site and across sites. Local failure protection is achieved by implementing local RAID-1 mirroring or RAID-5/6 erasure coding within each site. This means that we can protect the objects against failures within a site, for example, if there is a host failure on site 1, vSAN can self-heal within site 1 without having to go to site 2 if properly configured.
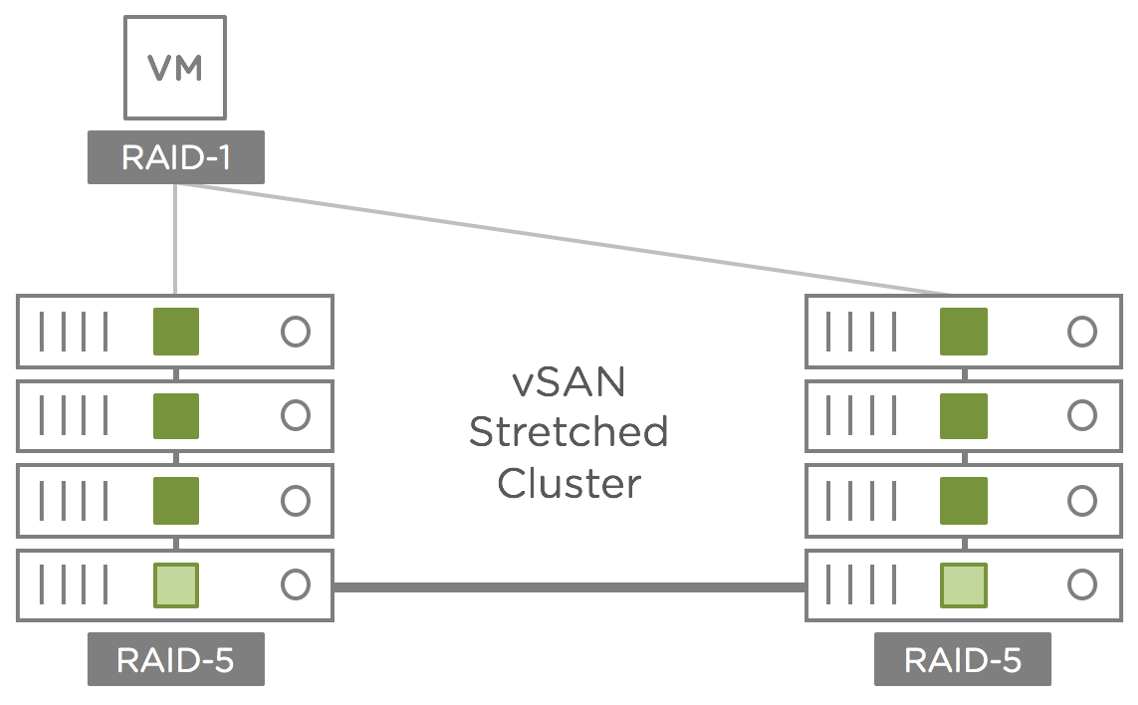
Local Failure Protection in vSAN 6.6 is configured and managed through a storage policy in the vSphere Web Client. The figure below shows rules in a storage policy that is part of an all-flash stretched cluster configuration. The "Site disaster tolerance" is set to Dual site mirroring (stretched cluster), which instructs vSAN to mirror data across the two main sites of the stretched cluster. The "Failures to tolerate" specifies how data is protected within the site. In the example storage policy below, 1 failure - RAID-5 (Erasure Coding) is used, which can tolerate the loss of a host within the site.
.png)
Local failure protection within a stretched cluster further improves the resiliency of the cluster to minimize unplanned downtime. This feature also reduces or eliminates cross-site traffic in cases where components need to be resynchronized or rebuilt. vSAN lowers the total cost of ownership of a stretched cluster solution as there is no need to purchase additional hardware or software to achieve this level of resiliency.
vSAN Stretched Cluster Site Affinity
New in vSAN 6.6 flexibility improvements of storage policy-based management for stretched clusters have been made by introducing the “Affinity” rule. You can specify a single site to locate VM objects in cases where cross-site redundancy is not necessary. Common examples include applications that have built-in replication or redundancy such as Microsoft Active Directory and Oracle Real Application Clusters (RAC). This capability reduces costs by minimizing the storage and network resources used by these workloads.
Site affinity is easy to configure and manage using storage policy-based management. A storage policy is created and the Affinity rule is added to specify the site where a VM’s objects will be stored using one of these "Site disaster tolerance" options: None - keep data on Preferred (stretched cluster) or None - keep data on Non-preferred (stretched cluster).
.png)
vSAN Stretched Cluster Preferred Site Override
Preferred and secondary sites are defined during cluster creation. If it is desired to switch the roles between the two data sites, you can navigate to [vSAN cluster] > Configure > vSAN > Fault Domains, select the "Secondary" site in the right pane and click the highlighted button as shown below to switch the data site roles.
.png)
vSAN Stretched Cluster And 2 Node (Without WTS) Failover Scenarios
In this section, we will look at how to inject various network failures in a vSAN Stretched Cluster configuration. We will see how the failure manifests itself in the cluster, focusing on the vSAN health check and the alarms/events as reported in the vSphere client.
Network failover scenarios for Stretched Cluster with or without Witness Traffic separation and ROBO with/without direct connect are the same because the Witness traffic is always connected via L3.
Scenario #1: Network Failure between Secondary Site and Witness host
.png)
vSAN Stretched Cluster (Without WTS) Network Failover Scenarios
In this section, we will look at how to inject various network failures in a vSAN Stretched Cluster configuration. We will see how the failure manifests itself in the cluster, focusing on the vSAN health check and the alarms/events as reported in the vSphere client.
Network failover scenarios for Stretched Cluster with or without Witness Traffic separation and ROBO with/without direct connect are the same because the Witness traffic is always connected via L3.
Scenario #1: Network Failure between Secondary Site and Witness host
(1).png)
Trigger the Event
To make the secondary site lose access to the witness site, one can simply remove the static route on the witness host that provides a path to the secondary site.
On secondary host(s), remove the static route to the witness host. For example:
esxcli network ip route ipv4 remove -g 192.168.201.162 -n 192.168.203.0/24
Cluster Behavior on Failure
In such a failure scenario, when the witness is isolated from one of the data sites, it implies that it cannot communicate to both the master node AND the backup node. In stretched clusters, the master node and the backup node are placed on different fault domains [sites]. This is the case in this failure scenario. Therefore the witness becomes isolated, and the nodes on the preferred and secondary sites remain in the cluster. Let's see how this bubbles up in the UI.
To begin with, the Cluster Summary view shows one configuration issue related to "Witness host found".
.png)
This same event is visible in the [vSAN Cluster] > Monitor > Issues and Alarms > All Issues view.
.png)
Note that this event may take some time to trigger. Next, looking at the health check alarms, a number of them get triggered.
.png)
On navigating to the [vSAN Cluster] > Monitor > vSAN > Health view, there are a lot of checks showing errors.
.png)
One final place to examine is virtual machines. Navigate to [vSAN cluster] > Monitor > vSAN > Virtual Objects > View Placement Details . It should show the witness absent from the secondary site perspective. However, virtual machines should still be running and fully accessible.
.png)
Returning to the health check, selecting Data > vSAN object health, you can see the error 'Reduced availability with no rebuild - delay timer'
.png)
Conclusion
The loss of the witness does not impact the running virtual machines on the secondary site. There is still a quorum of components available per object, available from the data sites. Since there is only a single witness host/site, and only three fault domains, there is no rebuilding/resyncing of objects.
Repair the Failure
Add back the static routes that were removed earlier, and rerun the health check tests. Verify that all tests are passing before proceeding. Remember to test one thing at a time.
Scenario #2: Network Failure between Preferred Site and Witness host
.png)
Trigger the Event
To make the preferred site lose access to the witness site, one can simply remove the static route on the witness host that provides a path to the preferred site.
On preferred host(s), remove the static route to the witness host. For example:
esxcli network ip route ipv4 remove –g 192.168.201.162 –n 192.168.203.0/24
Cluster Behavior on Failure
As per the previous test, this results in the same partitioning as before. The witness becomes isolated, and the nodes in both data sites remain in the cluster. It may take some time for alarms to trigger when this event occurs. However, the events are similar to those seen previously.
.png)
One can also see various health checks fail, and their associated alarms being raised.
.png)
Just like the previous test, the witness component goes absent.
.png)
.png)
This health check behavior appears whenever components go ‘absent’ and vSAN is waiting for the 60-minute clomd timer to expire before starting any rebuilds. If an administrator clicks on “Repair Objects Immediately”, the objects switch state and now the objects are no longer waiting on the timer and will start to rebuild immediately under general circumstances. However in this POC, with only three fault domains and no place to rebuild witness components, there is no syncing/rebuilding.
Conclusion
Just like the previous test, a witness failure has no impact on the running virtual machines on the preferred site. There is still a quorum of components available per object, as the data sites can still communicate. Since there is only a single witness host/site, and only three fault domains, there is no rebuilding/resyncing of objects.
Repair the Failure
Add back the static routes that were removed earlier, and rerun the health check tests. Verify that all tests are passing before proceeding. Remember to test one thing at a time.
Scenario #3: Network Failure from both Data sites to Witness host
.png)
Trigger the Event
To introduce a network failure between the preferred and secondary data sites and the witness site, we remove the static route on each preferred/secondary host to the Witness host. The same behavior can be achieved by shutting down the Witness Host temporarily.
On Preferred / Secondary host(s), remove the static route to the witness host. For example:
esxcli network ip route ipv4 remove -g 192.168.201.162 -n 192.168.203.0/24
Cluster Behavior on Failure
The events observed are for the most part identical to those observed in failure scenarios #1 and #2.
Conclusion
When the vSAN network fails between the witness site and both the data sites (as in the witness site fully losing its WAN access), it does not impact the running virtual machines. There is still a quorum of components available per object, available from the data sites. However, as explained previously, since there is only a single witness host/site, and only three fault domains, there is no rebuilding/resyncing of objects.
Repair the Failure
Add back the static routes that were removed earlier, and rerun the health check tests. Verify that all tests are passing. Remember to test one thing at a time.
Scenario #4: Network Failure (Data and Witness Traffic) in Secondary site
.png)
Trigger the Event
To introduce a network failure on the secondary data site we require to disable network flow on vSAN vmk1, as both vSAN data and witness traffic are served over this single VMkernel port.
Initially we created two Port groups but only place host 23/24 named "VLAN201-vSAN-Secondary", host 21/22 on the preferred site using "VLAN201-vSAN-Preferred".
1) On secondary host(s), remove the static route to the witness host. For example:
esxcli network ip route ipv4 remove –g 192.168.201.162 –n 192.168.203.0/24
During failure scenario, using the DVS (can be also standard vSwitch) capability, place the "active" Uplink 1 to "Unused" via "Teaming and failover" policy in the Portgroup "VLAN201-vSAN-Secondary":
.png)
Cluster Behavior on Failure
To begin with, the Cluster Summary view shows the "HA host status" error which is expected in vSAN as in our case vmk1 is used for HA.
.png)
All VMs from the secondary data site will be restarted via HA on the Preferred data site
.png)
vSAN Health Service will show errors, such as "vSAN cluster partition" which is expected as one full site was failed.
Verify on each host or via [vSAN cluster] -> VMs if all VMs were restarted on the preferred site. Adding the "Host" column will show if the VMs are now started on the preferred site.
.png)
.png)
Conclusion
When the vSAN network fails in one of the data sites, it does not impact the running virtual machines on the available data site because the quorum exists. VMs on the not available data site will be restarted via HA on the available data site. However, as explained previously, since there is only a single witness host/site, and only three fault domains, there is no rebuilding/resyncing of objects.
Note: DRS is set to "Partial Automatic" and if the "Uplink 1" is changed from "Unused" back to "Active" the VMs won't automatically be restarted on the secondary site again. DRS in "Fully Automated" mode will move the VMs via vMotion back to their recommended site as configured earlier via VM/Host Groups and Rules.
Repair the Failure
Change the Uplink 1 from "Unused" back to "Active" on the DVS Portgroup and verify that all tests are passing. Remember to test one thing at a time.
Scenario #5; Network Failure (Data and Witness Traffic) in Preferred site
.png)
Trigger the Event
To introduce a network failure on the preferred data site we require to disable network flow on vSAN vmk1. as both vSAN data and witness traffic are served over this single VMkernel port.
Initially, we created two Portgroups but only place host .23/.24 named "VLAN201-vSAN-Secondary", host .21/.22 on the preferred site using "VLAN201-vSAN-Preferred".
1) On preferred host(s), remove the static route to the witness host. For example:
esxcli network ip route ipv4 remove –g 192.168.201.162 –n 192.168.203.0/24
2) During failure scenario, using the DVS (can be also standard vSwitch) capability, place the "active" Uplink 1 to "Unused" via "Teaming and failover" policy in the Portgroup "VLAN201-vSAN-Preferred":
.png)
Cluster Behavior on Failure
To begin with, the Cluster Summary view shows the "HA host status" error which is expected in vSAN as in our case vmk1 is used for HA. Quorum is formed on the Secondary site with the
.png)
.png)
vSAN Health Service will show errors such as "vSAN cluster partition" which is expected as one full site was failed.
Verify on each host or via [vSAN cluster] -> VMs if all VMs were restarted on the secondary site. Adding the "Host" column will show if the VMs are now started on the secondary site.

Conclusion
When the vSAN network fails in one of the data sites, it does not impact the running virtual machines on the available data site because the quorum exists. VMs on the not available data site will be restarted via HA on the available data site. However, as explained previously, since there is only a single witness host/site, and only three fault domains, there is no rebuilding/resyncing of objects.
Note: DRS is set to "Partial Automatic" and if the "Uplink 1" is changed from "Unused" back to "Active" the VMs won't automatically be restarted on the secondary site again. DRS in "Fully Automated" mode will move the VMs via vMotion back to their recommended site as configured earlier via VM/Host Groups and Rules.
Repair the Failure
Change the Uplink 1 from "Unused" back to "Active" on the DVS Portgroup and verify that all tests are passing. Remember to test one thing at a time.
Scenario #6: Network Failure between both Data Sites but Witness Host still accessible
.png)
Trigger the Event
Link failure between preferred and secondary data sites simulates a datacenter link failure while Witness Traffic remains up and running (i.e. router/firewall are still accessible to reach the Witness host).
To trigger the failure scenario we can either disable the network link between both data centers physically or use the DVS traffic filter function in the POC. In this scenario, we require to have each link active and the static route(s) need to be intact.
Note: This IP filter functionality only exists in DVS. The use of IP filter is only practical with few hosts as separate rules need to be created between each source and destination hosts.
.png)
Create filter rule by using "ADD" for each host per site and in our 2+2+1 setup, four filter rules we create as followed, to simulate an IP flow disconnect between preferred and secondary sites:
.png)
Note: Verify the settings as highlighted above, especially the protocol is set to "any" to ensure no traffic of any kind is flowing between host .21/22 and .23/24.
Enable the newly created DVS filters:
.png)
Cluster Behavior on Failure
The events observed are similar and through the create IP filter policies we discover a cluster partition, which is expected. HA will restart all VMs from the secondary site to the preferred site.
.png)
VMs are restarted by HA on preferred site:
.png)
Conclusion
In the failure scenario, if the data link between data centers is disrupted, HA will start the VMs on the preferred site. There is still a quorum of components available per object, available from the data sites. However, as explained previously, since there is only a single witness host/site, and only three fault domains, there is no rebuilding/resyncing of objects.
Repair the Failure
Disable the DVS filter rules and rerun the health check tests. Verify that all tests are passing. Remember to test one thing at a time.
vSAN Stretched Cluster Configuration (With WTS)
Starting with vSphere 6.7, a number of new vSAN features were included. One of the features expands the vSAN Stretched Cluster configuration by adding the Witness traffic separation functionality.
A good working knowledge of how vSAN Stretched Cluster is designed and architected is assumed. Readers unfamiliar with the basics of vSAN Stretched Cluster are urged to review the relevant documentation before proceeding with this part of the proof-of-concept. Details on how to configure a vSAN Stretched Cluster are found in the vSAN Stretched Cluster Guide .
Stretched Cluster Network Topology
As per the vSAN Stretched Cluster Guide, a number of different network topologies are supported for vSAN Stretched Cluster.
The network topology deployed in this lab environment for our POC test case is layer 2 between the vSAN data sites and L3 between data sites and witness. ESXi hosts and vCenter are in the same L2 subnet for this setup. The VM network should be a stretched L2 between both data sites as the unique IP used by the VM can remain unchanged in a failure scenario.
With WTS, we leave Management vmk0 and vSAN enabled vmk1 unchanged, while adding vmk2 to all hosts on data sites to isolate witness traffic on vmk2. In vSAN ROBO with WTS, vmk0 is used for Witness Traffic and vmk1 for vSAN Data in a direct connect scenario.
Stretched Cluster Hosts with WTS
There are four ESXi hosts in this cluster, two ESXi hosts on data site A (the “preferred” site) and two hosts on data site B (the “secondary” site). There is one disk group per host. The witness host/appliance is deployed in a 3 rd , remote data center. The configuration is referred to as 2+2+1.
.png)
.png)
VMs are deployed on both the “Preferred” and “Secondary” sites of the vSAN Stretched Cluster. VMs are running/active on both sites.
vSAN Stretched Cluster With WTS Diagram
Below is a diagram detailing the POC environment used for the Stretched Cluster testing with L2 across Preferred and Secondary data sites. vmk2 is added to expand the functionality for WTS.
.png)
- This configuration uses L2 across data sites for vSAN data traffic, host management and VM traffic. L3 IP routing is implemented between the witness site and the two data sites.
- Static routes are required to enable communication between data sites and witness appliance.
- The vSAN data network VLAN for the ESXi hosts on the preferred and secondary sites is VLAN 201 in pure L2 configuration
- The vSAN network VLAN for the witness host on the witness site is VLAN 203. The gateway is 192.168 203.162
- The WTS uses VLAN205, L3 routed to Witness Host.
- The VM network is stretched L2 between the data sites. This is VLAN 106. Since no production VMs are run on the witness, there is no need to extend this network to the third site.
Preferred / Secondary Site Details
In vSAN Stretched Clusters, “preferred” site simply means the site that the witness will ‘bind’ to in the event of an inter-site link failure between the data sites. Thus, this will be the site with the majority of VM components, so this will also be the site where all VMs will run when there is an inter-site link failure between data sites.
In this example, vSAN traffic is enabled on vmk1 on the hosts on the preferred site, which is using VLAN 201. For our failure scenarios, we create two DVS port groups and add the appropriate vmkernel port to each port group to test the failover behavior in a later stage.
.png)
vmk2 is configured as a VMkernel port without any services assigned and will be tagged for witness traffic using command line. Only vmk1 for vSAN Data Traffic is tagged for vSAN.
.png)
Commands to configured vmk port for WTS
The command to tag a VMkernel port for WTS is as follows:
esxcli vsan network ipv4 add -i vmkX -T=witness
To tag vmk2 for WTS on each of the POC hosts .21-24:
esxcli vsan network ipv4 add -i vmk2 -T=witness
Upon successful execution of the command, vSAN Witness traffic should be tagged for vmk2 in the UI as shown below.
.png)
Static routes need to be manually configured on these hosts. This is because the default gateway is on the management network, and if the preferred site hosts tried to communicate to the secondary site hosts, the traffic would be routed via the default gateway and thus via the management network. Since the management network and the vSAN network are entirely isolated, there would be no route.
L3 routing between vSAN data sites and Witness host requires an additional static route. While default gateway is used for the Management Network on vmk0, vmk2 has no knowledge of subnet 192.168.203.0, which needs to be added manually.
.png)
Commands to Add Static Routes
The following command is used to add static routes is as follows:
esxcli network ip route ipv4 add -g LOCAL-GATEWAY -n REMOTE-NETWORK
To add a static route from a preferred host to the witness host in this POC:
esxcli network ip route ipv4 add -g 192.168.205.162 -n 192.168.203.0/24
Note : Prior to vSAN version 6.6 , multicast is required between the data sites but not to the witness site. If L3 is used between the data sites, multicast routing is also required. With the advent of vSAN 6.6, multicast is no longer needed.
Witness Site details
The witness site only contains a single host for the Stretched Cluster, and the only VM objects stored on this host are “witness” objects. No data components are stored on the witness host. In this POC, we are using the witness appliance, which is an “ESXi host running in a VM”. If you wish to use the witness appliance, it should be downloaded from VMware. This is because it is preconfigured with various settings, and also comes with a preinstalled license. Note that this download requires a login to My VMware.
Alternatively, customers can use a physical ESXi host for the witness.
While two VMkernel adapters can be deployed on the Witness Appliance (vmk0 for Management and vmk1 for vSAN traffic), it is also supported to tag both vSAN and Management traffic on a single VMkernel adapter (vmk0), as we use in this case, vSAN traffic would need to be disabled on vmk1, since only one vmk has vSAN traffic enabled.
Note: In our PoC example we add a manual route for completeness and it is not required if the default gateway can reach the Witness separation subnet on the host data sites.
.png)
.png)
Once again, static routes should be manually configured on vSAN vmk0 to route to “Preferred site” and “Secondary Site" Witness Traffic (VLAN 205). The image below shows the witness host routing table with static routes to remote sites.
.png)
Commands to Add Static Routes
The following command to add static routes is as follows:
esxcli network ip route ipv4 add -g LOCAL-GATEWAY -n REMOTE-NETWORK
To add a static route from the witness host to hosts on the preferred and secondary sites in this POC:
esxcli network ip route ipv4 add -g 192.168.203.162 -n 192.168.205.0/24
Note: Witness Appliance is a nested ESXi host and requires the same treatment as a standard ESXi host (i.e, patch updates). Keep all ESXi hosts in a vSAN cluster at the same update level, including the Witness appliance.
To confirm if the new static route and gateway function properly to reach the Witness host subnet 192.168.203.0/24 via vmk2, navigate to vSAN Health service and verify that all tests show “green” status. .png)
Witness Traffic Separation is established and this type of traffic can communicate between VLAN 205 and VLAN 203. Only VLAN 201 serves vSAN data IO traffic across both data sites.
vSphere HA Settings
vSphere HA plays a critical part in Stretched Cluster. HA is required to restart virtual machines on other hosts and even the other site depending on the different failures that may occur in the cluster. The following section covers the recommended settings for vSphere HA when configuring it in a Stretched Cluster environment.
Response to Host Isolation
The recommendation is to “Power off and restart VMs” on isolation, as shown below. In cases where the virtual machine can no longer access the majority of its object components, it may not be possible to shut down the guest OS running in the virtual machine. Therefore, the “Power off and restart VMs” option is recommended.
.png)
Admission Control
If a full site fails, the desire is to have all virtual machines run on the remaining site. To allow a single data site to run all virtual machines if the other data site fails, the recommendation is to set Admission Control to 50% for CPU and Memory as shown below.
.png)
Advanced Settings
The default isolation address uses the default gateway of the management network. This will not be useful in a vSAN Stretched Cluster, when the vSAN network is broken. Therefore the default isolation response address should be turned off. This is done via the advanced setting das.usedefaultisolationaddress to false.
To deal with failures occurring on the vSAN network, VMware recommends setting at least one isolation address, which is local to each of the data sites. In this POC, we only use Stretched L2 on VLAN 201, which is reachable from the hosts on the preferred and secondary sites. Use advanced settings das.isolationaddress0 to set the isolation address for the IP gateway address to reach the witness host.
.png)
- Since 6.5 there is no need for VM anti-affinity rules or VM to host affinity rules in HA
These advanced settings are added in the Advanced Options > Configuration Parameter section of the vSphere HA UI. The other advanced settings get filled in automatically based on additional configuration steps. There is no need to add them manually.
VM Host Affinity Groups
The next step is to configure VM/Host affinity groups. This allows administrators to automatically place a virtual machine on a particular site when it is powered on. In the event of a failure, the virtual machine will remain on the same site, but placed on a different host. The virtual machine will be restarted on the remote site only when there is a catastrophic failure or a significant resource shortage.
To configure VM/Host affinity groups, the first step is to add hosts to the host groups. In this example, the Host Groups are named Preferred and Secondary, as shown below.
.png)
.png)
The next step is to add the virtual machines to the host groups. Note that these virtual machines must be created in advance.
.png)
Note that these VM/Host affinity rules are “should” rules and not “must” rules. “Should” rules mean that every attempt will be made to adhere to the affinity rules. However, if this is not possible (due lack of resources), the other site will be used for hosting the virtual machine.
Also, note that the vSphere HA rule setting is set to “should”. This means that if there is a catastrophic failure on the site to which the VM has an affinity, HA will restart the virtual machine on the other site. If this was a “must” rule, HA would not start the VM on the other site.
.png)
The same settings are necessary on both the primary VM/Host group and the secondary VM/Host group.
DRS Settings
In this POC, the partially automated mode has been chosen. However, this could be set to Fully Automated if customers wish but note that it should be changed back to partially automated when a full site failure occurs. This is to avoid failback of VMs occurring while rebuild activity is still taking place. More on this later.
.png)
vSAN Stretched Cluster Local Failure Protection
In vSAN 6.6, we build on resiliency by including local failure protection, which provides storage redundancy within each site and across sites. Local failure protection is achieved by implementing local RAID-1 mirroring or RAID-5/6 erasure coding within each site. This means that we can protect the objects against failures within a site, for example, if there is a host failure on site 1, vSAN can self-heal within site 1 without having to go to site 2 if properly configured.

Local Failure Protection in vSAN 6.6 is configured and managed through a storage policy in the vSphere Web Client. The figure below shows rules in a storage policy that is part of an all-flash stretched cluster configuration. The "Site disaster tolerance" is set to Dual site mirroring (stretched cluster) , which instructs vSAN to mirror data across the two main sites of the stretched cluster. The "Failures to tolerate" specifies how data is protected within the site. In the example storage policy below, 1 failiure - RAID-5 (Erasure Coding) is used, which can tolerate the loss of a host within the site.
.png)
Local failure protection within a stretched cluster further improves the resiliency of the cluster to minimize unplanned downtime. This feature also reduces or eliminates cross-site traffic in cases where components need to be resynchronized or rebuilt. vSAN lowers the total cost of ownership of a stretched cluster solution as there is no need to purchase additional hardware or software to achieve this level of resiliency.
vSAN Stretched Cluster Site Affinity
New in vSAN 6.6 flexibility improvements of storage policy-based management for stretched clusters have been made by introducing the “Affinity” rule. You can specify a single site to locate VM objects in cases where cross-site redundancy is not necessary. Common examples include applications that have built-in replication or redundancy such as Microsoft Active Directory and Oracle Real Application Clusters (RAC). This capability reduces costs by minimizing the storage and network resources used by these workloads.
Site affinity is easy to configure and manage using storage policy-based management. A storage policy is created and the Affinity rule is added to specify the site where a VM’s objects will be stored using one of these "Failures to tolerate" options: None - keep data on Preferred (stretched cluster) or None - keep data on Non-preferred (stretched cluster) .
.png)
vSAN Stretched Cluster Preferred Site Override
Preferred and secondary sites are defined during cluster creation. If it is desired to switch the roles between the two data sites, you can navigate to [vSAN cluster] > Configure > vSAN > Fault Domains, select the "Secondary" site in the right pane and click the highlighted button as shown below to switch the data site roles.
.png)
vSAN Stretched Cluster with WTS Failover Scenarios
In this section, we will look at how to inject various network failures in a vSAN Stretched Cluster configuration. We will see how the failure manifests itself in the cluster, focusing on the vSAN health check and the alarms/events as reported in the vSphere client.
Network failover scenarios for Stretched Cluster with or without Witness Traffic separation and ROBO with/without direct connect are the same because the Witness traffic is always connected via L3.
Scenario #1: Network Failure between Secondary Site and Witness host
.png)
Trigger the Event
To make the secondary host lose access to the witness site, remove the static route on the ESXi host, which provides the IP path to the secondary site.
On secondary host(s), remove the static route to the witness host. For example:
esxcli network ip route ipv4 remove -g 192.168.201.162 -n 192.168.203.0/24
Cluster Behavior on Failure
In such a failure scenario, when the witness is isolated from one of the data sites, it implies that it cannot communicate to both the master node AND the backup node. In stretched clusters, the master node and the backup node are placed on different fault domains [sites]. This is the case in this failure scenario. Therefore the witness becomes isolated, and the nodes on the preferred and secondary sites remain in the cluster. Let's see how this bubbles up in the UI.
To begin with, the Cluster Summary view shows one configuration issue related to "Witness host found".
.png)
This same event is visible in the [vSAN Cluster] > Monitor > Issues and Alarms > All Issues view.
.png)
Note that this event may take some time to trigger. Next, looking at the health check alarms, a number of them get triggered.
.png)
On navigating to the [vSAN Cluster] > Monitor > vSAN > Health view, there are a lot of checks showing errors.
(1).png)
One final place to examine is virtual machines. Navigate to [vSAN cluster] > Monitor > vSAN > Virtual Objects > View Placement Details . It should show the witness absent from the secondary site perspective. However, virtual machines should still be running and fully accessible.
.png)
Returning to the health check, selecting Data > vSAN object health, you can see the error 'Reduced availability with no rebuild - delay timer'
.png)
Conclusion
The loss of the witness does not impact the running virtual machines on the secondary site. There is still a quorum of components available per object, available from the data sites. Since there is only a single witness host/site, and only three fault domains, there is no rebuilding/resyncing of objects.
Repair the Failure
Add back the static routes that were removed earlier, and rerun the health check tests. Verify that all tests are passing before proceeding. Remember to test one thing at a time.
Scenario #2: Network Failure between Preferred Site and Witness host
.png)
Trigger the Event
To make the preferred site lose access to the witness site, one can simply remove the static route on the witness host that provides a path to the preferred site.
On preferred host(s), remove the static route to the witness host. For example:
esxcli network ip route ipv4 remove –g 192.168.201.162 –n 192.168.203.0/24
Cluster Behavior on Failure
As per the previous test, this results in the same partitioning as before. The witness becomes isolated, and the nodes in both data sites remain in the cluster. It may take some time for alarms to trigger when this event occurs. However, the events are similar to those seen previously.
.png)
One can also see various health checks fail, and their associated alarms being raised.
(1).png)
Just like the previous test, the witness component goes absent.
(1).png)
.png)
This health check behavior appears whenever components go ‘absent’ and vSAN is waiting for the 60-minute clomd timer to expire before starting any rebuilds. If an administrator clicks on “Repair Objects Immediately”, the objects switch state and now the objects are no longer waiting on the timer and will start to rebuild immediately under general circumstances. However in this POC, with only three fault domains and no place to rebuild witness components, there is no syncing/rebuilding.
Conclusion
Just like the previous test, a witness failure has no impact on the running virtual machines on the preferred site. There is still a quorum of components available per object, as the data sites can still communicate. Since there is only a single witness host/site, and only three fault domains, there is no rebuilding/resyncing of objects.
Repair the Failure
Add back the static routes that were removed earlier, and rerun the health check tests. Verify that all tests are passing before proceeding. Remember to test one thing at a time.
Scenario #3: Network Failure from both Data sites to Witness host
.png)
Trigger the Event
To introduce a network failure between the preferred and secondary data sites and the witness site, we remove the static route on each preferred/secondary host to the Witness host. The same behavior can be achieved by shutting down the Witness Host temporarily.
On Preferred / Secondary host(s), remove the static route to the witness host. For example:
esxcli network ip route ipv4 remove -g 192.168.201.162 -n 192.168.203.0/24
Cluster Behavior on Failure
The events observed are for the most part identical to those observed in failure scenarios #1 and #2.
Conclusion
When the vSAN network fails between the witness site and both the data sites (as in the witness site fully losing its WAN access), it does not impact the running virtual machines. There is still a quorum of components available per object, available from the data sites. However, as explained previously, since there is only a single witness host/site, and only three fault domains, there is no rebuilding/resyncing of objects.
Repair the Failure
Add back the static routes that were removed earlier, and rerun the health check tests. Verify that all tests are passing. Remember to test one thing at a time.
Scenario #4: Network Failure (Data and Witness Traffic) in Secondary site
.png)
Trigger the Event
To introduce a network failure on the secondary data site we require to disable network flow on vSAN vmk1. as both vSAN data and witness traffic are served over this single VMkernel port.
Initially we created two Port groups but only place host 23/24 named "VLAN201-vSAN-Secondary", host 21/22 on the preferred site using "VLAN201-vSAN-Preferred".
1) On secondary host(s), remove the static route to the witness host. For example:
esxcli network ip route ipv4 remove –g 192.168.201.162 –n 192.168.203.0/24
2) During failure scenario, using the DVS (can be also standard vSwitch) capability, place the "active" Uplink 1 to "Unused" via "Teaming and failover" policy in the Portgroup "VLAN201-vSAN-Secondary":
.png)
Cluster Behavior on Failure
To begin with, the Cluster Summary view shows the "HA host status" error which is expected in vSAN as in our case vmk1 is used for HA.
.png)
All VMs from the secondary data site will be restarted via HA on the Preferred data site
.png)
vSAN Health Service will show errors, such as "vSAN cluster partition" which is expected as one full site was failed.
Verify on each host or via [vSAN cluster] -> VMs if all VMs were restarted on the preferred site. Adding the "Host" column will show if the VMs are now started on the preferred site.
.png)
.png)
Conclusion
When the vSAN network fails in one of the data sites, it does not impact the running virtual machines on the available data site because the quorum exists. VMs on the not available data site will be restarted via HA on the available data site. However, as explained previously, since there is only a single witness host/site, and only three fault domains, there is no rebuilding/resyncing of objects.
Note: DRS is set to "Partial Automatic" and if the "Uplink 1" is changed from "Unused" back to "Active" the VMs won't automatically be restarted on the secondary site again. DRS in "Fully Automated" mode will move the VMs via vMotion back to their recommended site as configured earlier via VM/Host Groups and Rules.
Repair the Failure
Change the Uplink 1 from "Unused" back to "Active" on the DVS Portgroup and verify that all tests are passing. Remember to test one thing at a time.
Scenario #5: Network Failure (Data and Witness Traffic) in Preferred site
.png)
Trigger the Event
To introduce a network failure on the preferred data site we require to disable network flow on vSAN vmk. as both vSAN data and witness traffic are serviced over this single vmk kernel port.
Initially, we created two Port groups but only place host .23/.24 named "VLAN201-vSAN-Secondary", host .21/.22 on the preferred site using "VLAN201-vSAN-Preferred".
1) On preferred host(s), remove the static route to the witness host. For example:
esxcli network ip route ipv4 remove –g 192.168.201.162 –n 192.168.203.0/24
2) During failure scenario, using the DVS (can be also standard vSwitch) capability, place the "active" Uplink 1 to "Unused" via "Teaming and failover" policy in the Portgroup "VLAN201-vSAN-Preferred":
.png)
Cluster Behavior on Failure
To begin with, the Cluster Summary view shows the "HA host status" error which is expected in vSAN as in our case vmk1 is used for HA. Quorum is formed on the Secondary site with the
.png)
.png)
vSAN Health Service will show errors, such as "vSAN cluster partition" which is expected as one full site was failed.
Verify on each host or via [vSAN cluster] -> VMs if all VMs were restarted on the secondary site. Adding the "Host" column to show if the VMs are now started on the secondary site.
.png)
Conclusion
When the vSAN network fails in one of the data sites, it does not impact the running virtual machines on the available data site because the quorum exists. VMs on the not available data site will be restarted via HA on the available data site. However, as explained previously, since there is only a single witness host/site, and only three fault domains, there is no rebuilding/resyncing of objects.
Note: DRS is set to "Partial Automatic" and if the "Uplink 1" is changed from "Unused" back to "Active" the VMs won't automatically be restarted on the secondary site again. DRS in "Fully Automated" mode will move the VMs via vMotion back to their recommended site as configured earlier via VM/Host Groups and Rules.
Repair the Failure
Change the Uplink 1 from "Unused" back to "Active" on the DVS Portgroup and verify that all tests are passing. Remember to test one thing at a time.
Scenario #6: Network Failure between both Data Sites, Witness host accessible via WTS
.png)
Trigger the Event
Link failure between preferred and secondary data sites simulates a datacenter link failure while Witness Traffic remains up and running (i.e. router/firewall are still accessible to reach the Witness host).
To trigger the failure scenario we can either disable the network link between both data centers physically or use the DVS traffic filter function in the POC. In this scenario, we require to have each link active and the static route(s) need to be intact.
Note: This IP filter functionality only exists in DVS. The use of IP filter is only practical with few hosts as separate rules need to be created between each source and destination hosts.
.png)
Create filter rule by using "ADD" for each host per site and in our 2+2+1 setup, four filter rules we create as followed, to simulate an IP flow disconnect between preferred and secondary sites:
.png)
Note: Verify the settings as highlighted above, especially the protocol is set to "any" to ensure no traffic of any kind is flowing between host .21/22 and .23/24.
Enable the newly created DVS filters:
.png)
Cluster Behavior on Failure
The events observed are similar and through the create IP filter policies we discover a cluster partition, which is expected. HA will restart all VMs from the secondary site to the preferred site.
.png)
VMs are restarted by HA on preferred site:
.png)
Conclusion
In the failure scenario, if the data link between data centers is disrupted, HA will start the VMs on the preferred site. There is still a quorum of components available per object, available from the data sites. However, as explained previously, since there is only a single witness host/site, and only three fault domains, there is no rebuilding/resyncing of objects.
Repair the Failure
Disable the DVS filter rules and rerun the health check tests. Verify that all tests are passing. Remember to test one thing at a time.
vSAN All-Flash Features
Deduplication And Compression
Two major features unique to all-flash clusters are:
- Deduplication and compression
- RAID-5/RAID-6 Erasure Coding
Deduplication and compression is available for space efficiency while RAID-5/RAID-6 Erasure Coding provides additional data protection options that require less space than the traditional RAID-1 options.
Deduplication and Compression
Deduplication and Compression are enabled together in vSAN and applied directly at the cluster-level. The scope of deduplication and compression applies to an individual disk group in order to ensure the greatest availability of the vSAN datastore. When data is destaged from the cache tier, vSAN checks to see if a match for that block exists. If the block exists, vSAN does not write an additional copy of the block nor does it go through the compression process. However, if the block does not exist, vSAN will attempt to compress the block. The compression algorithm will try to compress the size of the block to 2KB or less. If the algorithm is able to be applied, the compressed block is then written to the capacity tier. If the compression algorithm cannot compress the block to 2KB or less than the full 4KB block is written to the capacity tier.
To demonstrate the effects of Deduplication and Compression, this exercise displays the capacity before and after deploying eight identical virtual machines. Before starting this exercise, ensure that Deduplication and Compression is enabled. When enabling the Deduplication and Compression features, vSAN will go through the rolling update process where data is evacuated from each disk group and the disk group is reconfigured with the features enabled. Depending on the number of disk groups on each host and the amount of data, this can be a lengthy process. To enable Deduplication and Compression complete the following steps:
- Navigate to [vSAN Cluster] > Configure > vSAN > Services .
- Select the top EDIT button that corresponds to the Deduplication and compression service.

- Toggle Deduplication and Compression and select APPLY .

Once the process of enabling Deduplication and Compression is complete, the eight virtual machines can then be created. However, before creating the virtual machines, examine the capacity consumed by selecting [vSAN Cluster] > Monitor > vSAN > Capacity to look at the capacity summary.
.png)
Focus on the Deduplication and Compression Overview section, which shows a used capacity of 634.09 GB prior to deduplication and compression and after deduplication and compression a used capacity of 198.06GB. From the baseline, we show a 3.2x savings already due to deduplication and compression on system metadata.
For the next part of the exercise, we will create eight clones from a Windows 2012R2 VM, each with a single 100 GB Thin Provisioned VMDK. The following graphic shows the exact configuration for each VM.

After creating 8 virtual machines each with 100GB disk, check the total capacity consumption for the vSAN datastore. The Deduplication and Compression Overview shows a used capacity before of 1015.48GB and after deduplication and compression a used capacity of 370.61GB, a result of 2.74x savings. Your rate will vary depending on the placement of similar components in vSAN disk groups.

RAID-5/RAID-6 Erasure Coding
In versions of vSAN prior to 6.2, objects could only be deployed using a RAID-1 (mirroring) configuration while version 6.2 introduced RAID-5/6 Erasure Coding. The key benefit of using erasure coding is space efficiency. Instead of 2x or 3x overhead (FTT = 1 or 2) in the traditional RAID-1 configuration to withstand multiple failures, RAID-5 requires only 33% additional storage, and RAID-6 requires only 50% additional overhead.
In order to support RAID-5 and RAID-6, the following host requirements must be met:
- RAID-5 works in a 3+1 configuration meaning 3 data blocks and 1 parity block per stripe. To use a RAID-5 protection level the vSAN cluster must contain a minimum of 4 hosts.
- RAID-6 works in a 4+2 configuration meaning 4 data blocks and 2 parity blocks per stripe. To enable a RAID-6 protection level the vSAN cluster must contain a minimum of 6 hosts.
- RAID-5/6 Erasure Coding levels are made available via Storage Policy-Based Management (SPBM). In the following exercise, we will enable RAID-5 by creating a new storage policy and applying that storage policy to a virtual machine.
To begin the process for setting up RAID-5 OR RAID-6, open the VM Storage Policies window in vCenter ( Menu > Policies and Profiles > VM Storage Policies ). Create a new storage policy for RAID-5 by completing the following steps:
- Click the Create VM Storage Policy icon to create a new VM storage policy.
- Provide a name for the new policy and click NEXT. For this example, the name of "RAID-5 Policy" is used.
- Read about storage policy structure, select Enable rules for "vSAN" storage, then click NEXT again.

- When prompted for vSAN availability options, choose 1 failure - RAID-5 (Erase Coding) from the Failures to tolerate drop-down menu. Click NEXT to proceed.

- Verify the vSAN datastore is shown from the storage compatibility list and click NEXT .
- When the rule is complete the summary should be similar to the following graphic. Click FINISH to create the policy.

Once storage policy for RAID-5 has been created, the next step is to create a virtual machine using that policy. For this example, create a virtual machine containing a single 100 GB drive. During the VM creation process select the "RAID-5 Policy" policy. Upon completion, the VM summary should be similar to the following.

Now that the virtual machine has been created, you can view the physical disk placement of the components. For this example, the VMDK object will be comprised of 4 components spread across different hosts in the cluster.

vSAN Encryption
vSAN encryption overview, requirements, enabling encryption and expected behavior
vSAN Encryption Requirements
Encryption for data at rest is now available on vSAN 6.6. This feature does not require self-encrypting drives (SEDs)* and utilizes an AES 256 cipher. Encryption is supported on both all-flash and hybrid configurations of vSAN.
*Self-encrypting drives (SEDs) are not required. Some drives on the vSAN Compatibility Guide may have SED capabilities, but the use of those SED capabilities are not supported.
vSAN datastore encryption is enabled and configured at the datastore level. In other words, every object on the vSAN datastore is encrypted when this feature is enabled. Data is encrypted when it is written to persistent media in both the cache and capacity tiers of a vSAN datastore. Encryption occurs just above the device driver layer of the storage stack, which means it is compatible with all vSAN features such as deduplication and compression, RAID-5/6 erasure coding, and stretched cluster configurations among others. All vSphere features including VMware vSphere vMotion®, VMware vSphere Distributed Resource Scheduler™ (DRS), VMware vSphere High Availability (HA), and VMware vSphere Replication™ are supported. A Key Management Server (KMS) is required to enable and use vSAN encryption. Nearly all KMIP-compliant KMS vendors are compatible, with specific testing completed for vendors such as HyTrust®, Gemalto® (previously Safenet), Thales e-Security®, CloudLink®, and Vormetric®. These solutions are commonly deployed in clusters of hardware appliances or virtual appliances for redundancy and high availability.
Requirements for vSAN Encryption:
- Deploy KMS cluster/server of your choice
- Add/trust KMS server to vCenter UI
- vSAN encryption requires on-disk format version 5
- If the current on-disk format is below version 5, a rolling on-disk upgrade will need to be completed prior to enabling encryption
- When vSAN encryption is enabled, all disks are reformatted
- This is achieved in a rolling manner
Adding KMS to vCenter
Given the multitude of KMS vendors, the setup and configuration of a KMS server/cluster is not part of this document; however, it is a pre-requisite prior to enabling vSAN encryption.
The initial configuration of the KMS server is done in the VMware vCenter Server® user interface of the vSphere Client. The KMS cluster is added to the vCenter Server and a trust relationship is established. The process for doing this is vendor-specific, so please consult your KMS vendor documentation prior to adding the KMS cluster to vCenter.
To add the KMS cluster to vCenter in the vSphere Client, click on the vCenter server, click on Configure > Key Management Servers > ADD. Enter the information for your specific KMS cluster/server.
 Figure 1. Add KMS cluster to vCenter
Figure 1. Add KMS cluster to vCenter
Once the KMS cluster/server has been added, you will need to establish trust with the KMS server. Follow the instructions from your KMS vendor as they differ from vendor to vendor.
 Figure 2. Establish trust with KMS
Figure 2. Establish trust with KMS
After the KMS has been properly configured, you will see that the connections status and the certificate have green checks, meaning we are ready to move forward with enabling vSAN encryption.

Figure 3. Successful connection and certificate status.
Enabling vSAN Encryption
Prior to enabling vSAN encryption, all of the following pre-requisites must be met:
- Deploy KMS cluster/server of your choice
- Add/trust KMS server to vCenter UI
- vSAN encryption requires on-disk format version 5
- When vSAN encryption is enabled all disks are reformatted
To enable vSAN encryption, click on [vSAN cluster] > Configure > vSAN > Services , and click EDIT next to the "Encryption" service. Here we have the option to erase all disks before use. This will increase the time it will take to do the rolling format of the devices, but it will provide better protection.
Note: vSAN encryption does work with Deduplication and Compression.
 Figure 1. Enabling vSAN encryption
Figure 1. Enabling vSAN encryption
After you click APPLY, vSAN will remove one disk group at a time, format each device, and recreate the disk group once the format has completed. It will then move on to the next disk group until all disk groups are recreated, and all devices formatted and encrypted. During this period, data will be evacuated from the disk groups, so you will see components resyncing.
 Figure 2. Disk group removal, disk format, disk group creation
Figure 2. Disk group removal, disk format, disk group creation
Note: This process can take quite some time depending on the amount of data that needs to be migrated during the rolling reformat. If you know encryption at rest is a requirement, go ahead and enable encryption while enabling vSAN.
Disabling vSAN Encryption
Disabling vSAN encryption follows a similar procedure as its enablement. Since the encryption is done at the disk group level, a disk reformat will also be conducted while disabling encryption.
Keep in mind that vSAN will conduct a rolling reformat of the devices by evacuating the disk groups first, deleting the disk group and re-creating the disk group without encryption, at which point it will be ready to host data. The same process is conducted on all remainder disk groups until the vSAN datastore is no longer encrypted.
Since the disk groups are evacuated, all data will be moved within the disk groups, so it may take a considerable amount of time depending on the amount of data present on the vSAN datastore.
vSAN Encryption Rekey
You have the capability of generating new keys for encryption. There are 2 modes for rekeying. One of them is a high level rekey where the data encryption key is wrapped by a new key-encryption key. The other level is a complete re-encryption of all data by selecting the option Also re-encrypt all data on the storage using the new keys. This second rekey (deep rekey) may take significant time to complete as all the data will have to be re-written, and may decrease performance.
Note: It is not possible to specify a different KMS server when selecting to generate new keys during a deep rekey; however, this option is available during a shallow rekey.
 Figure 1. Generate New Encryption Keys
Figure 1. Generate New Encryption Keys
Cloud Native Storage
Cloud Native Storage Overview
Cloud Native Storage (CNS), introduced in vSphere 6.7 U3, offers a platform for stateful cloud native applications to persist state on vSphere backed storage. The platform allows users to deploy and manage containerized applications using cloud native constructs such as Kubernetes persistent volume claims and maps these to native vSphere constructs such as storage policies. CNS integrates with vSphere workflows and offers the ability for administrators to perform tasks such as defining storage policies that could be mapped to storage classes, list/search and monitor health and capacity for persistent volumes (PV). vSphere 6.7 U3 supports PVs backed by block volumes on vSAN as well as VMFS and NFS datastores. However, some of the monitoring and policy-based management support may be limited to vSAN deployments only.
Cloud Native Storage Prerequisites
While Cloud Native Storage is a vSphere built-in feature that is enabled out-of-the-box, it is required to install the Container Storage Interface (CSI) driver in Kubernetes to take advantage of the CNS feature. CSI is a standardized API for container orchestrators to manage storage plugins and its implementation becomes GA in the Kubernetes v1.13 release. Configuration procedure of CSI driver in Kubernetes is beyond the scope of this guide. To learn more about the installation of the CSI driver, refer to the vSphere CSI driver documentation.
Deploy a Persistent Volume for Container
Assuming your Kubernetes cluster has been deployed in the vSAN cluster and the CSI driver has been installed, you are ready to check out the Cloud Native Storage functionality.
First, we need to create a yaml file like below to define a storage class in Kubernetes. Notice the storage class name is “cns-test-sc” and it is associated with the vSAN Default Storage Policy. Note also that the “provisioner” attribute specifies that the storage objects are to be created using the CSI driver for vSphere block service.
kind: StorageClass
apiVersion: storage.k8s.io/v1
metadata:
name: cns-test-sc
provisioner: block.vsphere.csi.vmware.com
parameters:
StoragePolicyName: "vSAN Default Storage Policy"
Apply the storage class by executing the following command on your Kubernetes master node:
kubectl apply -f cns-test-sc.yaml
Run the command below to confirm the storage class has been created.
kubectl get storageclass cns-test-sc
NAME PROVISIONER AGE
cns-test-sc block.vsphere.csi.vmware.com 20s
Next, we need to create another yaml file like below to define a Persistent Volume Claim (PVC). For the illustration purpose of this POC, we simply create a persistent volume without attaching it to an application. Notice “storageClassName” references to the storage class that was created earlier. There are two labels assigned to this PVC: app and release. We will see later how they get propagated to CNS in the vSphere Client UI.
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: cns-test-pvc
labels:
app: cns-test
release: cns-test
spec:
storageClassName: cns-test-sc
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 2Gi
Create the PVC by executing the following command on your Kubernetes master node:
kubectl apply -f cns-test-pvc.yaml
Run the command below to confirm the PVC has been created and its status is listed as “Bound”.
kubectl get pvc cns-test-pvc
NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGE
cns-test-pvc Bound pvc-ebc2e95c-b98f-11e9-808d-005056bd960e 2Gi RWO cns-test-sc 15s
To examine what container volume has been created in vSphere Client UI, navigate to [vSAN cluster] > Monitor > Cloud Native Storage > Container Volumes. You should see a container volume with a name that matches the output from the “get pvc” command. The two labels (app and release) correspond to those that are specified in the PVC yaml file. These labels allow Kubernetes admin and vSphere admin to refer to a common set of volume attributes that makes troubleshooting easier. If there are many container volumes created in the cluster, you could select the filter icon for the “Label” column and search the container volumes by multiple label names that quickly narrow down the list of volumes that needs to be investigated.

To drill down into a particular volume under investigation, you could select the icon and obtain more information such as Kubernetes cluster name, PVC name, namespace, and other storage properties from vSphere perspective.
and obtain more information such as Kubernetes cluster name, PVC name, namespace, and other storage properties from vSphere perspective.

If you want to look into the overall usage of all container volumes in the cluster, navigate to [vSAN cluster] > Monitor > vSAN > Capacity. The Capacity view breaks down the storage usage at a granular level of container volumes that are either attached or not attached to a VM.

This concludes the Cloud Native Storage section of the POC. You may delete the PVC “cns-test-pvc” from Kubernetes and verify that its container volume is removed from the vSphere Client UI.